

Integrated approach for the identification of human hepatocyte nuclear factor 4alpha target genes using protein binding microarrays
- PMID: 20054869
- PMCID: PMC3581146
- DOI: 10.1002/hep.23357
Integrated approach for the identification of human hepatocyte nuclear factor 4alpha target genes using protein binding microarrays
Abstract
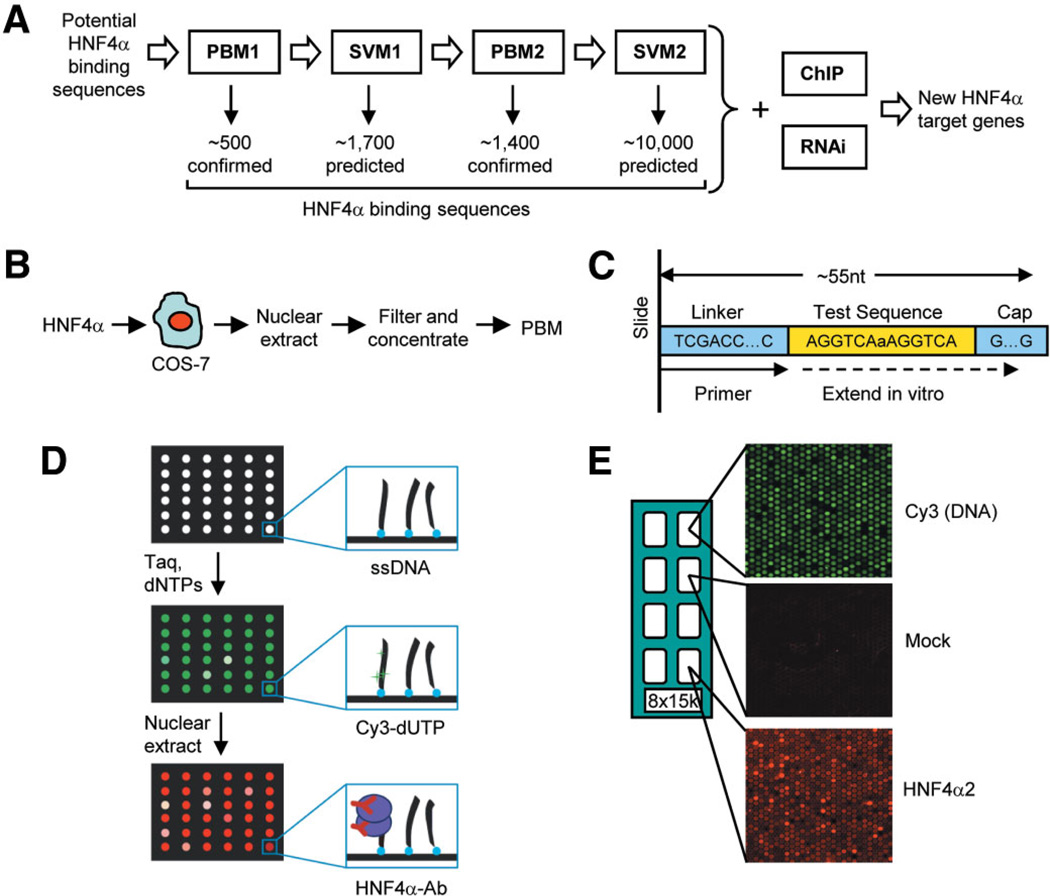
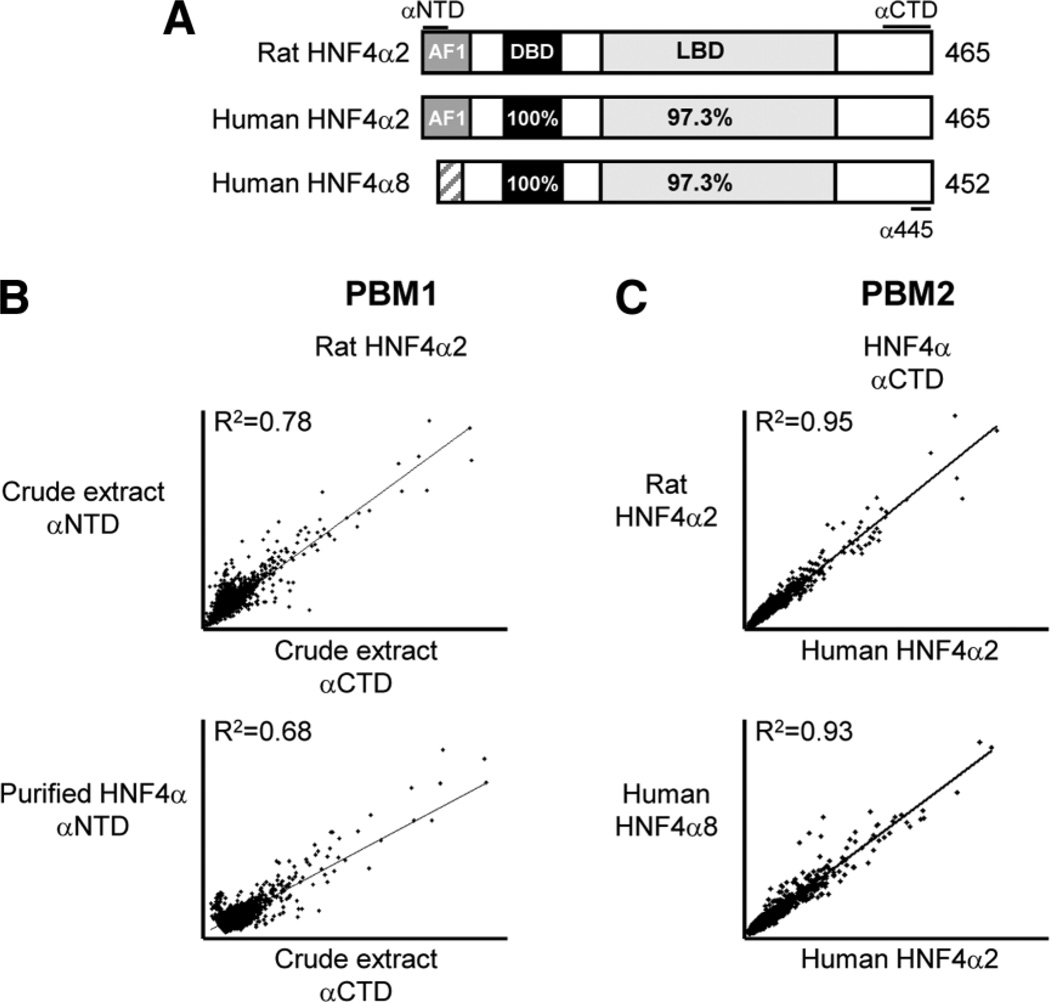
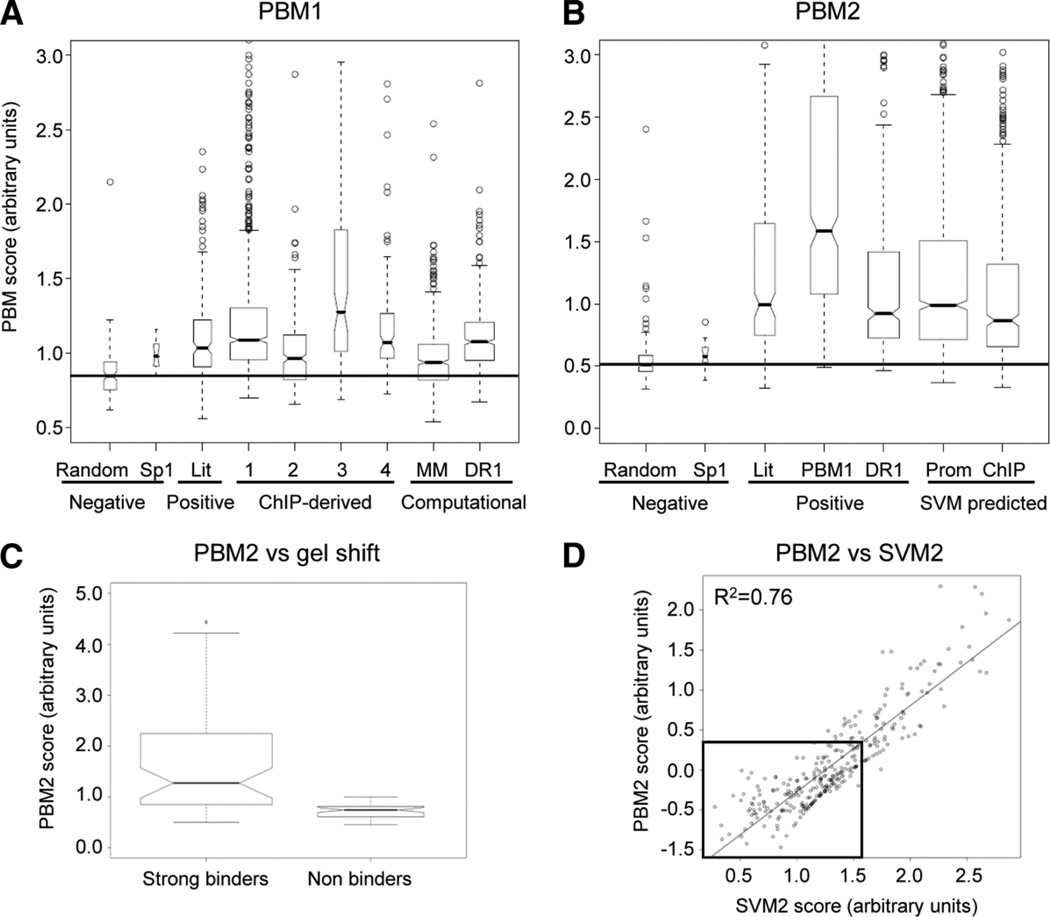
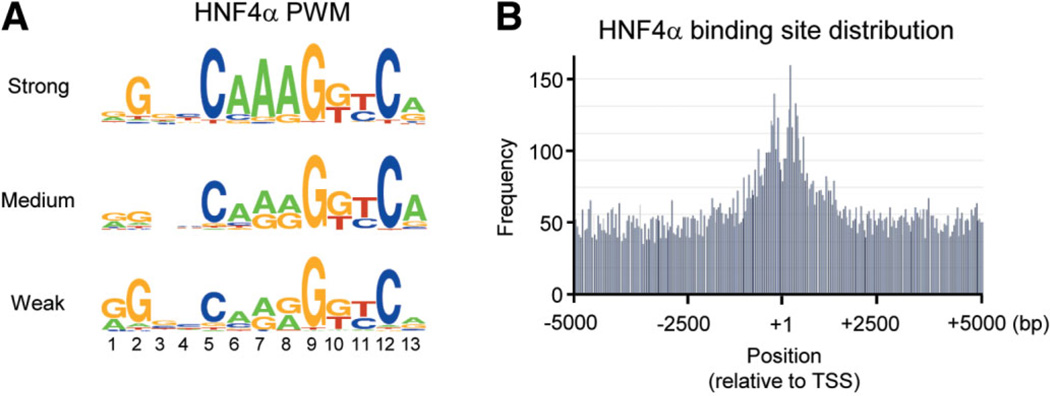
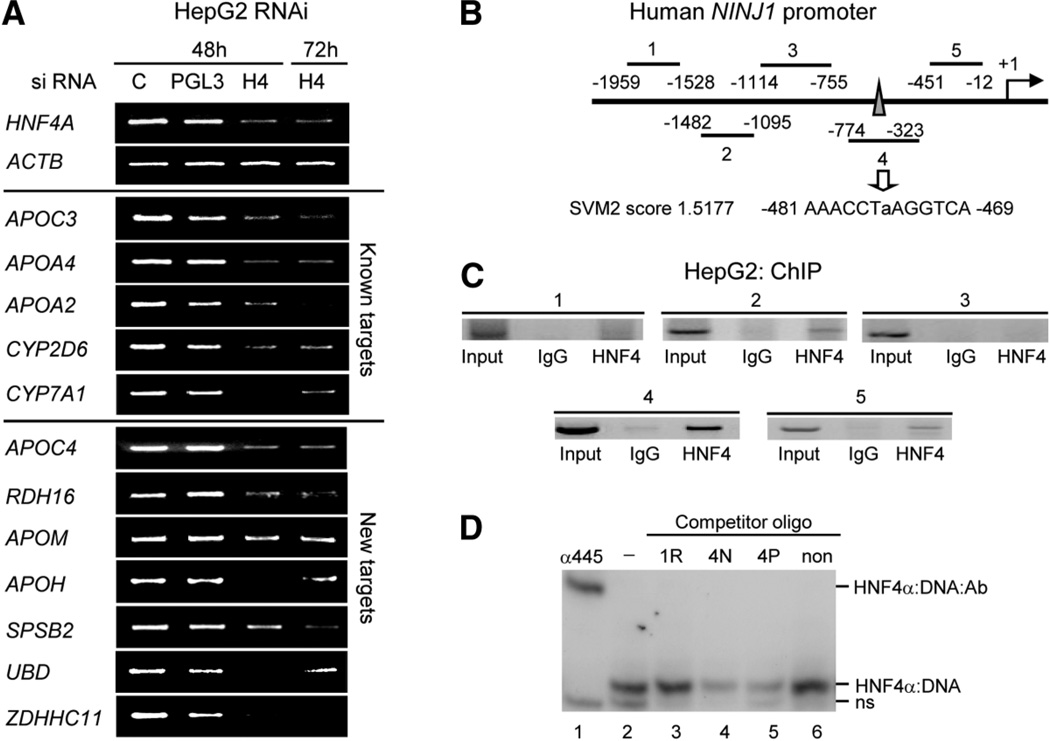
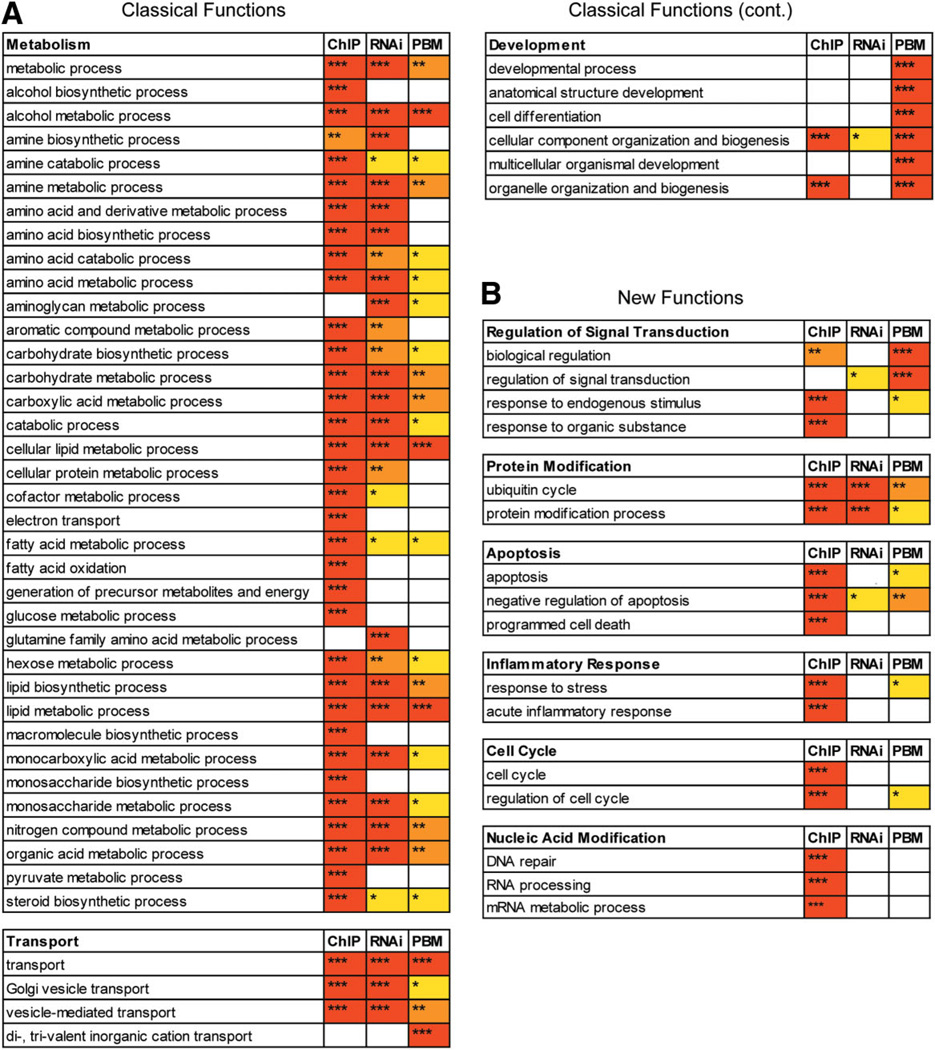
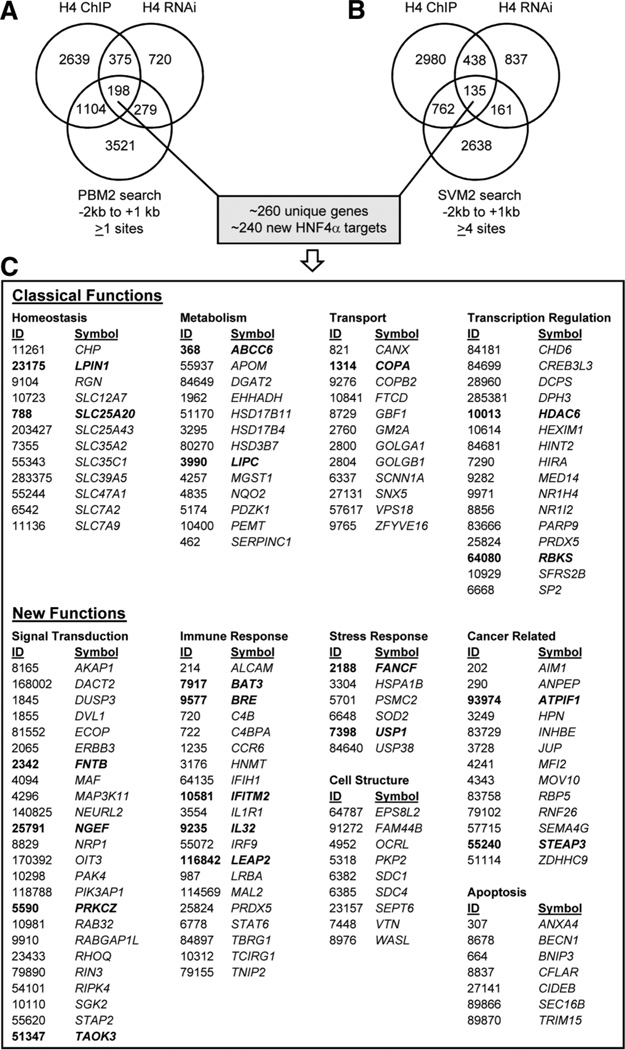
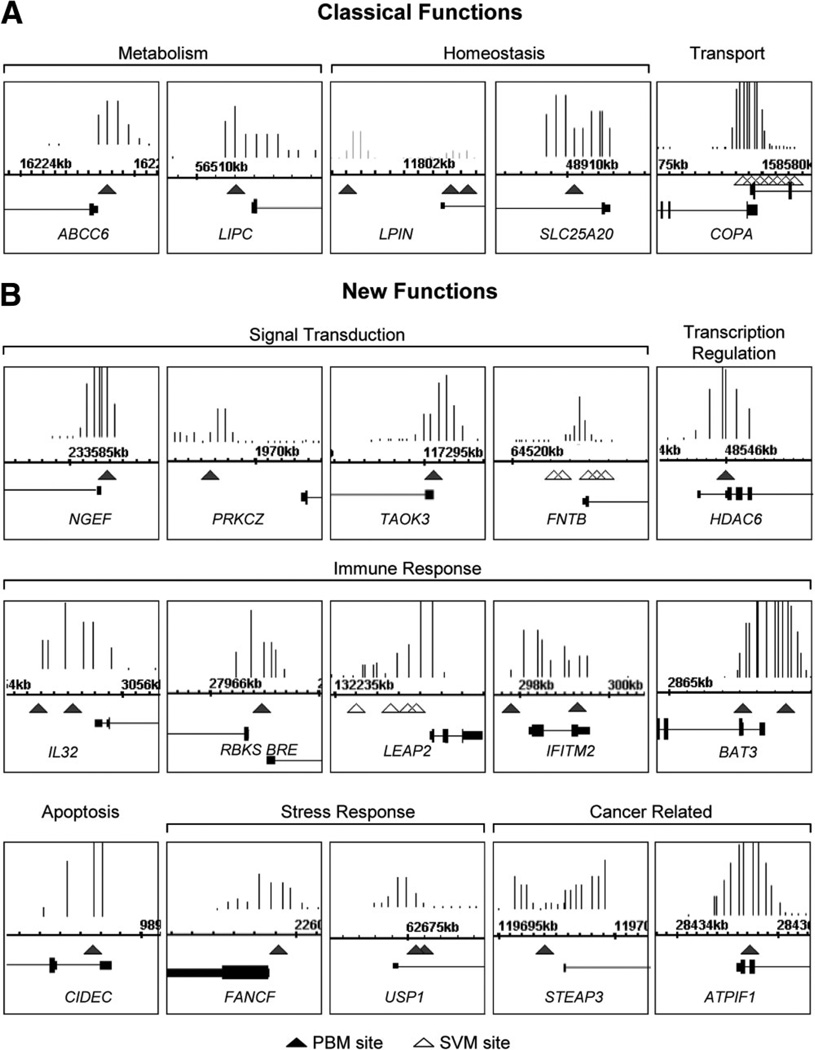
Hepatocyte nuclear factor 4 alpha (HNF4alpha), a member of the nuclear receptor superfamily, is essential for liver function and is linked to several diseases including diabetes, hemophilia, atherosclerosis, and hepatitis. Although many DNA response elements and target genes have been identified for HNF4alpha, the complete repertoire of binding sites and target genes in the human genome is unknown. Here, we adapt protein binding microarrays (PBMs) to examine the DNA-binding characteristics of two HNF4alpha species (rat and human) and isoforms (HNF4alpha2 and HNF4alpha8) in a high-throughput fashion. We identified approximately 1400 new binding sequences and used this dataset to successfully train a Support Vector Machine (SVM) model that predicts an additional approximately 10,000 unique HNF4alpha-binding sequences; we also identify new rules for HNF4alpha DNA binding. We performed expression profiling of an HNF4alpha RNA interference knockdown in HepG2 cells and compared the results to a search of the promoters of all human genes with the PBM and SVM models, as well as published genome-wide location analysis. Using this integrated approach, we identified approximately 240 new direct HNF4alpha human target genes, including new functional categories of genes not typically associated with HNF4alpha, such as cell cycle, immune function, apoptosis, stress response, and other cancer-related genes.
Conclusion: We report the first use of PBMs with a full-length liver-enriched transcription factor and greatly expand the repertoire of HNF4alpha-binding sequences and target genes, thereby identifying new functions for HNF4alpha. We also establish a web-based tool, HNF4 Motif Finder, that can be used to identify potential HNF4alpha-binding sites in any sequence.
Conflict of interest statement
Potential conflict of interest: Nothing to report.
Figures
Comment in
-
Making the liver what it is: the many targets of the transcriptional regulator HNF4alpha.Hepatology. 2010 Feb;51(2):376-7. doi: 10.1002/hep.23487. Hepatology. 2010. PMID: 20101744 No abstract available.
References
-
- Bolotin E, Schnabl J, Sladek F. HNF4A (Homo sapiens) Transcription Factor Encyclopedia. 2009 http://www.cisreg.ca/tfe.
-
- Sladek FM, Zhong WM, Lai E, Darnell JE., Jr Liver-enriched transcription factor HNF-4 is a novel member of the steroid hormone receptor superfamily. Genes Dev. 1990;4:2353–2365. - PubMed
-
- Watt AJ, Garrison WD, Duncan SA. HNF4: a central regulator of hepatocyte differentiation and function. Hepatology. 2003;37:1249–1253. - PubMed
-
- Gupta RK, Kaestner KH. HNF-4alpha: from MODY to late-onset type 2 diabetes. Trends Mol Med. 2004;10:521–524. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases