

Development and evaluation of normalization methods for label-free relative quantification of endogenous peptides
- PMID: 19596695
- PMCID: PMC2758756
- DOI: 10.1074/mcp.M800514-MCP200
Development and evaluation of normalization methods for label-free relative quantification of endogenous peptides
Abstract
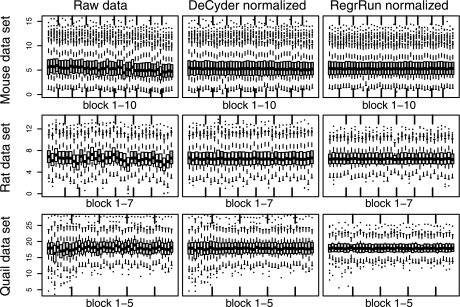
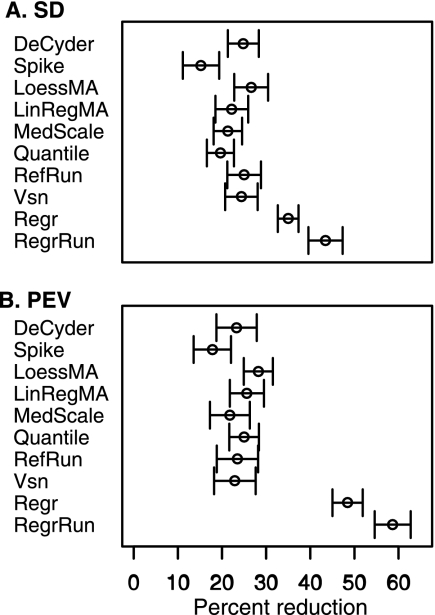
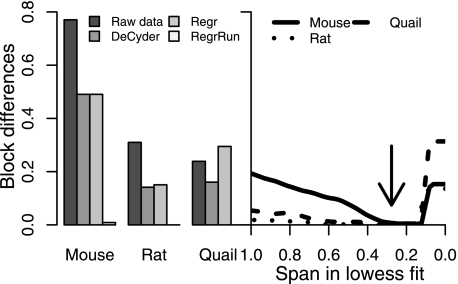
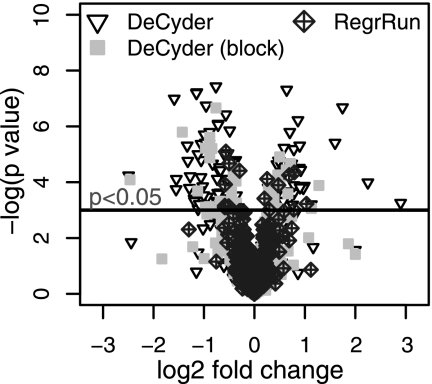
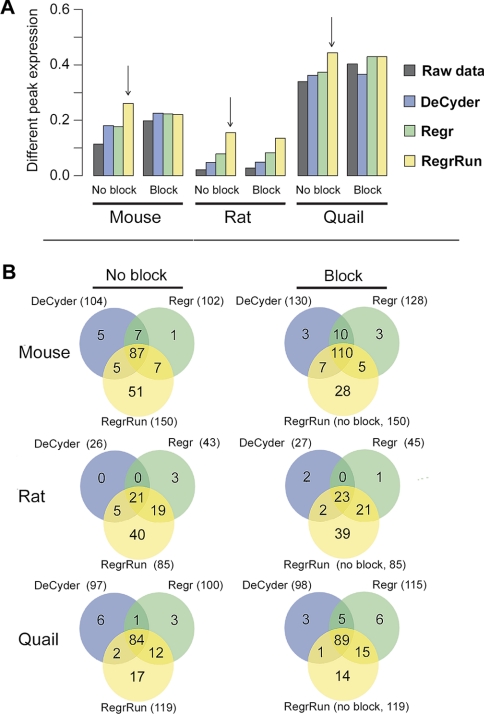
The performances of 10 different normalization methods on data of endogenous brain peptides produced with label-free nano-LC-MS were evaluated. Data sets originating from three different species (mouse, rat, and Japanese quail), each consisting of 35-45 individual LC-MS analyses, were used in the study. Each sample set contained both technical and biological replicates, and the LC-MS analyses were performed in a randomized block fashion. Peptides in all three data sets were found to display LC-MS analysis order-dependent bias. Global normalization methods will only to some extent correct this type of bias. Only the novel normalization procedure RegrRun (linear regression followed by analysis order normalization) corrected for this type of bias. The RegrRun procedure performed the best of the normalization methods tested and decreased the median S.D. by 43% on average compared with raw data. This method also produced the smallest fraction of peptides with interblock differences while producing the largest fraction of differentially expressed peaks between treatment groups in all three data sets. Linear regression normalization (Regr) performed second best and decreased median S.D. by 38% on average compared with raw data. All other examined methods reduced median S.D. by 20-30% on average compared with raw data.
Figures


References
-
- Clynen E., Baggerman G., Veelaert D., Cerstiaens A., Van der Horst D., Harthoorn L., Derua R., Waelkens E., De Loof A., Schoofs L. (2001) Peptidomics of the pars intercerebralis-corpus cardiacum complex of the migratory locust, Locusta migratoria. Eur. J. Biochem 268, 1929–1939 - PubMed
-
- Schulz-Knappe P., Zucht H. D., Heine G., Jürgens M., Hess R., Schrader M. (2001) Peptidomics: the comprehensive analysis of peptides in complex biological mixtures. Comb. Chem. High Throughput Screen 4, 207–217 - PubMed
-
- Verhaert P., Uttenweiler-Joseph S., de Vries M., Loboda A., Ens W., Standing K. G. (2001) Matrix-assisted laser desorption/ionization quadrupole time-of-flight mass spectrometry: an elegant tool for peptidomics. Proteomics 1, 118–131 - PubMed
-
- Svensson M., Sköld K., Nilsson A., Fälth M., Nydahl K., Svenningsson P., Andrén P. E. (2007) Neuropeptidomics: MS applied to the discovery of novel peptides from the brain. Anal. Chem 79, 15–16, 18–21 - PubMed
-
- Svensson M., Sköld K., Nilsson A., Fälth M., Svenningsson P., Andrén P. E. (2007) Neuropeptidomics: expanding proteomics downwards. Biochem. Soc. Trans 35, 588–593 - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
