

The RNA structure alignment ontology
- PMID: 19622678
- PMCID: PMC2743057
- DOI: 10.1261/rna.1601409
The RNA structure alignment ontology
Abstract
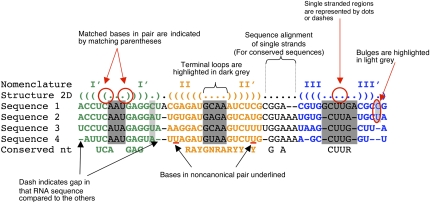
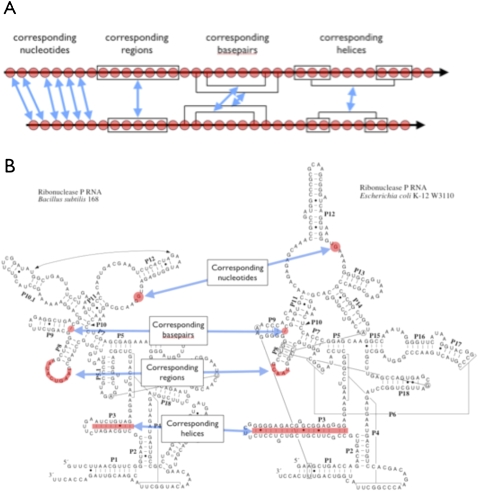
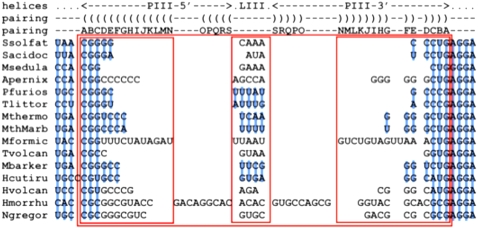
Multiple sequence alignments are powerful tools for understanding the structures, functions, and evolutionary histories of linear biological macromolecules (DNA, RNA, and proteins), and for finding homologs in sequence databases. We address several ontological issues related to RNA sequence alignments that are informed by structure. Multiple sequence alignments are usually shown as two-dimensional (2D) matrices, with rows representing individual sequences, and columns identifying nucleotides from different sequences that correspond structurally, functionally, and/or evolutionarily. However, the requirement that sequences and structures correspond nucleotide-by-nucleotide is unrealistic and hinders representation of important biological relationships. High-throughput sequencing efforts are also rapidly making 2D alignments unmanageable because of vertical and horizontal expansion as more sequences are added. Solving the shortcomings of traditional RNA sequence alignments requires explicit annotation of the meaning of each relationship within the alignment. We introduce the notion of "correspondence," which is an equivalence relation between RNA elements in sets of sequences as the basis of an RNA alignment ontology. The purpose of this ontology is twofold: first, to enable the development of new representations of RNA data and of software tools that resolve the expansion problems with current RNA sequence alignments, and second, to facilitate the integration of sequence data with secondary and three-dimensional structural information, as well as other experimental information, to create simultaneously more accurate and more exploitable RNA alignments.
Figures

References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources