

Nature of the protein universe
- PMID: 19541617
- PMCID: PMC2698892
- DOI: 10.1073/pnas.0905029106
Nature of the protein universe
Abstract
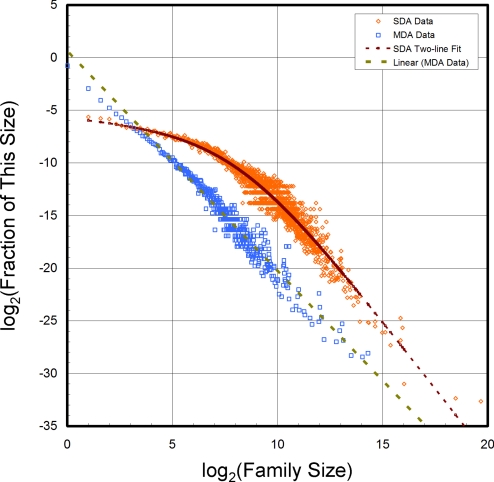
The protein universe is the set of all proteins of all organisms. Here, all currently known sequences are analyzed in terms of families that have single-domain or multidomain architectures and whether they have a known three-dimensional structure. Growth of new single-domain families is very slow: Almost all growth comes from new multidomain architectures that are combinations of domains characterized by approximately 15,000 sequence profiles. Single-domain families are mostly shared by the major groups of organisms, whereas multidomain architectures are specific and account for species diversity. There are known structures for a quarter of the single-domain families, and >70% of all sequences can be partially modeled thanks to their membership in these families.
Conflict of interest statement
The author declares no conflict of interest.
Figures




References
-
- Ladunga I. Phylogenetic continuum indicates galaxies in the protein universe: Preliminary results on the natural group structures of proteins. J Mol Evol. 1992;4:358–375. - PubMed
-
- Sanger F. Arrangement of amino acids in proteins. Adv Protein Chem. 1952;7:1–66. - PubMed
-
- Fitch WM. Distinguishing homologous from analogous proteins. Syst Zool. 1970;19:99–113. - PubMed
-
- Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. Basic local alignment search tool. J Mol Biol. 1990;215:403–410. - PubMed
-
- Li W, Jaroszewski L, Godzik A. Clustering of highly homologous sequences to reduce the size of large protein databases. Bioinformatics. 2001;17:282–283. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
