

Penalized model-based clustering with cluster-specific diagonal covariance matrices and grouped variables
- PMID: 19920875
- PMCID: PMC2777718
- DOI: 10.1214/08-EJS194
Penalized model-based clustering with cluster-specific diagonal covariance matrices and grouped variables
Abstract
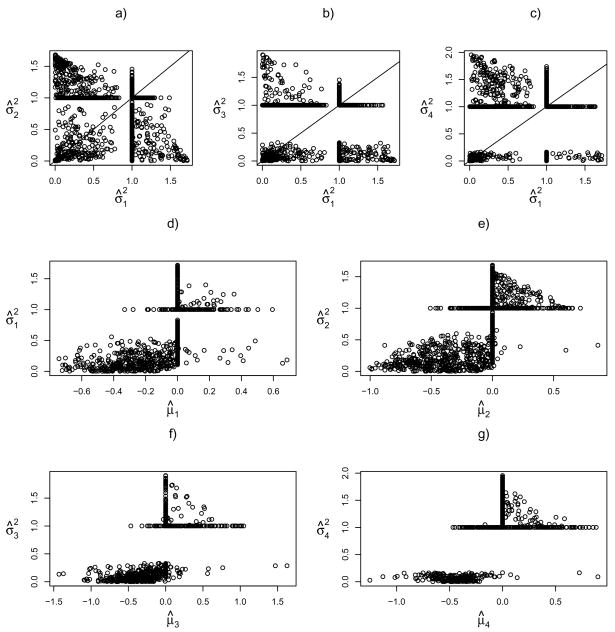
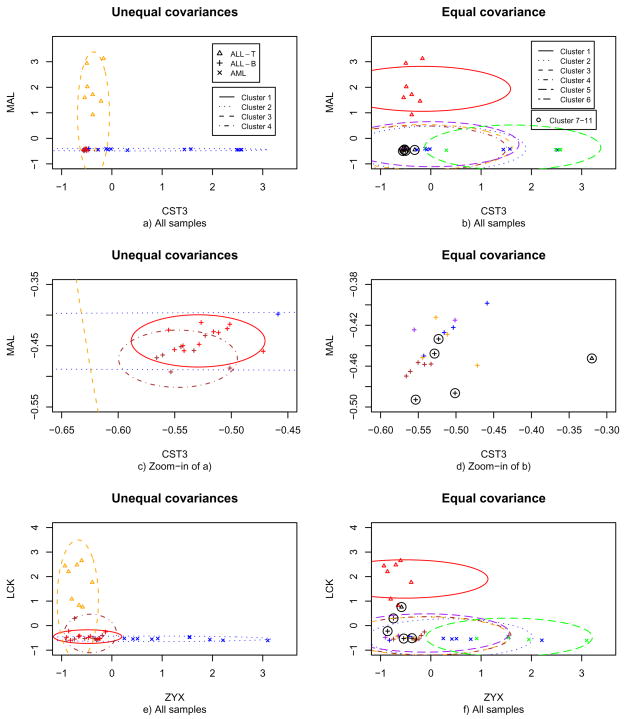
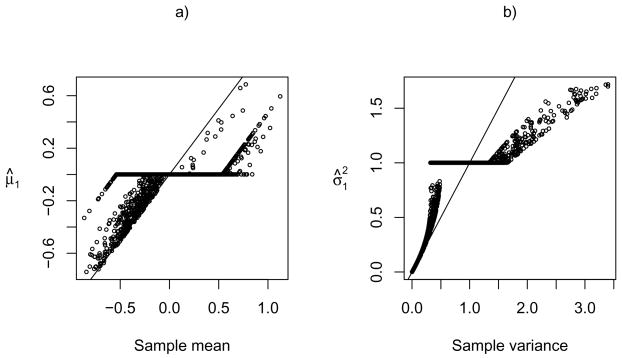
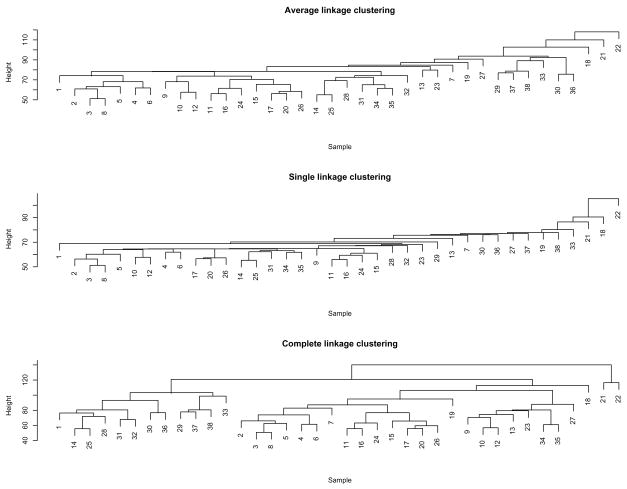
Clustering analysis is one of the most widely used statistical tools in many emerging areas such as microarray data analysis. For microarray and other high-dimensional data, the presence of many noise variables may mask underlying clustering structures. Hence removing noise variables via variable selection is necessary. For simultaneous variable selection and parameter estimation, existing penalized likelihood approaches in model-based clustering analysis all assume a common diagonal covariance matrix across clusters, which however may not hold in practice. To analyze high-dimensional data, particularly those with relatively low sample sizes, this article introduces a novel approach that shrinks the variances together with means, in a more general situation with cluster-specific (diagonal) covariance matrices. Furthermore, selection of grouped variables via inclusion or exclusion of a group of variables altogether is permitted by a specific form of penalty, which facilitates incorporating subject-matter knowledge, such as gene functions in clustering microarray samples for disease subtype discovery. For implementation, EM algorithms are derived for parameter estimation, in which the M-steps clearly demonstrate the effects of shrinkage and thresholding. Numerical examples, including an application to acute leukemia subtype discovery with microarray gene expression data, are provided to demonstrate the utility and advantage of the proposed method.
Figures
Similar articles
-
Penalized model-based clustering with unconstrained covariance matrices.Electron J Stat. 2009 Jan 1;3:1473-1496. doi: 10.1214/09-EJS487. Electron J Stat. 2009. PMID: 20463857 Free PMC article.
-
Penalized mixtures of factor analyzers with application to clustering high-dimensional microarray data.Bioinformatics. 2010 Feb 15;26(4):501-8. doi: 10.1093/bioinformatics/btp707. Epub 2009 Dec 23. Bioinformatics. 2010. PMID: 20031967 Free PMC article.
-
Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas.Cochrane Database Syst Rev. 2022 Feb 1;2(2022):CD014217. doi: 10.1002/14651858.CD014217. Cochrane Database Syst Rev. 2022. PMID: 36321557 Free PMC article.
-
Variable selection in penalized model-based clustering via regularization on grouped parameters.Biometrics. 2008 Sep;64(3):921-930. doi: 10.1111/j.1541-0420.2007.00955.x. Epub 2007 Dec 20. Biometrics. 2008. PMID: 18162109
-
Model-based approaches to synthesize microarray data: a unifying review using mixture of SEMs.Stat Methods Med Res. 2013 Dec;22(6):567-82. doi: 10.1177/0962280211419482. Epub 2011 Sep 25. Stat Methods Med Res. 2013. PMID: 21948997 Review.
Cited by
-
Meta-analytic framework for sparse K-means to identify disease subtypes in multiple transcriptomic studies.J Am Stat Assoc. 2016;111(513):27-42. doi: 10.1080/01621459.2015.1086354. Epub 2016 May 5. J Am Stat Assoc. 2016. PMID: 27330233 Free PMC article.
-
Cluster Analysis: Unsupervised Learning via Supervised Learning with a Non-convex Penalty.J Mach Learn Res. 2013 Jul 1;14(7):1865. J Mach Learn Res. 2013. PMID: 24358018 Free PMC article.
-
A framework for feature selection in clustering.J Am Stat Assoc. 2010 Jun 1;105(490):713-726. doi: 10.1198/jasa.2010.tm09415. J Am Stat Assoc. 2010. PMID: 20811510 Free PMC article.
-
Estimation of multiple networks in Gaussian mixture models.Electron J Stat. 2016;10:1133-1154. doi: 10.1214/16-EJS1135. Epub 2016 May 2. Electron J Stat. 2016. PMID: 28966702 Free PMC article.
-
Discovering a sparse set of pairwise discriminating features in high-dimensional data.Bioinformatics. 2021 Apr 19;37(2):202-212. doi: 10.1093/bioinformatics/btaa690. Bioinformatics. 2021. PMID: 32730566 Free PMC article.
References
-
- Alaiya AA, et al. Molecular classification of borderline ovarian tumors using hierarchical cluster analysis of protein expression profiles. Int J Cancer. 2002;98:895–899. - PubMed
-
- Antonov AV, Tetko IV, Mader MT, Budczies J, Mewes HW. Optimization models for cancer classification: extracting gene interaction information from microarray expression data. Bioinformatics. 2004;20:644–652. - PubMed
-
- Bardi E, Bobok I, Olah AV, Olah E, Kappelmayer J, Kiss C. Cystatin C is a suitable marker of glomerular function in children with cancer. Pediatric Nephrology. 2004;19:1145–1147. - PubMed
-
- Bickel PJ, Levina E. Some theory for Fisher’s linear discriminant function, “naive Bayes”, and some alternatives when there are many more variables than observations. Bernoulli. 2004;10:989–1010. MR2108040.
Grants and funding
LinkOut - more resources
Full Text Sources