

Mapping identifiers for the integration of genomic datasets with the R/Bioconductor package biomaRt
- PMID: 19617889
- PMCID: PMC3159387
- DOI: 10.1038/nprot.2009.97
Mapping identifiers for the integration of genomic datasets with the R/Bioconductor package biomaRt
Abstract
Genomic experiments produce multiple views of biological systems, among them are DNA sequence and copy number variation, and mRNA and protein abundance. Understanding these systems needs integrated bioinformatic analysis. Public databases such as Ensembl provide relationships and mappings between the relevant sets of probe and target molecules. However, the relationships can be biologically complex and the content of the databases is dynamic. We demonstrate how to use the computational environment R to integrate and jointly analyze experimental datasets, employing BioMart web services to provide the molecule mappings. We also discuss typical problems that are encountered in making gene-to-transcript-to-protein mappings. The approach provides a flexible, programmable and reproducible basis for state-of-the-art bioinformatic data integration.
Conflict of interest statement
The authors declare that they have no competing financial interests.
Figures
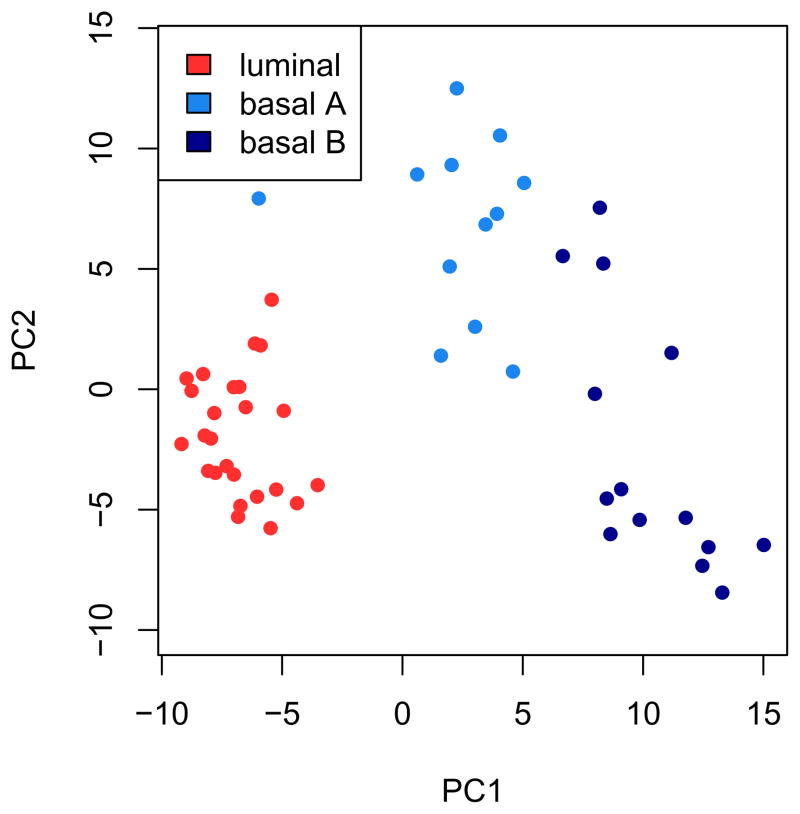
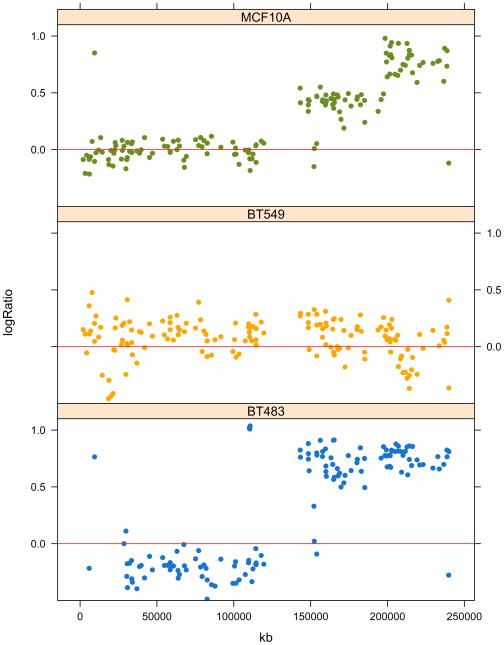
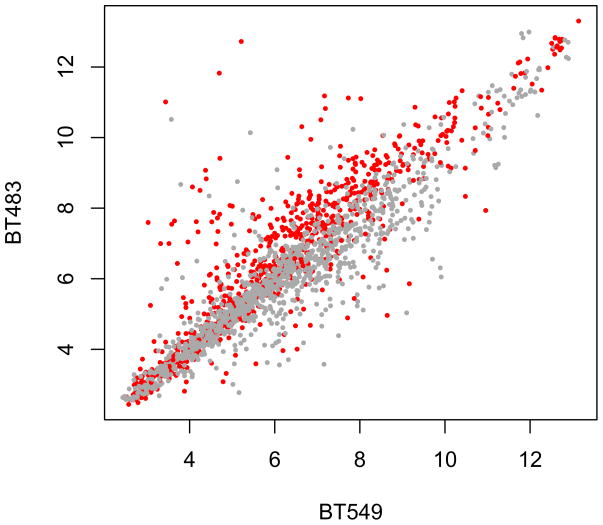
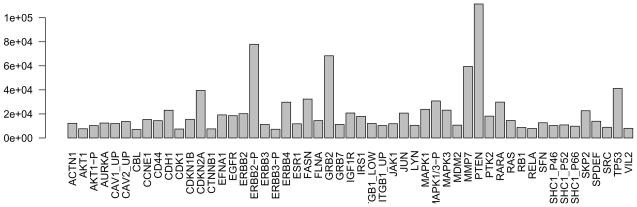
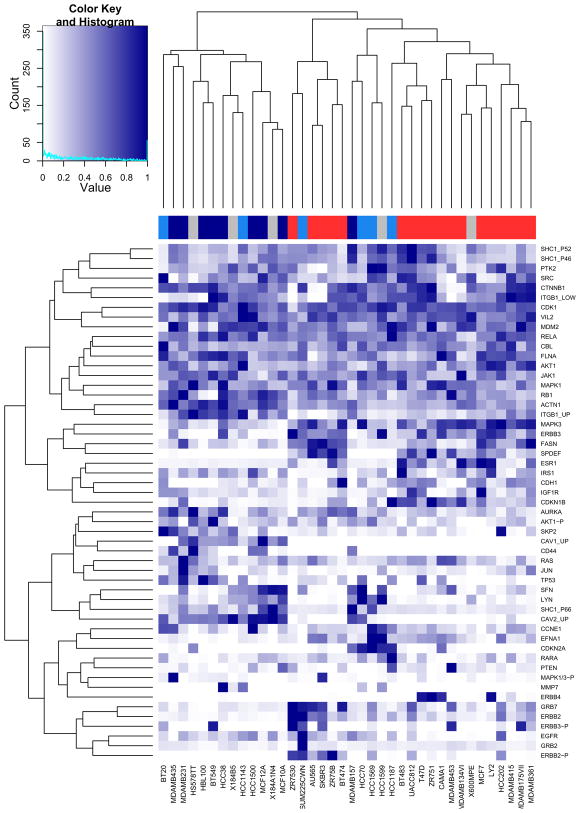
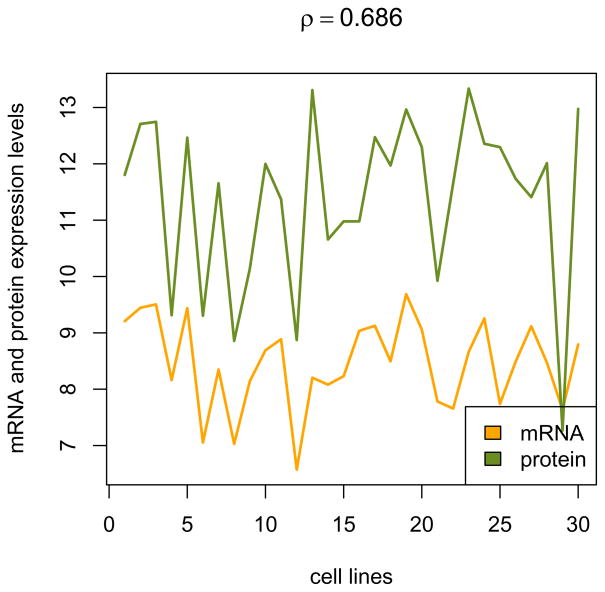
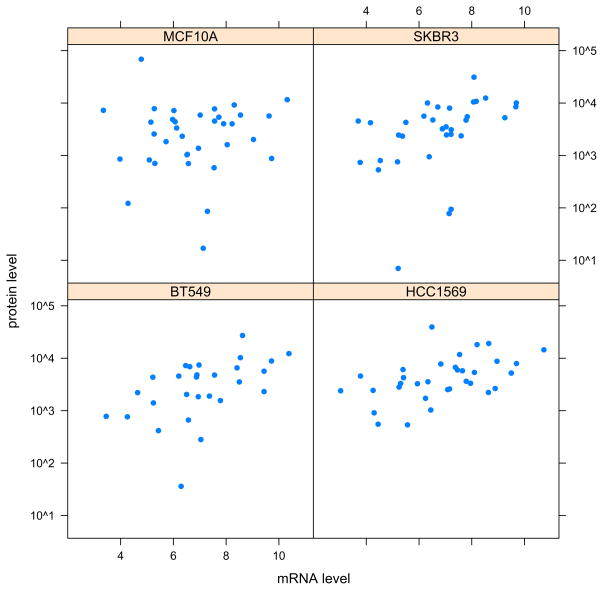
References
-
- R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; Vienna, Austria: 2008.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
