

Structural genomics and drug discovery for infectious diseases
- PMID: 19860716
- PMCID: PMC2789569
- DOI: 10.2174/187152609789105713
Structural genomics and drug discovery for infectious diseases
Abstract
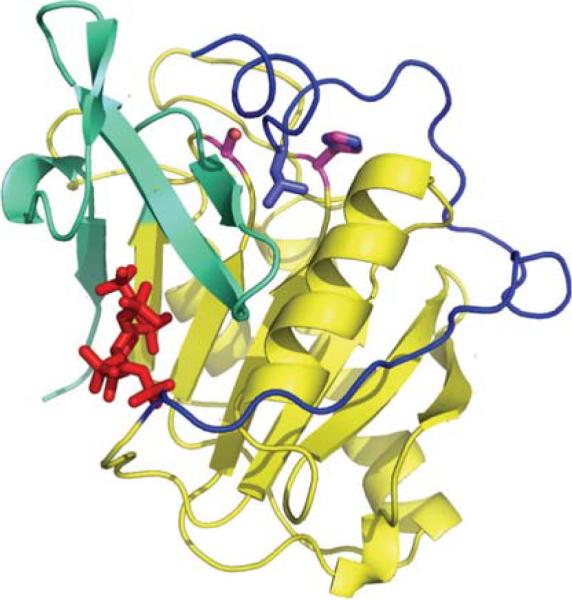
The application of structural genomics methods and approaches to proteins from organisms causing infectious diseases is making available the three dimensional structures of many proteins that are potential drug targets and laying the groundwork for structure aided drug discovery efforts. There are a number of structural genomics projects with a focus on pathogens that have been initiated worldwide. The Center for Structural Genomics of Infectious Diseases (CSGID) was recently established to apply state-of-the-art high throughput structural biology technologies to the characterization of proteins from the National Institute for Allergy and Infectious Diseases (NIAID) category A-C pathogens and organisms causing emerging, or re-emerging infectious diseases. The target selection process emphasizes potential biomedical benefits. Selected proteins include known drug targets and their homologs, essential enzymes, virulence factors and vaccine candidates. The Center also provides a structure determination service for the infectious disease scientific community. The ultimate goal is to generate a library of structures that are available to the scientific community and can serve as a starting point for further research and structure aided drug discovery for infectious diseases. To achieve this goal, the CSGID will determine protein crystal structures of 400 proteins and protein-ligand complexes using proven, rapid, highly integrated, and cost-effective methods for such determination, primarily by X-ray crystallography. High throughput crystallographic structure determination is greatly aided by frequent, convenient access to high-performance beamlines at third-generation synchrotron X-ray sources.
Figures



References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
