

Diversity and complexity in DNA recognition by transcription factors
- PMID: 19443739
- PMCID: PMC2905877
- DOI: 10.1126/science.1162327
Diversity and complexity in DNA recognition by transcription factors
Abstract
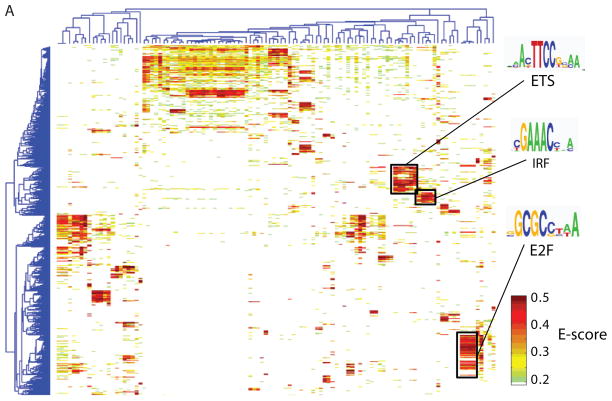
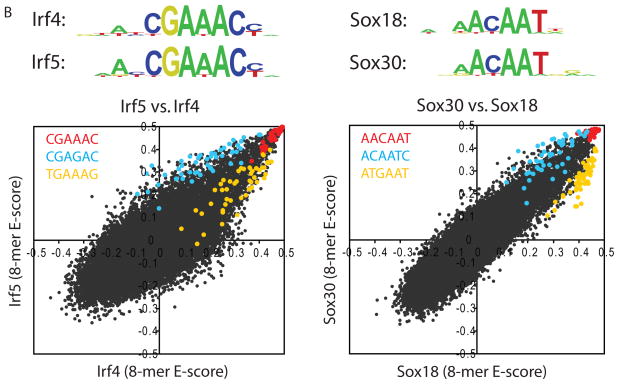
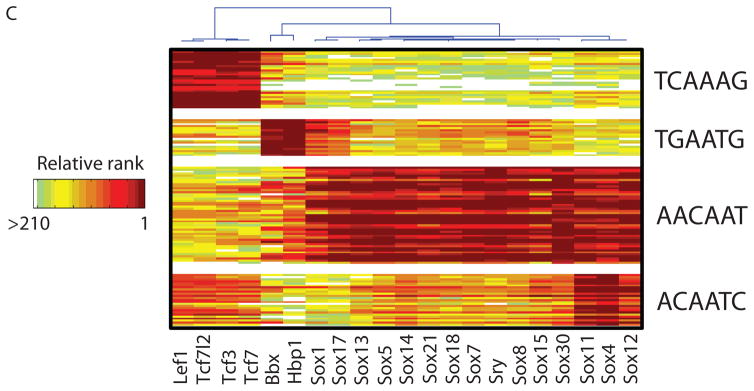
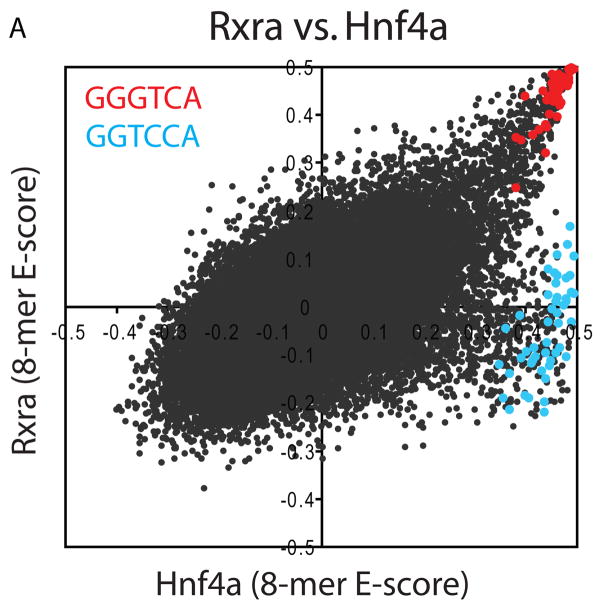
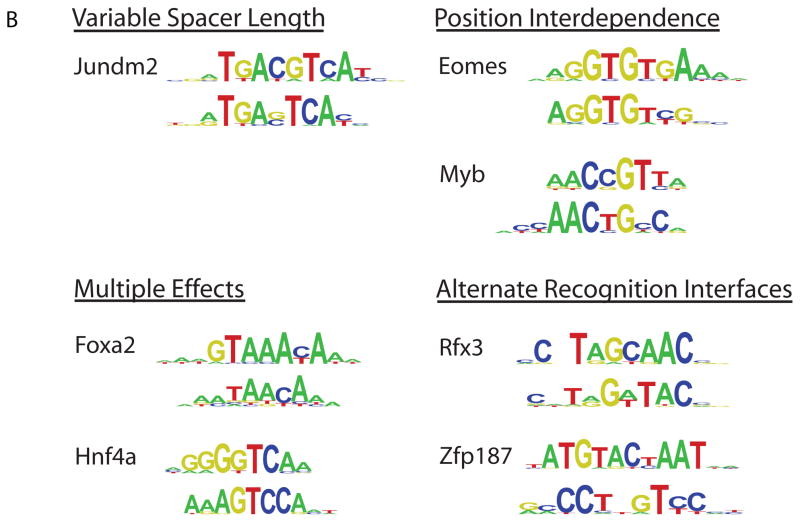
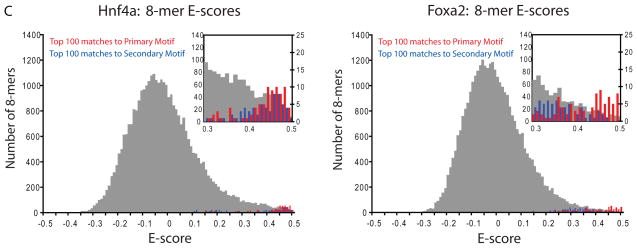
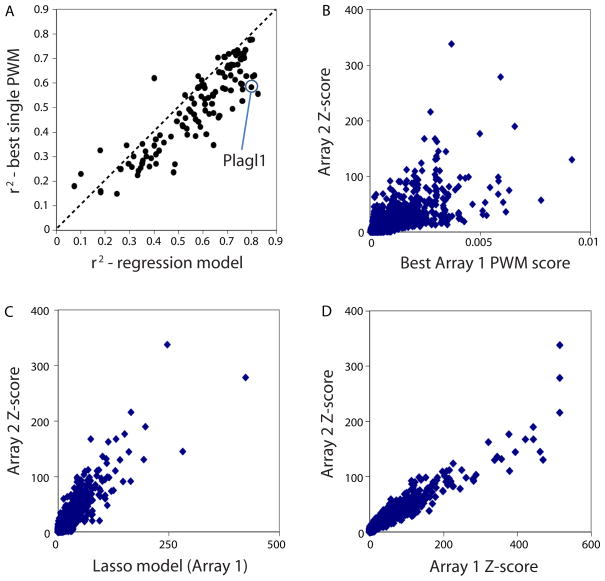
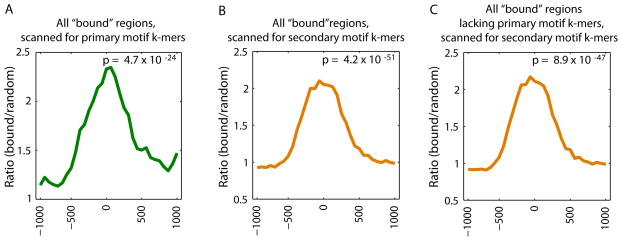
Sequence preferences of DNA binding proteins are a primary mechanism by which cells interpret the genome. Despite the central importance of these proteins in physiology, development, and evolution, comprehensive DNA binding specificities have been determined experimentally for only a few proteins. Here, we used microarrays containing all 10-base pair sequences to examine the binding specificities of 104 distinct mouse DNA binding proteins representing 22 structural classes. Our results reveal a complex landscape of binding, with virtually every protein analyzed possessing unique preferences. Roughly half of the proteins each recognized multiple distinctly different sequence motifs, challenging our molecular understanding of how proteins interact with their DNA binding sites. This complexity in DNA recognition may be important in gene regulation and in the evolution of transcriptional regulatory networks.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
