

Linguistic Summarization of Video for Fall Detection Using Voxel Person and Fuzzy Logic
- PMID: 20046216
- PMCID: PMC2630288
- DOI: 10.1016/j.cviu.2008.07.006
Linguistic Summarization of Video for Fall Detection Using Voxel Person and Fuzzy Logic
Abstract
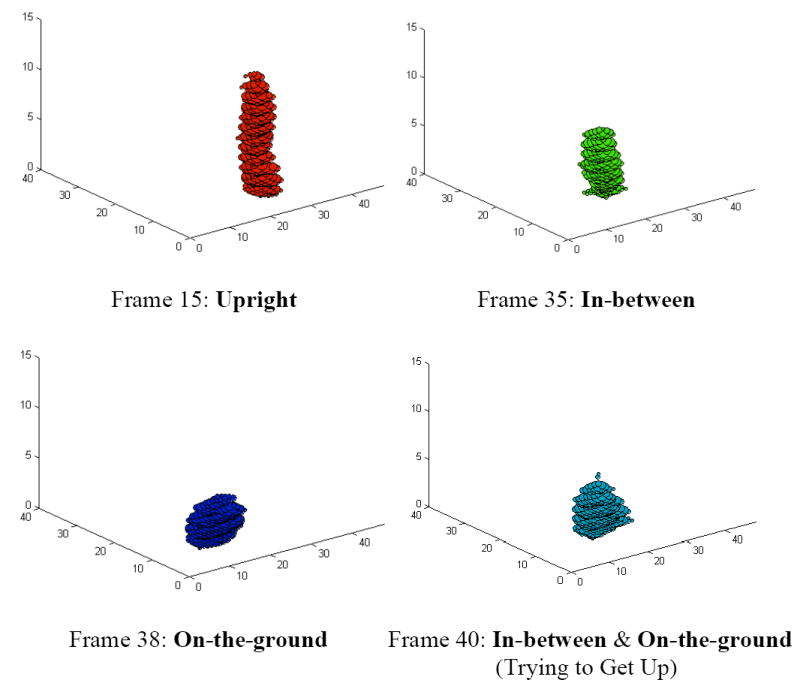
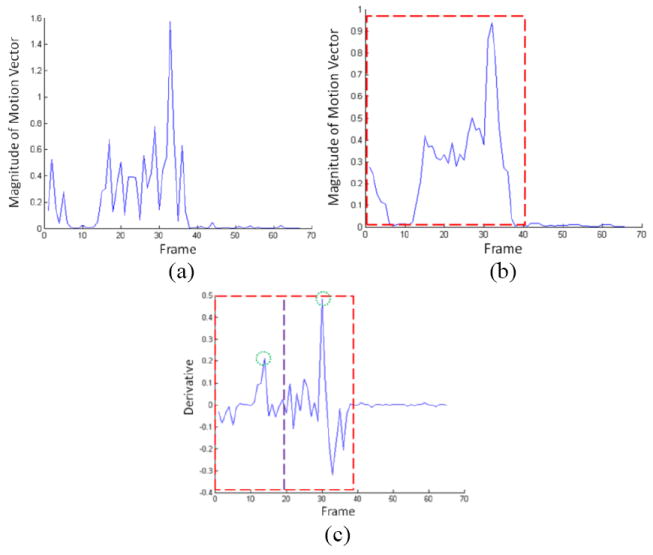
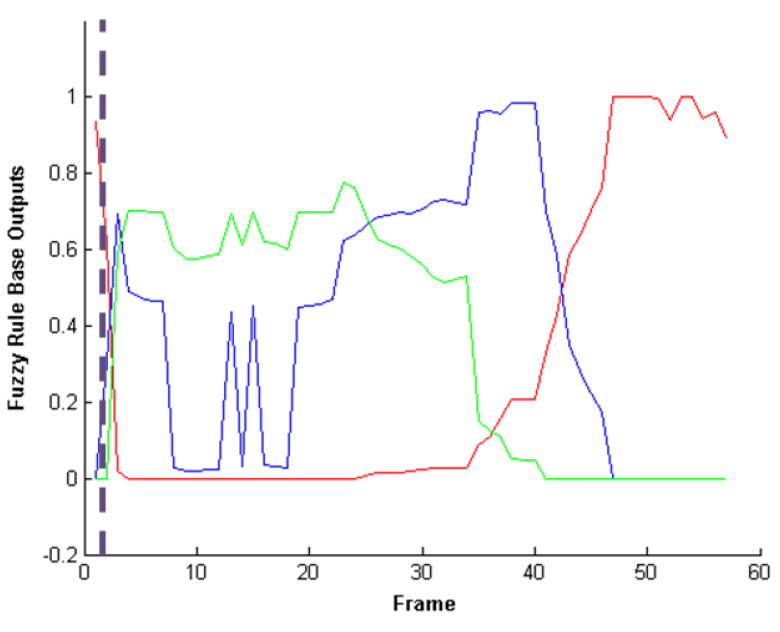
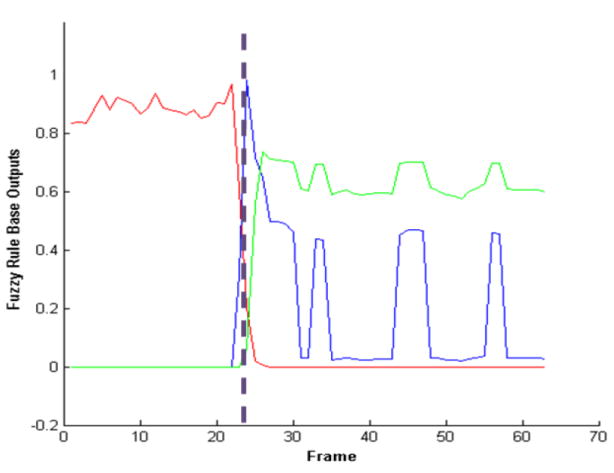
In this paper, we present a method for recognizing human activity from linguistic summarizations of temporal fuzzy inference curves representing the states of a three-dimensional object called voxel person. A hierarchy of fuzzy logic is used, where the output from each level is summarized and fed into the next level. We present a two level model for fall detection. The first level infers the states of the person at each image. The second level operates on linguistic summarizations of voxel person's states and inference regarding activity is performed. The rules used for fall detection were designed under the supervision of nurses to ensure that they reflect the manner in which elders perform these activities. The proposed framework is extremely flexible. Rules can be modified, added, or removed, allowing for per-resident customization based on knowledge about their cognitive and physical ability.
Figures





References
-
- Stauffer C, Grimson WEL. Learning patterns of activity using real-time tracking. IEEE Trans on Pattern Analysis and Machine Intelligence. 2000;22:747–757.
-
- Oliver NM, Rosario B, Pentland AP. A Bayesian Computer Vision System for Modeling Human Interactions. IEEE Tans on Pattern Analysis and Machine Intelligence. 2000;22:831–843.
-
- Toyama K, Krumm J, Brumitt B, Meyers B. Wallflower: principles and practice of background maintenance. Proceedings of the Seventh IEEE International Conference on Computer Vision. 1999;1:255–261.
-
- Luke RH, Anderson D, Keller JM, Skubic M. Moving Object Segmentation from Video Using Fused Color and Texture Features in Indoor Environments. Journal of Real-Time Image Processing. 2008
-
- Parag T, Elgammal A, Mittal A. A framework for feature selection for background subtraction. IEEE Computer Society Conf on Computer Vision and Pattern Recognition. 2006;2:1916–1923.
Grants and funding
LinkOut - more resources
Full Text Sources