

TARGeT: a web-based pipeline for retrieving and characterizing gene and transposable element families from genomic sequences
- PMID: 19429695
- PMCID: PMC2699529
- DOI: 10.1093/nar/gkp295
TARGeT: a web-based pipeline for retrieving and characterizing gene and transposable element families from genomic sequences
Abstract
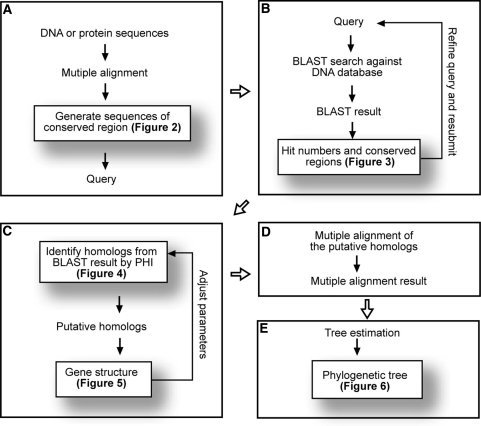
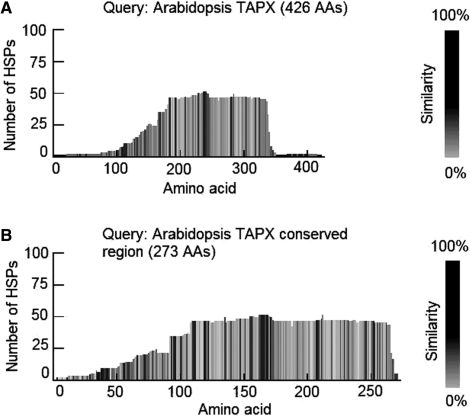
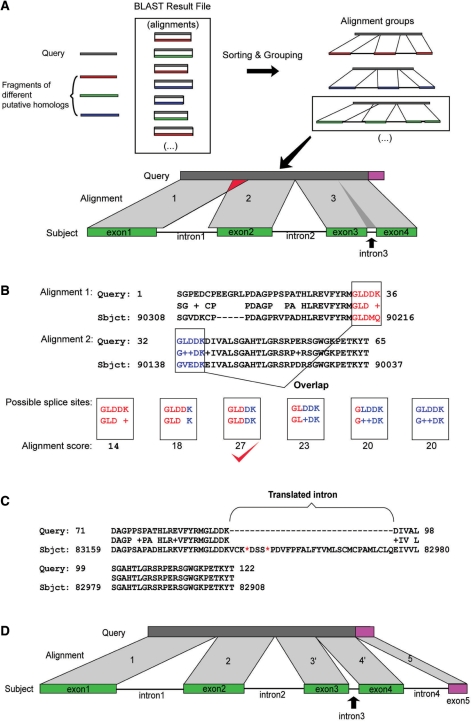
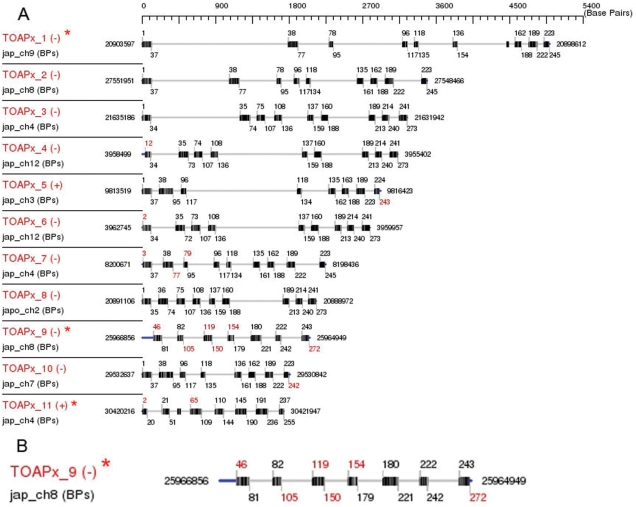
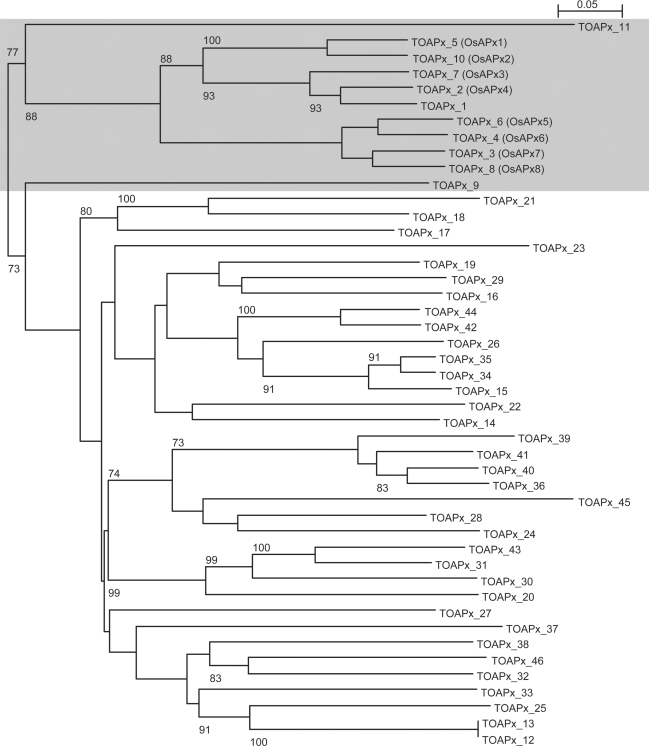
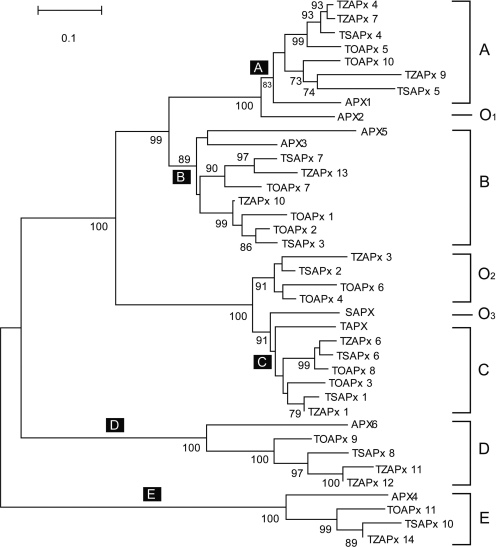
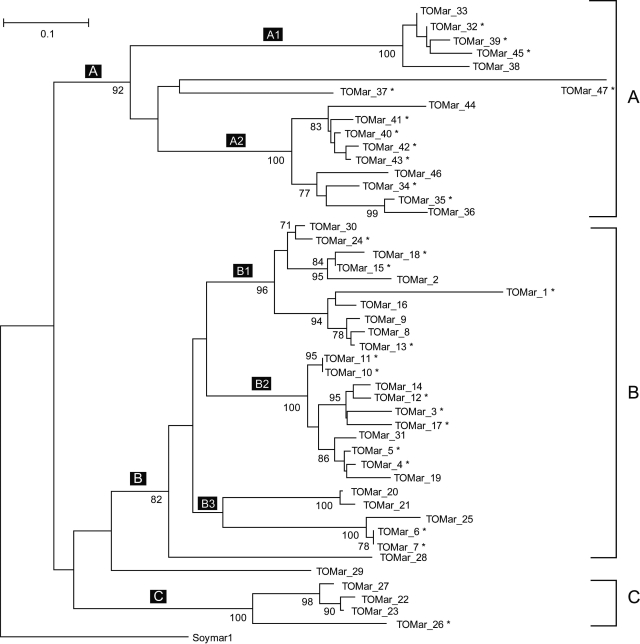
Gene families compose a large proportion of eukaryotic genomes. The rapidly expanding genomic sequence database provides a good opportunity to study gene family evolution and function. However, most gene family identification programs are restricted to searching protein databases where data are often lagging behind the genomic sequence data. Here, we report a user-friendly web-based pipeline, named TARGeT (Tree Analysis of Related Genes and Transposons), which uses either a DNA or amino acid 'seed' query to: (i) automatically identify and retrieve gene family homologs from a genomic database, (ii) characterize gene structure and (iii) perform phylogenetic analysis. Due to its high speed, TARGeT is also able to characterize very large gene families, including transposable elements (TEs). We evaluated TARGeT using well-annotated datasets, including the ascorbate peroxidase gene family of rice, maize and sorghum and several TE families in rice. In all cases, TARGeT rapidly recapitulated the known homologs and predicted new ones. We also demonstrated that TARGeT outperforms similar pipelines and has functionality that is not offered elsewhere.
Figures
References
-
- Yu J, Hu S, Wang J, Wong GK, Li S, Liu B, Deng Y, Dai L, Zhou Y, Zhang X, et al. A draft sequence of the rice genome (Oryza sativa L. ssp. indica) Science. 2002;296:79–92. - PubMed
-
- Goff SA, Ricke D, Lan TH, Presting G, Wang R, Dunn M, Glazebrook J, Sessions A, Oeller P, Varma H, et al. A draft sequence of the rice genome (Oryza sativa L. ssp. japonica) Science. 2002;296:92–100. - PubMed
-
- Li WH, Gu Z, Wang H, Nekrutenko A. Evolutionary analyses of the human genome. Nature. 2001;409:847–849. - PubMed
-
- Arabidopsis Genome Initiative. Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature. 2000;408:796–815. - PubMed
