

Learning reward timing in cortex through reward dependent expression of synaptic plasticity
- PMID: 19346478
- PMCID: PMC2672535
- DOI: 10.1073/pnas.0901835106
Learning reward timing in cortex through reward dependent expression of synaptic plasticity
Abstract
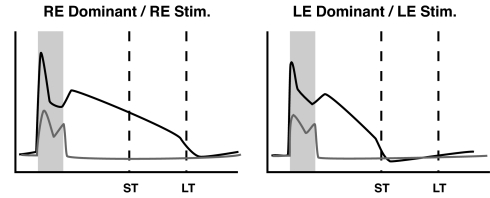
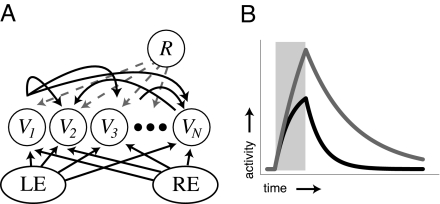
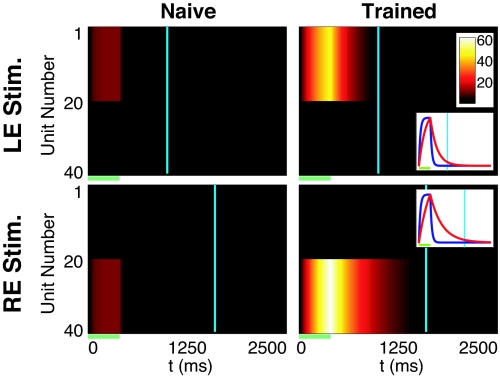
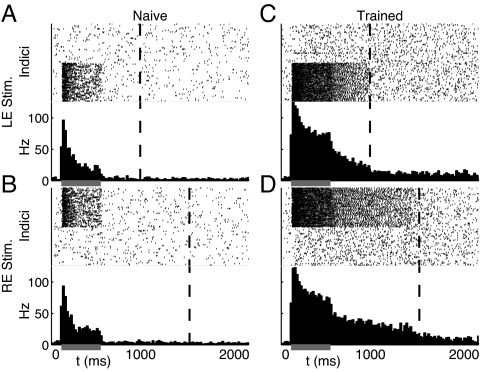
The ability to represent time is an essential component of cognition but its neural basis is unknown. Although extensively studied both behaviorally and electrophysiologically, a general theoretical framework describing the elementary neural mechanisms used by the brain to learn temporal representations is lacking. It is commonly believed that the underlying cellular mechanisms reside in high order cortical regions but recent studies show sustained neural activity in primary sensory cortices that can represent the timing of expected reward. Here, we show that local cortical networks can learn temporal representations through a simple framework predicated on reward dependent expression of synaptic plasticity. We assert that temporal representations are stored in the lateral synaptic connections between neurons and demonstrate that reward-modulated plasticity is sufficient to learn these representations. We implement our model numerically to explain reward-time learning in the primary visual cortex (V1), demonstrate experimental support, and suggest additional experimentally verifiable predictions.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Mauk MD, Buonomano DV. The neural basis of temporal processing. Annu Rev Neurosci. 2004;27:307–340. - PubMed
-
- Lewis PA, Miall RC. Remembering the time: A continuous clock. Trends Cogn Sci. 2006;10:401–406. - PubMed
-
- Staddon JE. Interval timing: Memory, not a clock. Trends Cogn Sci. 2005;9:312–314. - PubMed
-
- Meck WH. Neuropsychology of timing and time perception. Brain Cogn. 2005;58:1–8. - PubMed
-
- Rammsayer TH. Neuropharmacological evidence for different timing mechanisms in humans. Q J Exp Psychol B. 1999;52:273–286. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
