

Watching the Word Go by: On the Time-course of Component Processes in Visual Word Recognition
- PMID: 19750025
- PMCID: PMC2740997
- DOI: 10.1111/j.1749-818X.2008.00121.x
Watching the Word Go by: On the Time-course of Component Processes in Visual Word Recognition
Abstract
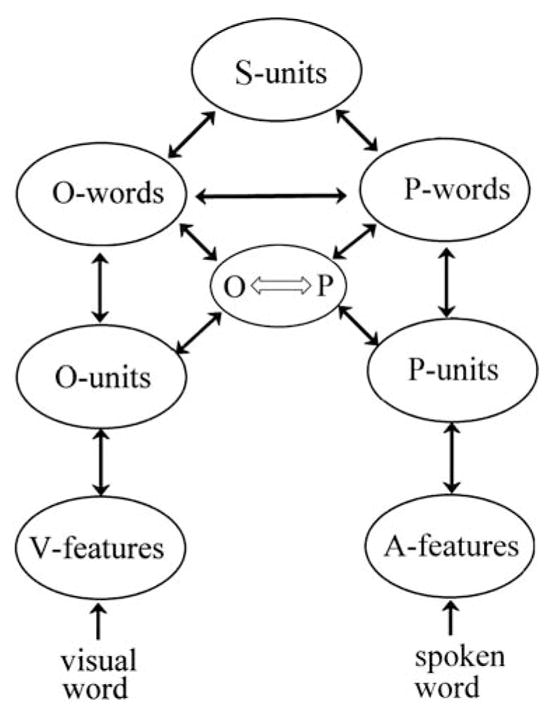
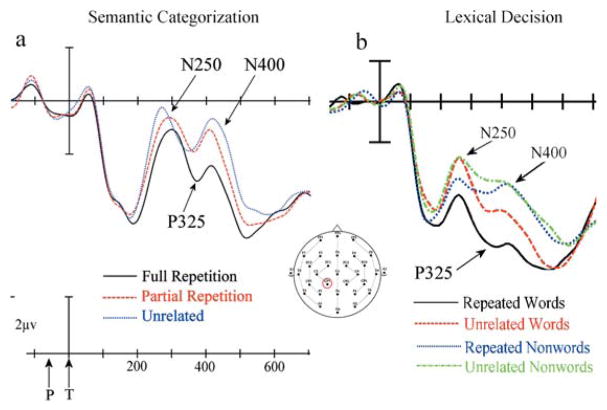
We describe a functional architecture for word recognition that focuses on how orthographic and phonological information cooperates in initial form-based processing of printed word stimuli prior to accessing semantic information. Component processes of orthographic processing and orthography-to-phonology translation are described, and the behavioral evidence in favor of such mechanisms is briefly summarized. Our theoretical framework is then used to interpret the results of a large number of recent experiments that have combined the masked priming paradigm with electrophysiological recordings. These experiments revealed a series of components in the event-related potential (ERP), thought to reflect the cascade of underlying processes involved in the transition from visual feature extraction to semantic activation. We provide a tentative mapping of ERP components onto component processes in the model, hence specifying the relative time-course of these processes and their functional significance.
Figures














References
-
- Anderson JE, Holcomb PJ. Auditory and visual semantic priming using different stimulus onset asynchronies: An event-related brain potential study. Psychophysiology. 1995;32:177–90. - PubMed
-
- Barber HA, Kutas M. Interplay between computational models and cognitive electrophysiology in visual word recognition. Brain Research Reviews. 2007;53:98–123. - PubMed
-
- Bentin S, McCarthy G, Wood CC. Event-related potentials, lexical decision and semantic priming. Electroencephalography and Clinical Neurophysiology. 1985;60:343–55. - PubMed
-
- Bentin S, Mouchetant-Rostaing Y, Giard MH, Echallier JF, Pernier J. ERP manifestations of processing printed words at different psycholinguistic levels: Time course and scalp distribution. Journal of Cognitive Neuroscience. 1999;11:35–60. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources