

Non-B DNA structure-induced genetic instability and evolution
- PMID: 19727556
- PMCID: PMC3017512
- DOI: 10.1007/s00018-009-0131-2
Non-B DNA structure-induced genetic instability and evolution
Abstract
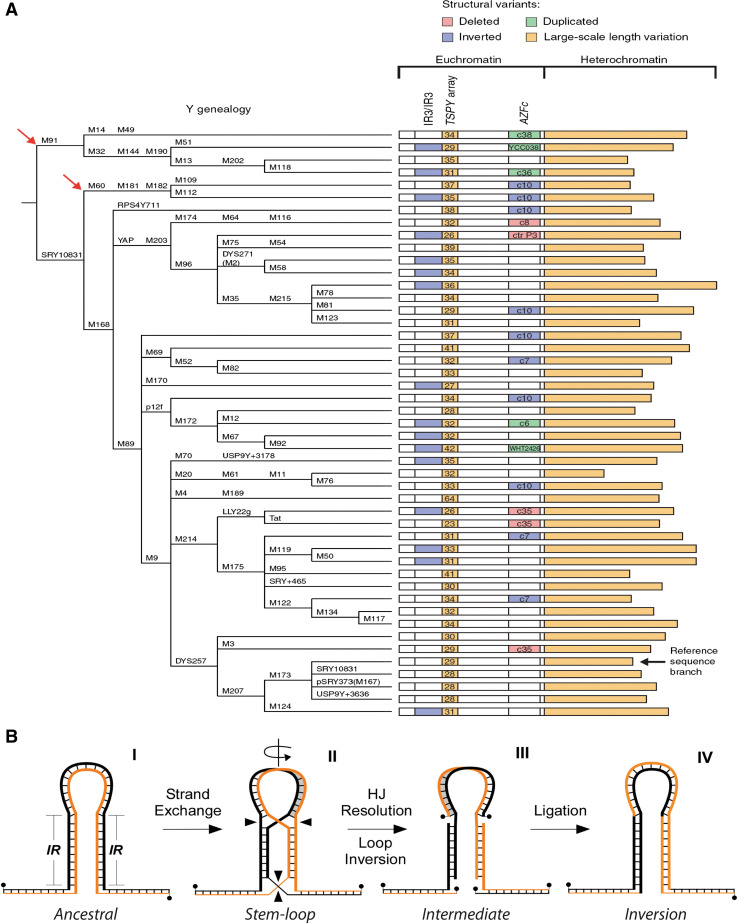
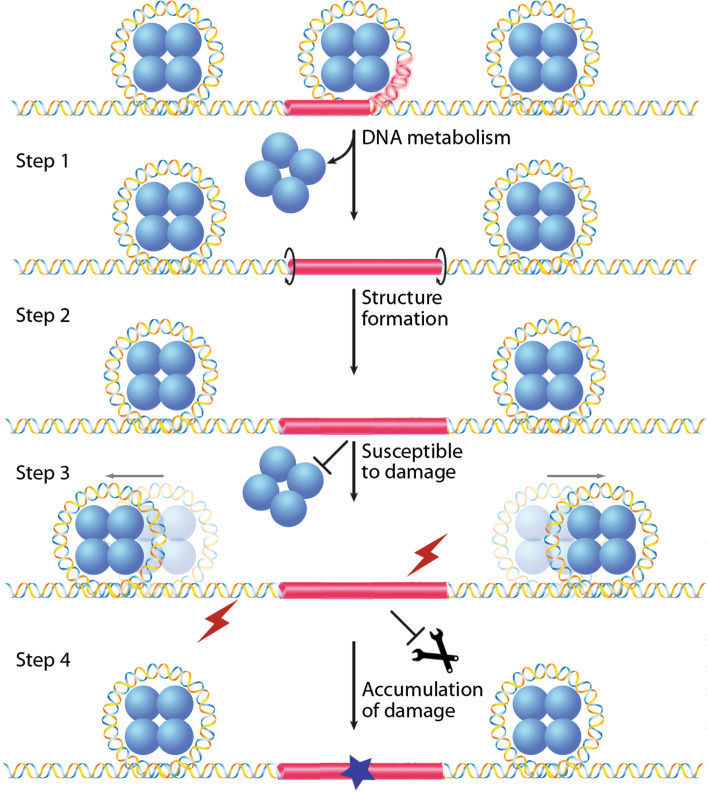
Repetitive DNA motifs are abundant in the genomes of various species and have the capacity to adopt non-canonical (i.e., non-B) DNA structures. Several non-B DNA structures, including cruciforms, slipped structures, triplexes, G-quadruplexes, and Z-DNA, have been shown to cause mutations, such as deletions, expansions, and translocations in both prokaryotes and eukaryotes. Their distributions in genomes are not random and often co-localize with sites of chromosomal breakage associated with genetic diseases. Current genome-wide sequence analyses suggest that the genomic instabilities induced by non-B DNA structure-forming sequences not only result in predisposition to disease, but also contribute to rapid evolutionary changes, particularly in genes associated with development and regulatory functions. In this review, we describe the occurrence of non-B DNA-forming sequences in various species, the classes of genes enriched in non-B DNA-forming sequences, and recent mechanistic studies on DNA structure-induced genomic instability to highlight their importance in genomes.
Figures


References
-
- Watson JD, Crick FH. Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid. Nature. 1953;171:737–738. - PubMed
-
- Mirkin SM. Discovery of alternative DNA structures: a heroic decade (1979–1989) Front Biosci. 2008;13:1064–1071. - PubMed
-
- Felsenfeld G, Davies DR, Rich A. Formation of a three-stranded polynucleotide molecule. J Am Chem Soc. 1957;79:2023–2024.
-
- Wang AH, Quigley GJ, Kolpak FJ, Crawford JL, van Boom JH, van der Marel G, Rich A. Molecular structure of a left-handed double helical DNA fragment at atomic resolution. Nature. 1979;282:680–686. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
