

Overlapping genes produce proteins with unusual sequence properties and offer insight into de novo protein creation
- PMID: 19640978
- PMCID: PMC2753099
- DOI: 10.1128/JVI.00595-09
Overlapping genes produce proteins with unusual sequence properties and offer insight into de novo protein creation
Abstract
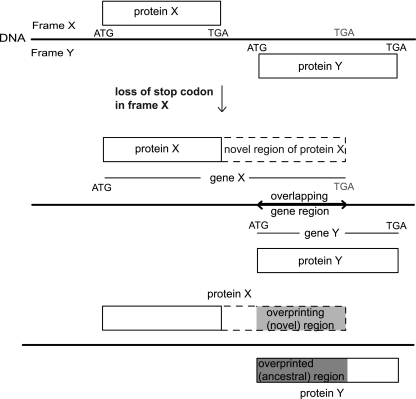
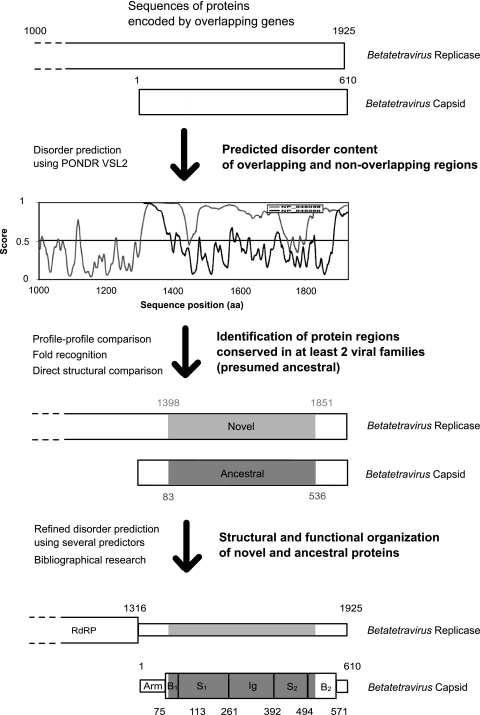
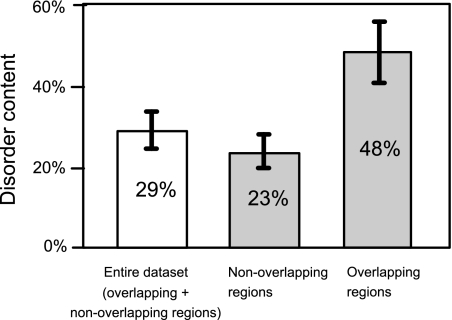
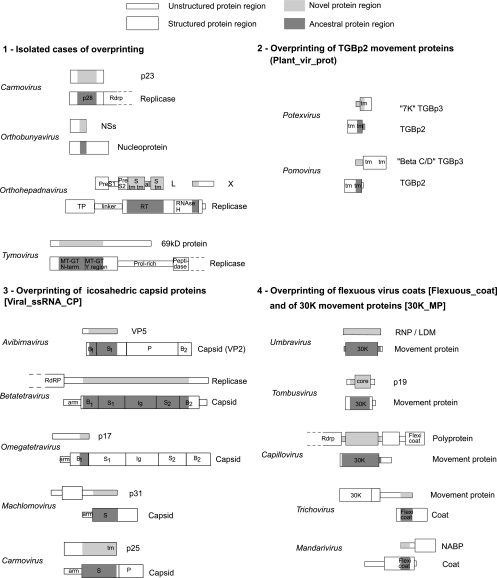
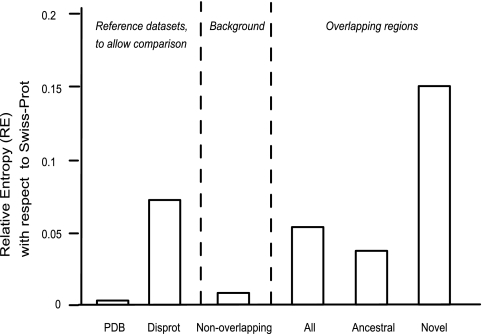
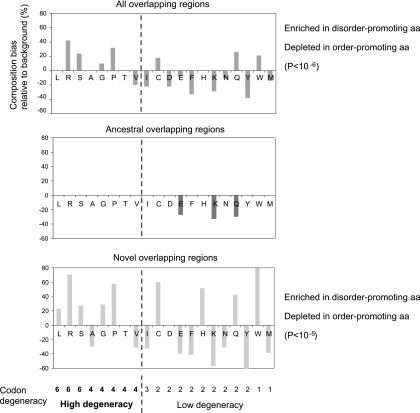
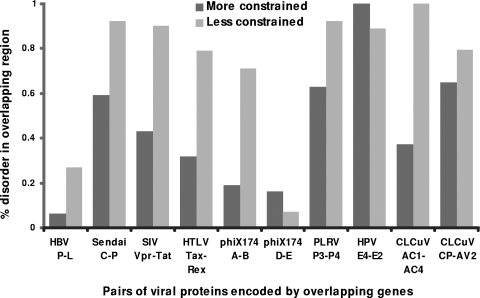
It is widely assumed that new proteins are created by duplication, fusion, or fission of existing coding sequences. Another mechanism of protein birth is provided by overlapping genes. They are created de novo by mutations within a coding sequence that lead to the expression of a novel protein in another reading frame, a process called "overprinting." To investigate this mechanism, we have analyzed the sequences of the protein products of manually curated overlapping genes from 43 genera of unspliced RNA viruses infecting eukaryotes. Overlapping proteins have a sequence composition globally biased toward disorder-promoting amino acids and are predicted to contain significantly more structural disorder than nonoverlapping proteins. By analyzing the phylogenetic distribution of overlapping proteins, we were able to confirm that 17 of these had been created de novo and to study them individually. Most proteins created de novo are orphans (i.e., restricted to one species or genus). Almost all are accessory proteins that play a role in viral pathogenicity or spread, rather than proteins central to viral replication or structure. Most proteins created de novo are predicted to be fully disordered and have a highly unusual sequence composition. This suggests that some viral overlapping reading frames encoding hypothetical proteins with highly biased composition, often discarded as noncoding, might in fact encode proteins. Some proteins created de novo are predicted to be ordered, however, and whenever a three-dimensional structure of such a protein has been solved, it corresponds to a fold previously unobserved, suggesting that the study of these proteins could enhance our knowledge of protein space.
Figures
References
-
- Ball, L. A. 2007. Virus replication strategies, p. 119-139. In D. M. Knipe and P. M. Howley (ed.), Fields virology, 5th ed., vol. 1. Lippincott Williams & Wilkins, Philadelphia, PA.
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
