

Potassium channel modulation by a toxin domain in matrix metalloprotease 23
- PMID: 19965868
- PMCID: PMC2838332
- DOI: 10.1074/jbc.M109.071266
Potassium channel modulation by a toxin domain in matrix metalloprotease 23
Abstract
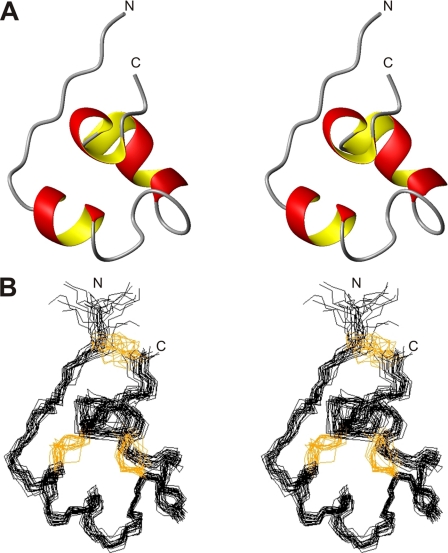
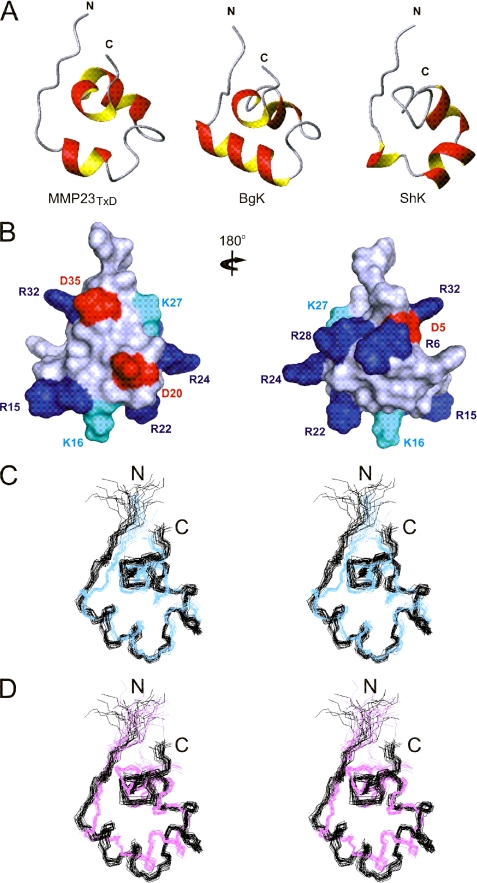
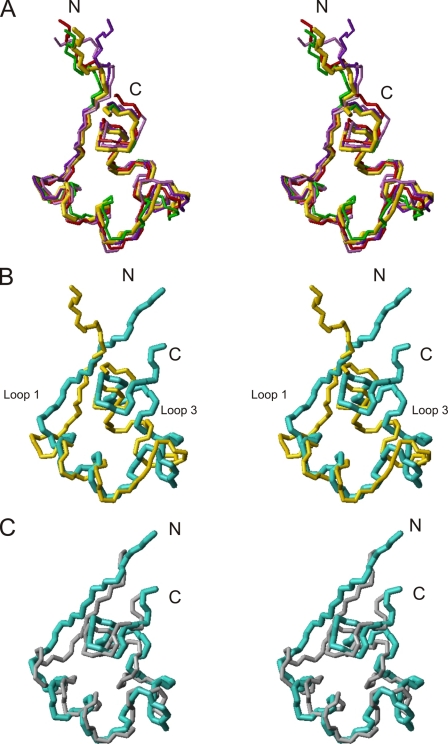
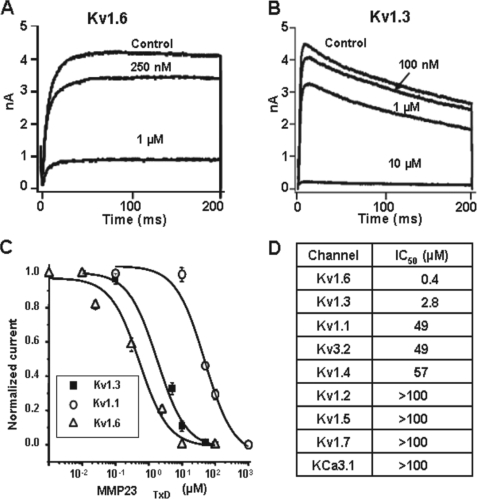
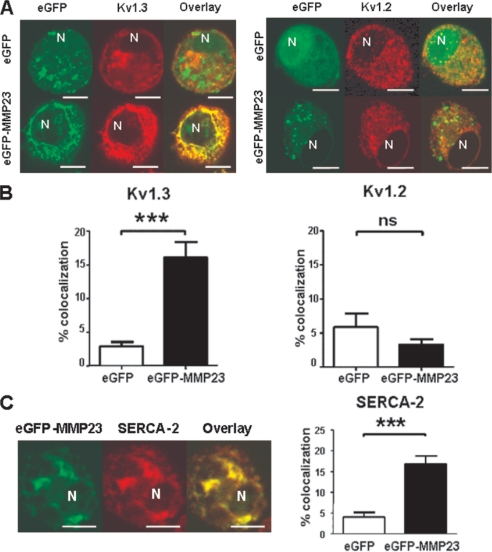
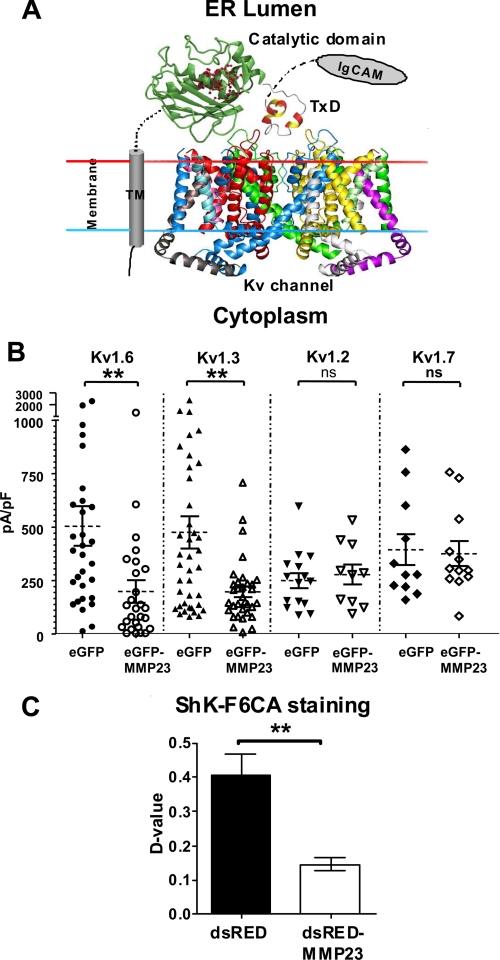
Peptide toxins found in a wide array of venoms block K(+) channels, causing profound physiological and pathological effects. Here we describe the first functional K(+) channel-blocking toxin domain in a mammalian protein. MMP23 (matrix metalloprotease 23) contains a domain (MMP23(TxD)) that is evolutionarily related to peptide toxins from sea anemones. MMP23(TxD) shows close structural similarity to the sea anemone toxins BgK and ShK. Moreover, this domain blocks K(+) channels in the nanomolar to low micromolar range (Kv1.6 > Kv1.3 > Kv1.1 = Kv3.2 > Kv1.4, in decreasing order of potency) while sparing other K(+) channels (Kv1.2, Kv1.5, Kv1.7, and KCa3.1). Full-length MMP23 suppresses K(+) channels by co-localizing with and trapping MMP23(TxD)-sensitive channels in the ER. Our results provide clues to the structure and function of the vast family of proteins that contain domains related to sea anemone toxins. Evolutionary pressure to maintain a channel-modulatory function may contribute to the conservation of this domain throughout the plant and animal kingdoms.
Figures
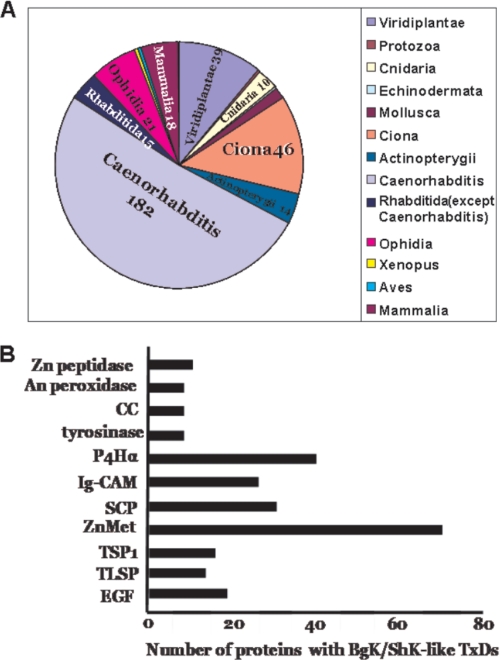
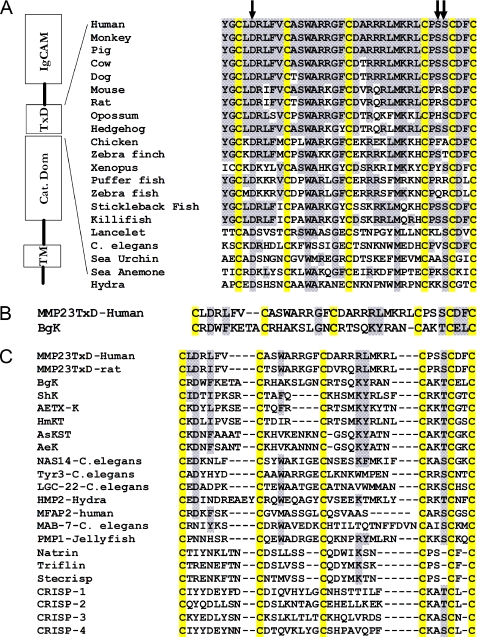
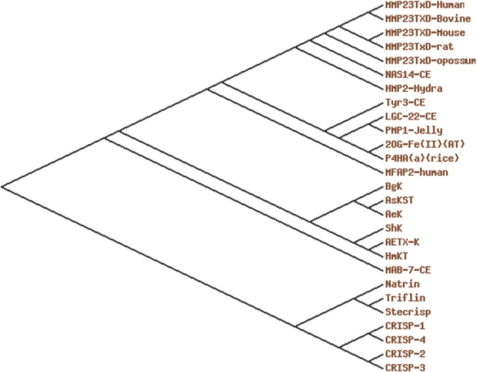
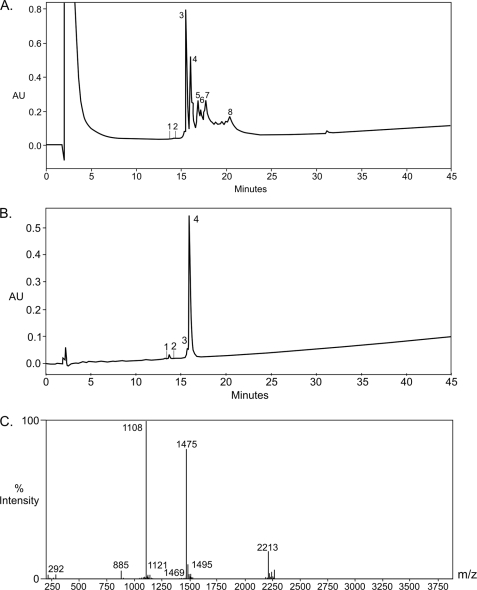
References
-
- Aiyar J., Withka J. M., Rizzi J. P., Singleton D. H., Andrews G. C., Lin W., Boyd J., Hanson D. C., Simon M., Dethlefs B., Gutman G. A., Chandy K. G. (1995) Neuron 15, 1169–1181 - PubMed
-
- MacKinnon R., Cohen S. L., Kuo A., Lee A., Chait B. T. (1998) Science 280, 106–109 - PubMed
-
- Ohno M., Menez R., Ogawa T., Danse J. M., Shimohigashi Y., Fromen C., Ducancel F., Zinn-Justin S., Le Du M. H., Boulain J. C., Tamiya T., Menez A. (1998) Prog. Nucleic Acids Res. Mol. Biol. 59, 307–364 - PubMed
-
- Cousin X., Bon S., Massoulié J., Bon C. (1998) J. Biol. Chem. 273, 9812–9820 - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
