

Averaging facial expression over time
- PMID: 20053064
- PMCID: PMC2857387
- DOI: 10.1167/9.11.1
Averaging facial expression over time
Abstract
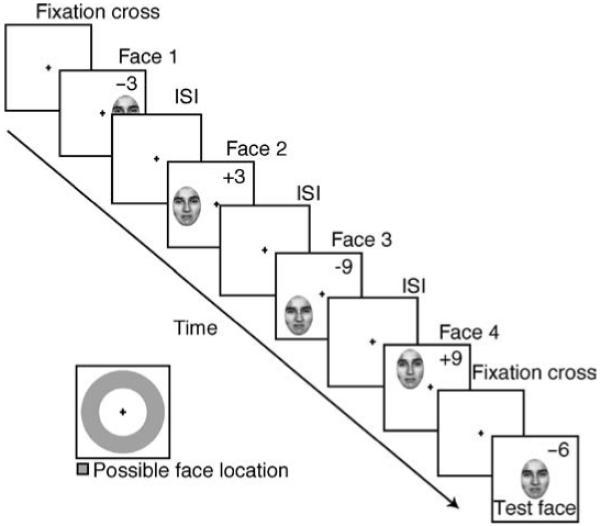
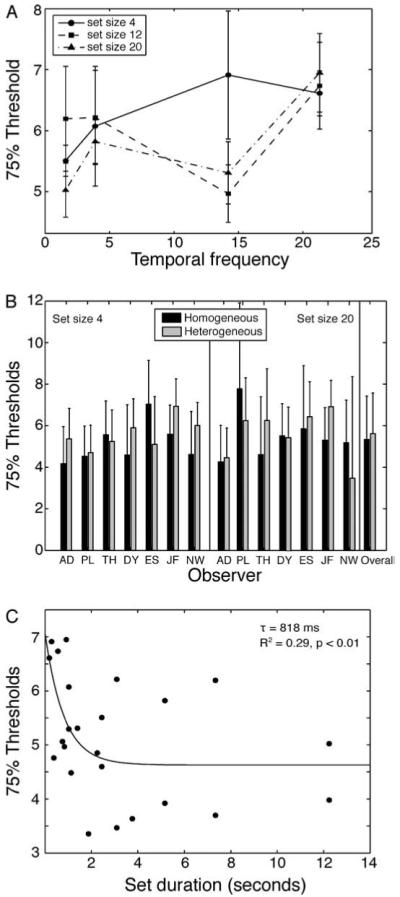
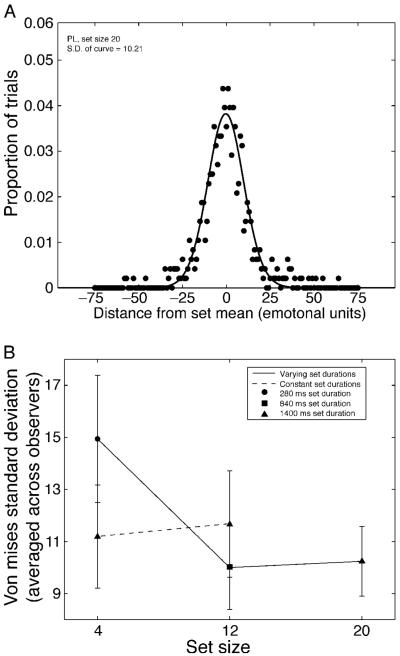
The visual system groups similar features, objects, and motion (e.g., Gestalt grouping). Recent work suggests that the computation underlying perceptual grouping may be one of summary statistical representation. Summary representation occurs for low-level features, such as size, motion, and position, and even for high level stimuli, including faces; for example, observers accurately perceive the average expression in a group of faces (J. Haberman & D. Whitney, 2007, 2009). The purpose of the present experiments was to characterize the time-course of this facial integration mechanism. In a series of three experiments, we measured observers' abilities to recognize the average expression of a temporal sequence of distinct faces. Faces were presented in sets of 4, 12, or 20, at temporal frequencies ranging from 1.6 to 21.3 Hz. The results revealed that observers perceived the average expression in a temporal sequence of different faces as precisely as they perceived a single face presented repeatedly. The facial averaging was independent of temporal frequency or set size, but depended on the total duration of exposed faces, with a time constant of approximately 800 ms. These experiments provide evidence that the visual system is sensitive to the ensemble characteristics of complex objects presented over time.
Figures

References
-
- Albrecht A, Scholl B. Perceptually averaging in a continuous world: Extracting statistical summary representations over times. Psychological Science. in press. - PubMed
-
- Ariely D. Seeing sets: Representation by statistical properties. Psychological Science. 2001;12:157–162. - PubMed
-
- Beck J. Textural segmentation, 2nd-order statistics, and textural elements. Biological Cybernetics. 1983;48:125–130. - PubMed
-
- Blake R, Lee SH. The role of temporal structure in human vision. Behavioural Cognitive Neuroscience Review. 2005;4:21–42. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
