

'Unknown' proteins and 'orphan' enzymes: the missing half of the engineering parts list--and how to find it
- PMID: 20001958
- PMCID: PMC3022307
- DOI: 10.1042/BJ20091328
'Unknown' proteins and 'orphan' enzymes: the missing half of the engineering parts list--and how to find it
Abstract
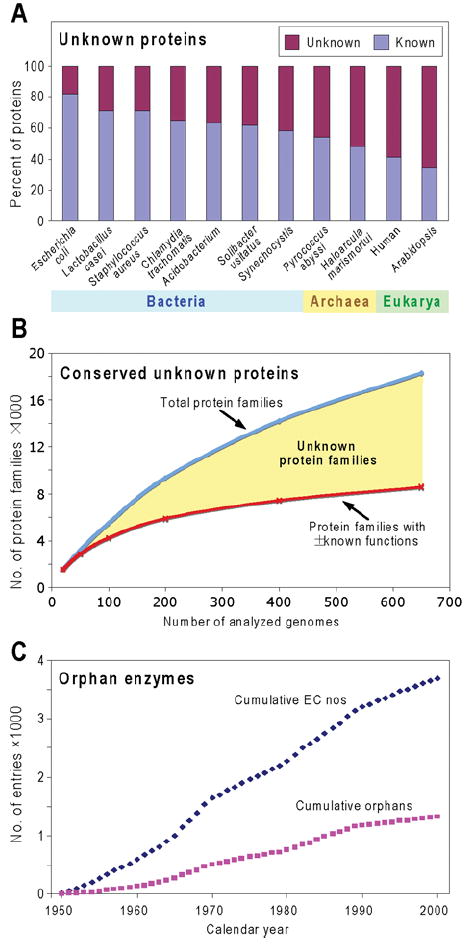
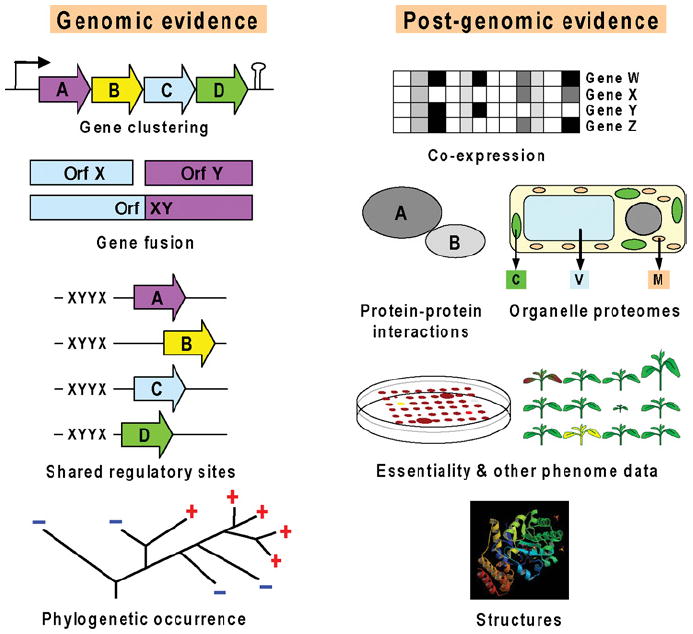
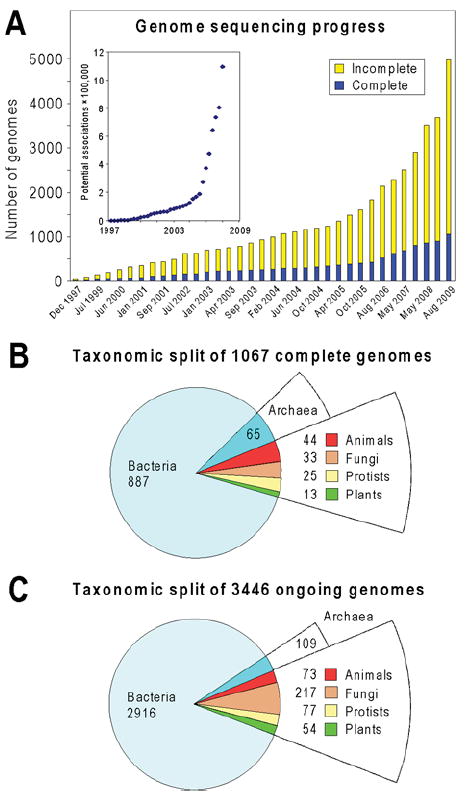
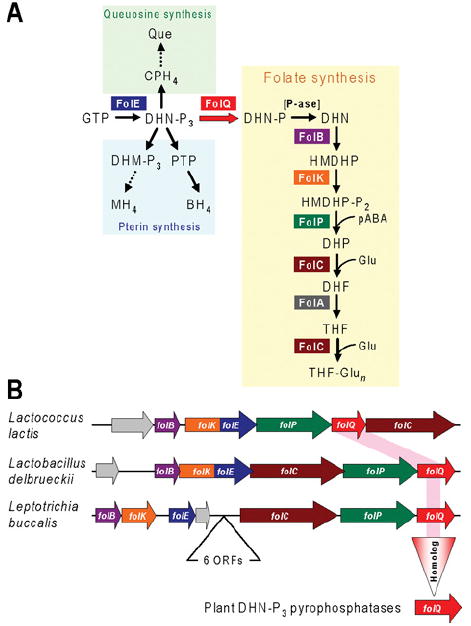
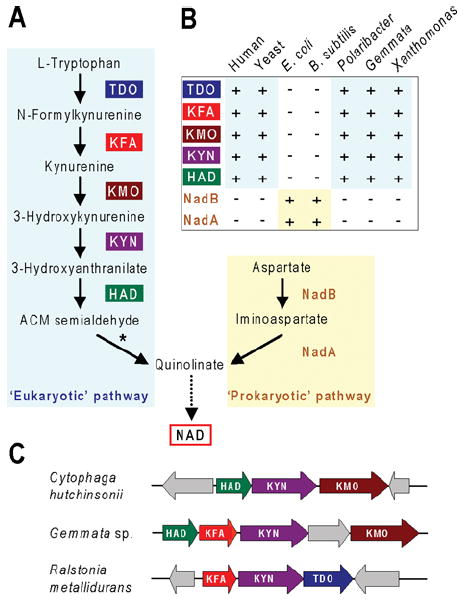
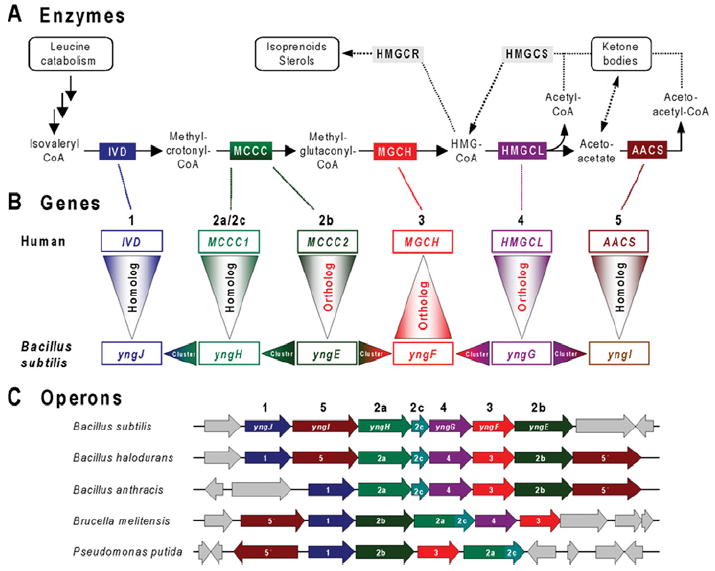
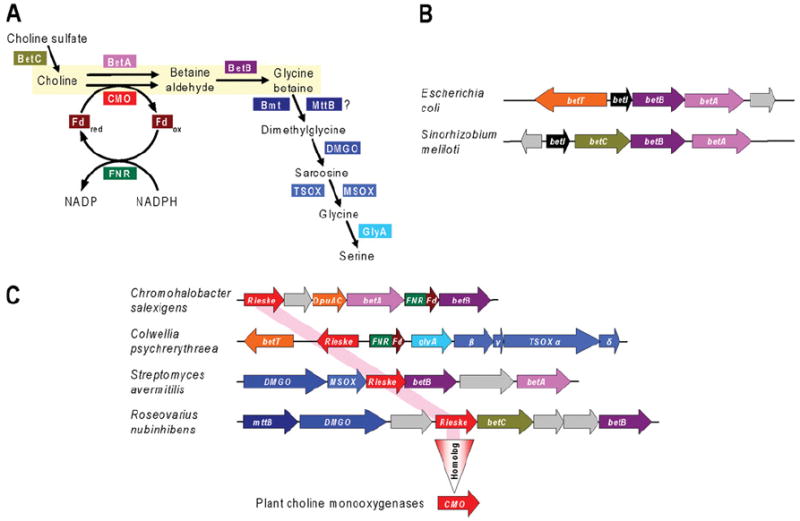
Like other forms of engineering, metabolic engineering requires knowledge of the components (the 'parts list') of the target system. Lack of such knowledge impairs both rational engineering design and diagnosis of the reasons for failures; it also poses problems for the related field of metabolic reconstruction, which uses a cell's parts list to recreate its metabolic activities in silico. Despite spectacular progress in genome sequencing, the parts lists for most organisms that we seek to manipulate remain highly incomplete, due to the dual problem of 'unknown' proteins and 'orphan' enzymes. The former are all the proteins deduced from genome sequence that have no known function, and the latter are all the enzymes described in the literature (and often catalogued in the EC database) for which no corresponding gene has been reported. Unknown proteins constitute up to about half of the proteins in prokaryotic genomes, and much more than this in higher plants and animals. Orphan enzymes make up more than a third of the EC database. Attacking the 'missing parts list' problem is accordingly one of the great challenges for post-genomic biology, and a tremendous opportunity to discover new facets of life's machinery. Success will require a co-ordinated community-wide attack, sustained over years. In this attack, comparative genomics is probably the single most effective strategy, for it can reliably predict functions for unknown proteins and genes for orphan enzymes. Furthermore, it is cost-efficient and increasingly straightforward to deploy owing to a proliferation of databases and associated tools.
Figures
References
-
- Stephanopoulos GN, Aristidou AA, Nielsen J. Metabolic Engineering: Principles and Methodologies. Academic Press; San Diego: 1998.
-
- Hanson AD, Shanks JV. Plant metabolic engineering: entering the S curve. Metab Eng. 2002;4:1–2.
-
- Capell T, Christou P. Progress in plant metabolic engineering. Curr Opin Biotechnol. 2004;15:148–154. - PubMed
-
- Wu S, Chappell J. Metabolic engineering of natural products in plants; tools of the trade and challenges for the future. Curr Opin Biotechnol. 2008;19:145–152. - PubMed
-
- Kunze R, Frommer WB, Flügge UI. Metabolic engineering of plants: the role of membrane transport. Metab Eng. 2002;4:57–66. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources