

Estimates of sensitivity and specificity can be biased when reporting the results of the second test in a screening trial conducted in series
- PMID: 20064254
- PMCID: PMC2819240
- DOI: 10.1186/1471-2288-10-3
Estimates of sensitivity and specificity can be biased when reporting the results of the second test in a screening trial conducted in series
Abstract
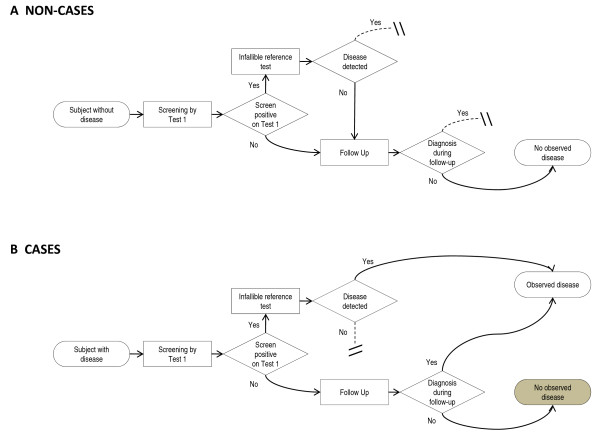
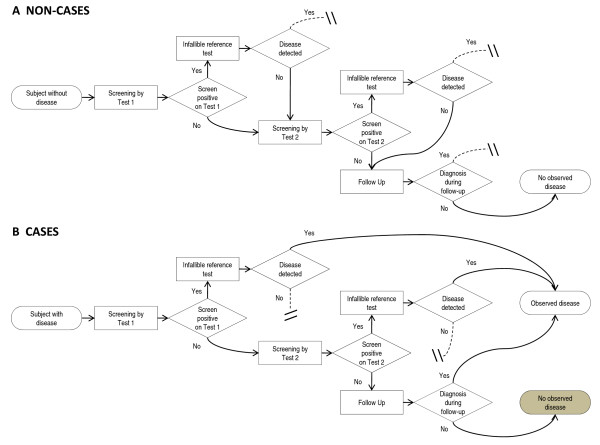
Background: Cancer screening reduces cancer mortality when early detection allows successful treatment of otherwise fatal disease. There are a variety of trial designs used to find the best screening test. In a series screening trial design, the decision to conduct the second test is based on the results of the first test. Thus, the estimates of diagnostic accuracy for the second test are conditional, and may differ from unconditional estimates. The problem is further complicated when some cases are misclassified as non-cases due to incomplete disease status ascertainment.
Methods: For a series design, we assume that the second screening test is conducted only if the first test had negative results. We derive formulae for the conditional sensitivity and specificity of the second test in the presence of differential verification bias. For comparison, we also derive formulae for the sensitivity and specificity for a single test design, both with and without differential verification bias.
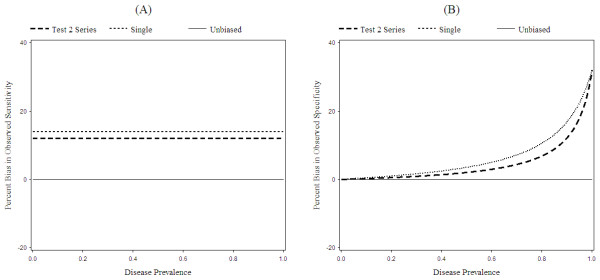
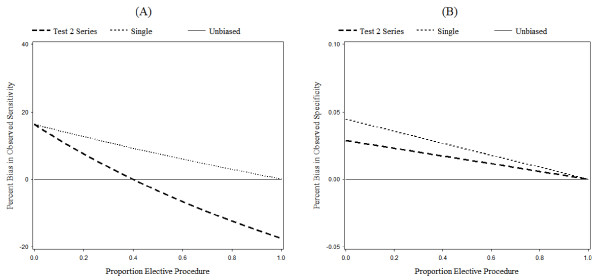
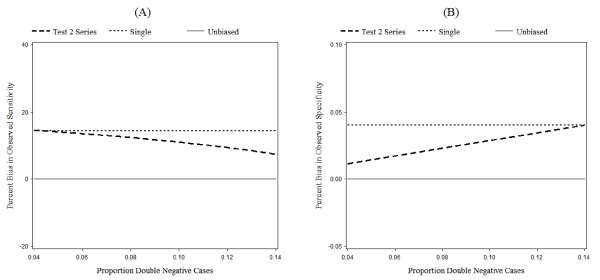
Results: Both the series design and differential verification bias have strong effects on estimates of sensitivity and specificity. In both the single test and series designs, differential verification bias inflates estimates of sensitivity and specificity. In general, for the series design, the inflation is smaller than that observed for a single test design.The degree of bias depends on disease prevalence, the proportion of misclassified cases, and on the correlation between the test results for cases. As disease prevalence increases, the observed conditional sensitivity is unaffected. However, there is an increasing upward bias in observed conditional specificity. As the proportion of correctly classified cases increases, the upward bias in observed conditional sensitivity and specificity decreases. As the agreement between the two screening tests becomes stronger, the upward bias in observed conditional sensitivity decreases, while the specificity bias increases.
Conclusions: In a series design, estimates of sensitivity and specificity for the second test are conditional estimates. These estimates must always be described in context of the design of the trial, and the study population, to prevent misleading comparisons. In addition, these estimates may be biased by incomplete disease status ascertainment.
Figures
Similar articles
-
Bias in estimating accuracy of a binary screening test with differential disease verification.Stat Med. 2011 Jul 10;30(15):1852-64. doi: 10.1002/sim.4232. Epub 2011 Apr 15. Stat Med. 2011. PMID: 21495059 Free PMC article.
-
Bias in trials comparing paired continuous tests can cause researchers to choose the wrong screening modality.BMC Med Res Methodol. 2009 Jan 20;9:4. doi: 10.1186/1471-2288-9-4. BMC Med Res Methodol. 2009. PMID: 19154609 Free PMC article.
-
Avoiding verification bias in screening test evaluation in resource poor settings: a case study from Zimbabwe.Clin Trials. 2008;5(5):496-503. doi: 10.1177/1740774508096139. Clin Trials. 2008. PMID: 18827042
-
Thoracic imaging tests for the diagnosis of COVID-19.Cochrane Database Syst Rev. 2020 Nov 26;11:CD013639. doi: 10.1002/14651858.CD013639.pub3. Cochrane Database Syst Rev. 2020. Update in: Cochrane Database Syst Rev. 2021 Mar 16;3:CD013639. doi: 10.1002/14651858.CD013639.pub4. PMID: 33242342 Updated.
-
The use of "overall accuracy" to evaluate the validity of screening or diagnostic tests.J Gen Intern Med. 2004 May;19(5 Pt 1):460-5. doi: 10.1111/j.1525-1497.2004.30091.x. J Gen Intern Med. 2004. PMID: 15109345 Free PMC article. Review.
Cited by
-
Reducing decision errors in the paired comparison of the diagnostic accuracy of screening tests with Gaussian outcomes.BMC Med Res Methodol. 2014 Mar 5;14:37. doi: 10.1186/1471-2288-14-37. BMC Med Res Methodol. 2014. PMID: 24597517 Free PMC article.
-
A review of methods for the analysis of diagnostic tests performed in sequence.Diagn Progn Res. 2024 Sep 3;8(1):8. doi: 10.1186/s41512-024-00175-3. Diagn Progn Res. 2024. PMID: 39223640 Free PMC article. Review.
-
Bias in Laboratory Medicine: The Dark Side of the Moon.Ann Lab Med. 2024 Jan 1;44(1):6-20. doi: 10.3343/alm.2024.44.1.6. Epub 2023 Sep 4. Ann Lab Med. 2024. PMID: 37665281 Free PMC article. Review.
-
Bias in estimating accuracy of a binary screening test with differential disease verification.Stat Med. 2011 Jul 10;30(15):1852-64. doi: 10.1002/sim.4232. Epub 2011 Apr 15. Stat Med. 2011. PMID: 21495059 Free PMC article.
References
-
- Breast Cancer: Statistics, Center for Disease Control (CDC) and Prevention Homepage. http://www.cdc.gov/cancer/breast/statistics/
-
- Hendrick RE. Benefit of screening mammography in women aged 40-49: a new meta-analysis of randomized controlled trials. J Natl Cancer I Mono. 1997;22:87–92. - PubMed
-
- Lewin JM, Hendrick RE, D'Orsi CJ, Isaacs PK, Moss LJ, Karellas A, Sisney GA, Kuni CC, Cutter GR. Comparison of full-field digital mammography with screenfilm mammography for cancer detection: results of 4,945 paired examinations. Radiology. 2001;218:873–880. - PubMed
-
- Lehman CD, Gatsonis C, Kuhl CK, Hendrick RE, Pisano ED, Hanna L, Peacock S, Smazal SF, Maki DD, Julian TB, DePeri ER, Bluemke DA, Schnall MD. for the ACRIN Trial 6667 Investigators Group. MRI evaluation of the contralateral breast in women with recently diagnosed breast cancer. N Engl J Med. 2007;356:1295–1303. doi: 10.1056/NEJMoa065447. - DOI - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
