

How the human brain recognizes speech in the context of changing speakers
- PMID: 20071527
- PMCID: PMC2824128
- DOI: 10.1523/JNEUROSCI.2742-09.2010
How the human brain recognizes speech in the context of changing speakers
Abstract
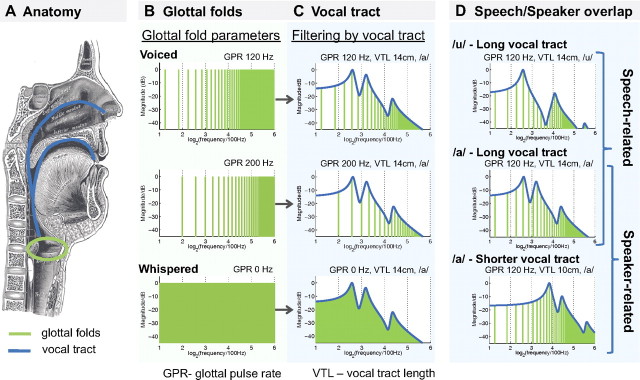
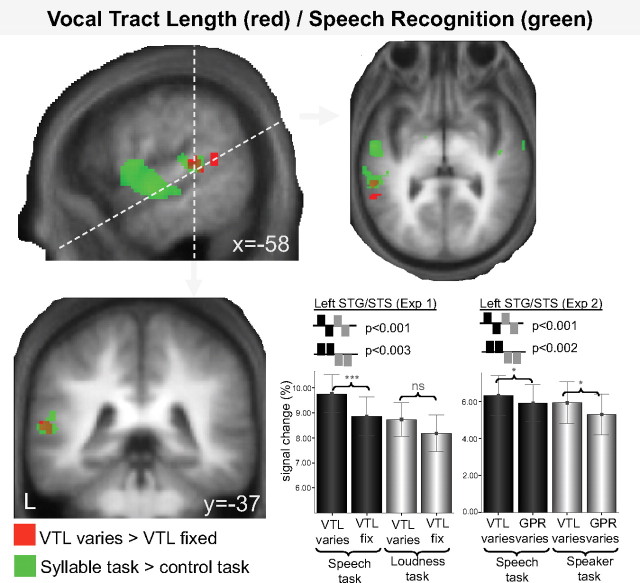
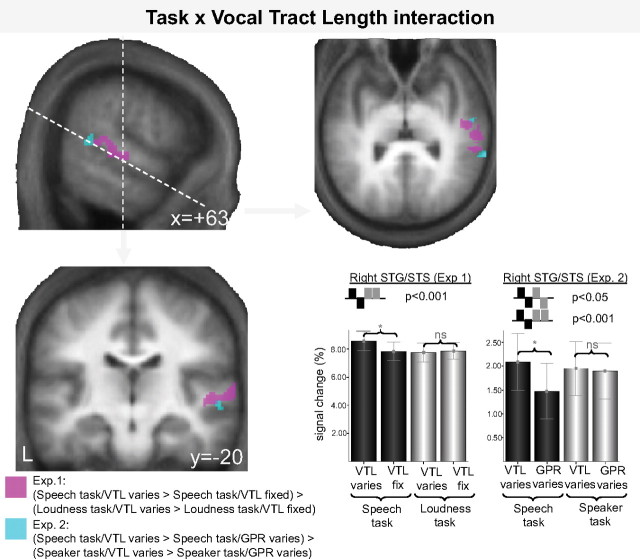
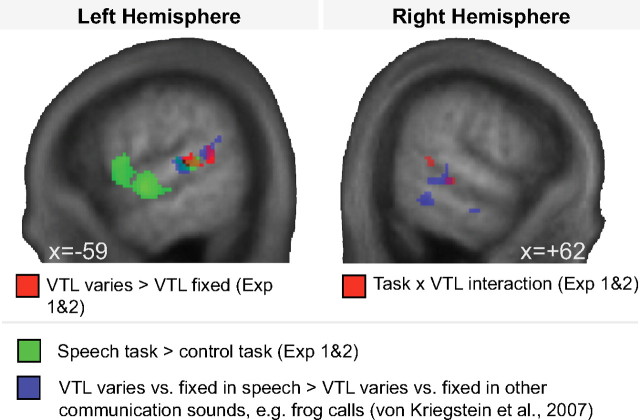
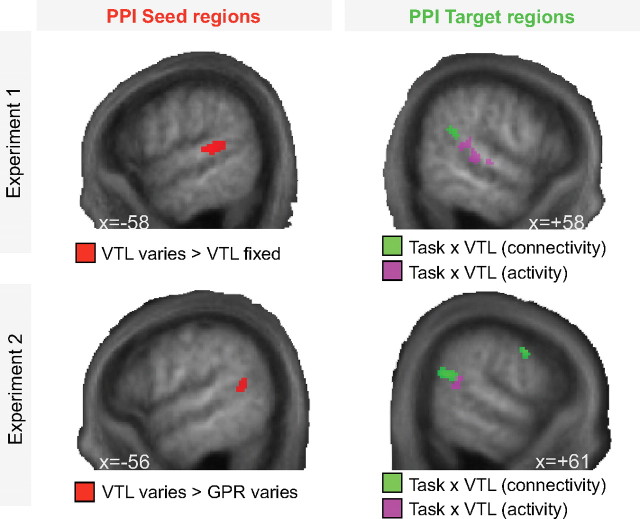
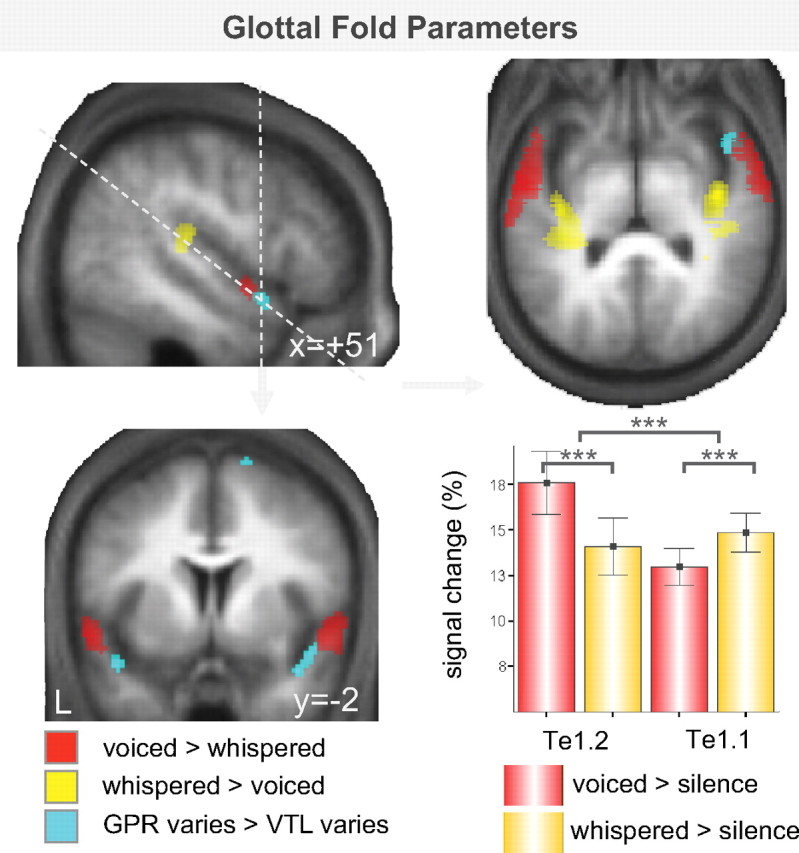
We understand speech from different speakers with ease, whereas artificial speech recognition systems struggle with this task. It is unclear how the human brain solves this problem. The conventional view is that speech message recognition and speaker identification are two separate functions and that message processing takes place predominantly in the left hemisphere, whereas processing of speaker-specific information is located in the right hemisphere. Here, we distinguish the contribution of specific cortical regions, to speech recognition and speaker information processing, by controlled manipulation of task and resynthesized speaker parameters. Two functional magnetic resonance imaging studies provide evidence for a dynamic speech-processing network that questions the conventional view. We found that speech recognition regions in left posterior superior temporal gyrus/superior temporal sulcus (STG/STS) also encode speaker-related vocal tract parameters, which are reflected in the amplitude peaks of the speech spectrum, along with the speech message. Right posterior STG/STS activated specifically more to a speaker-related vocal tract parameter change during a speech recognition task compared with a voice recognition task. Left and right posterior STG/STS were functionally connected. Additionally, we found that speaker-related glottal fold parameters (e.g., pitch), which are not reflected in the amplitude peaks of the speech spectrum, are processed in areas immediately adjacent to primary auditory cortex, i.e., in areas in the auditory hierarchy earlier than STG/STS. Our results point to a network account of speech recognition, in which information about the speech message and the speaker's vocal tract are combined to solve the difficult task of understanding speech from different speakers.
Figures
Similar articles
-
A neural mechanism for recognizing speech spoken by different speakers.Neuroimage. 2014 May 1;91:375-85. doi: 10.1016/j.neuroimage.2014.01.005. Epub 2014 Jan 13. Neuroimage. 2014. PMID: 24434677
-
Task-dependent decoding of speaker and vowel identity from auditory cortical response patterns.J Neurosci. 2014 Mar 26;34(13):4548-57. doi: 10.1523/JNEUROSCI.4339-13.2014. J Neurosci. 2014. PMID: 24672000 Free PMC article.
-
A multisensory cortical network for understanding speech in noise.J Cogn Neurosci. 2009 Sep;21(9):1790-805. doi: 10.1162/jocn.2009.21118. J Cogn Neurosci. 2009. PMID: 18823249 Free PMC article.
-
Stimulus-dependent activations and attention-related modulations in the auditory cortex: a meta-analysis of fMRI studies.Hear Res. 2014 Jan;307:29-41. doi: 10.1016/j.heares.2013.08.001. Epub 2013 Aug 11. Hear Res. 2014. PMID: 23938208 Review.
-
How do we recognise who is speaking?Front Biosci (Schol Ed). 2014 Jan 1;6(1):92-109. doi: 10.2741/s417. Front Biosci (Schol Ed). 2014. PMID: 24389264 Review.
Cited by
-
The Role of the Right Hemisphere in Processing Phonetic Variability Between Talkers.Neurobiol Lang (Camb). 2021 Feb 1;2(1):138-151. doi: 10.1162/nol_a_00028. eCollection 2021. Neurobiol Lang (Camb). 2021. PMID: 37213418 Free PMC article. Review.
-
Investigating the neural correlates of voice versus speech-sound directed information in pre-school children.PLoS One. 2014 Dec 22;9(12):e115549. doi: 10.1371/journal.pone.0115549. eCollection 2014. PLoS One. 2014. PMID: 25532132 Free PMC article.
-
Using TMS to evaluate a causal role for right posterior temporal cortex in talker-specific phonetic processing.Brain Lang. 2023 May;240:105264. doi: 10.1016/j.bandl.2023.105264. Epub 2023 Apr 21. Brain Lang. 2023. PMID: 37087863 Free PMC article.
-
Mouth and Voice: A Relationship between Visual and Auditory Preference in the Human Superior Temporal Sulcus.J Neurosci. 2017 Mar 8;37(10):2697-2708. doi: 10.1523/JNEUROSCI.2914-16.2017. Epub 2017 Feb 8. J Neurosci. 2017. PMID: 28179553 Free PMC article.
-
Voice-sensitive brain networks encode talker-specific phonetic detail.Brain Lang. 2017 Feb;165:33-44. doi: 10.1016/j.bandl.2016.11.001. Epub 2016 Nov 27. Brain Lang. 2017. PMID: 27898342 Free PMC article.
References
-
- Abercrombie D. Edinburgh: Edinburgh UP; 1967. Elements of general phonetics.
-
- Adank P, van Hout R, Smits R. An acoustic description of the vowels of Northern and Southern Standard Dutch. J Acoust Soc Am. 2004;116:1729–1738. - PubMed
-
- Ames H, Grossberg S. Speaker normalization using cortical strip maps: a neural model for steady-state vowel categorization. J Acoust Soc Am. 2008;124:3918–3936. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources