

Natural Language Processing Versus Content-Based Image Analysis for Medical Document Retrieval
- PMID: 19633735
- PMCID: PMC2714909
- DOI: 10.1002/asi.20955
Natural Language Processing Versus Content-Based Image Analysis for Medical Document Retrieval
Abstract
One of the most significant recent advances in health information systems has been the shift from paper to electronic documents. While research on automatic text and image processing has taken separate paths, there is a growing need for joint efforts, particularly for electronic health records and biomedical literature databases. This work aims at comparing text-based versus image-based access to multimodal medical documents using state-of-the-art methods of processing text and image components. A collection of 180 medical documents containing an image accompanied by a short text describing it was divided into training and test sets. Content-based image analysis and natural language processing techniques are applied individually and combined for multimodal document analysis. The evaluation consists of an indexing task and a retrieval task based on the "gold standard" codes manually assigned to corpus documents. The performance of text-based and image-based access, as well as combined document features, is compared. Image analysis proves more adequate for both the indexing and retrieval of the images. In the indexing task, multimodal analysis outperforms both independent image and text analysis. This experiment shows that text describing images can be usefully analyzed in the framework of a hybrid text/image retrieval system.
Figures

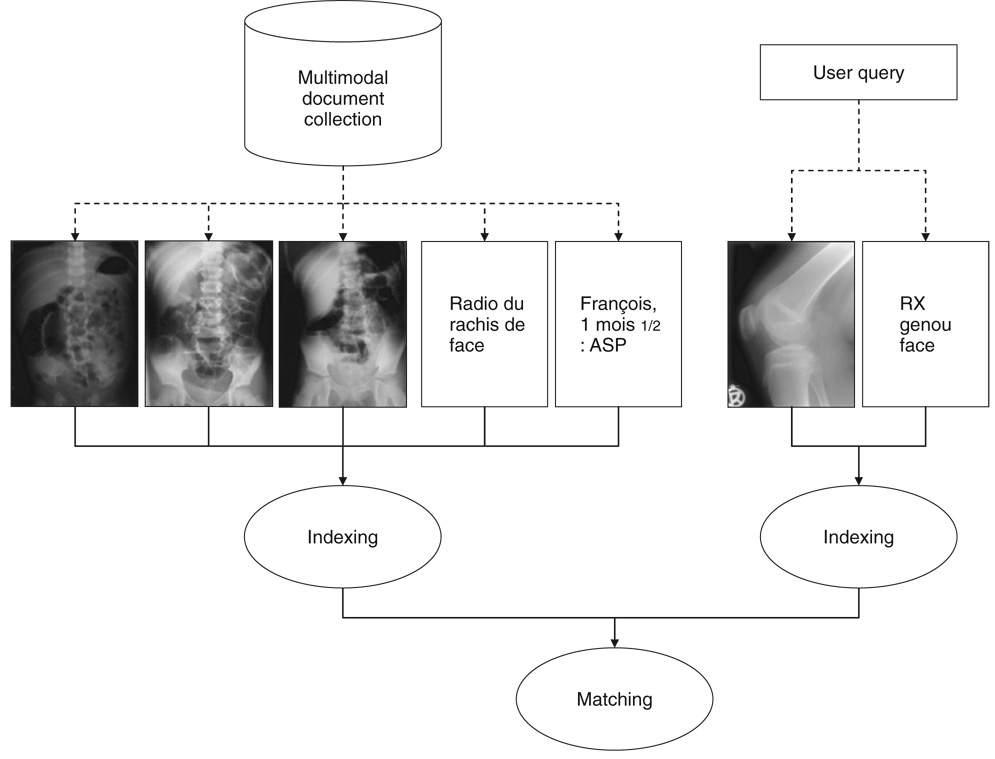
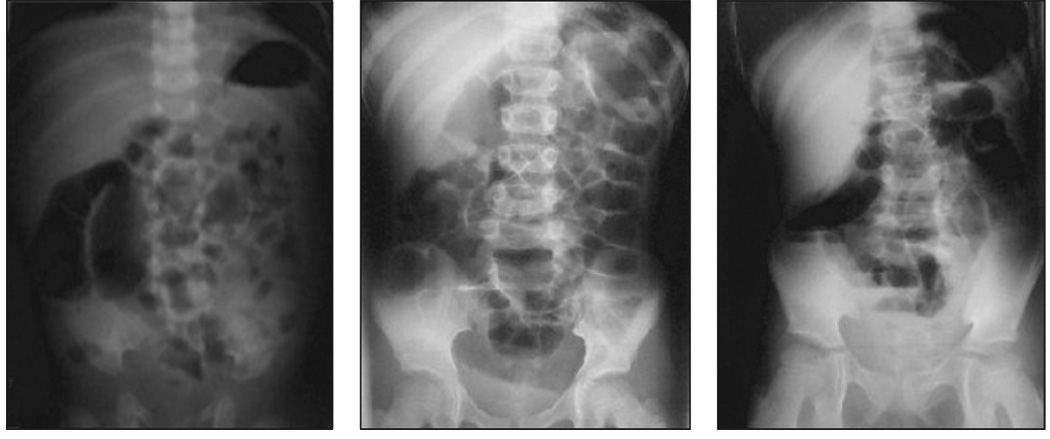



References
-
- Aachen University of Technology Image retrieval in medical applications. 2008. Retrieved March 28, 2008, from http://www.irma-project.org/index_en.php.
-
- Aronson AR, Bodenreider O, Demner-Fushman D, Fung KW, Lee VK, Mork JG, et al. From indexing the biomedical literature to coding clinical text : Experience with MTI and machine learning approaches. In: Cohen K, Demner-Fushman D, Friedman C, Hirschman L, Pestian J, editors. Proceedings of the ACL 2007 Workshop on Biological, Translational, and Clinical Language Processing (BioNLP); 2007. pp. 105–112.
-
- Boujemaa N, Fauqueur J, Gouet V. IAPR International Conference on Image and Signal Processing (ICISP’ 2003), Agadir, Morocco. What's beyond query by example? 2003. Jun, Retrieved August 29, 2008, from http://www-rocq.inria.fr/~gouet/Recherche/Papiers/icisp03/pdf.
-
- Briet S. Qu’est-ce que la documentation? [What is documentation?] Paris: Éditions Documentaires et Industrielles; 1951. [English translation retrieved April 29, 2007, from http://martinetl.free.fr/suzanne_briet.htm and archived at http://www.webcitation.org/5OUOoaTjW]
-
- Byrne K, Klein E. Image retrieval using natural language and content-based techniques. In: de Vries AP, editor. Proceedings of the Fourth Dutch-Belgian Information Retrieval Workshop (DIR 2003); Amsterdam: Institute for Logic, Language, and Computation; 2003. pp. 57–62.
Grants and funding
LinkOut - more resources
Full Text Sources