

Comparative Study
doi: 10.1093/bioinformatics/btq003.
Epub 2010 Jan 6.
CD-HIT Suite: a web server for clustering and comparing biological sequences
Affiliations
- PMID: 20053844
- PMCID: PMC2828112
- DOI: 10.1093/bioinformatics/btq003
Item in Clipboard
Comparative Study
CD-HIT Suite: a web server for clustering and comparing biological sequences
Bioinformatics.
.
Abstract
CD-HIT is a widely used program for clustering and comparing large biological sequence datasets. In order to further assist the CD-HIT users, we significantly improved this program with more functions and better accuracy, scalability and flexibility. Most importantly, we developed a new web server, CD-HIT Suite, for clustering a user-uploaded sequence dataset or comparing it to another dataset at different identity levels. Users can now interactively explore the clusters within web browsers. We also provide downloadable clusters for several public databases (NCBI NR, Swissprot and PDB) at different identity levels.
Availability: Free access at http://cd-hit.org
Figures
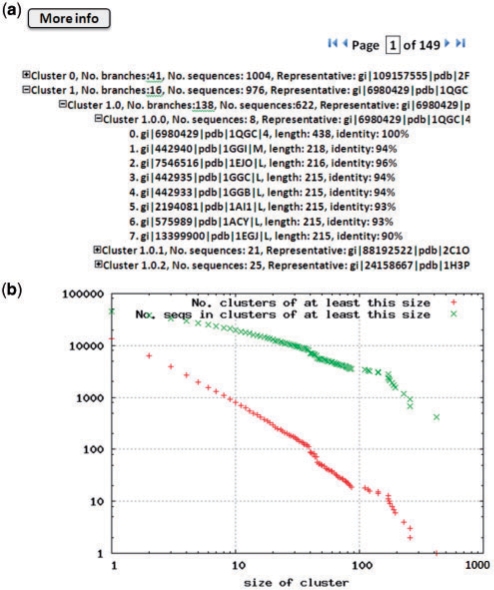
Screenshots of CD-HIT Suite. (a) Cluster Explorer for investigating clusters. (b) A cluster distribution plot to explore the global structure of a whole dataset.
References
-
- Li W, Godzik A. Cd-hit: a fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics. 2006;22:1658–1659. - PubMed
-
- Li W, et al. Clustering of highly homologous sequences to reduce the size of large protein databases. Bioinformatics. 2001;17:282–283. - PubMed
-
- Li W, et al. Tolerating some redundancy significantly speeds up clustering of large protein databases. Bioinformatics. 2002;18:77–82. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
