

Author Name Disambiguation in MEDLINE
- PMID: 20072710
- PMCID: PMC2805000
- DOI: 10.1145/1552303.1552304
Author Name Disambiguation in MEDLINE
Abstract
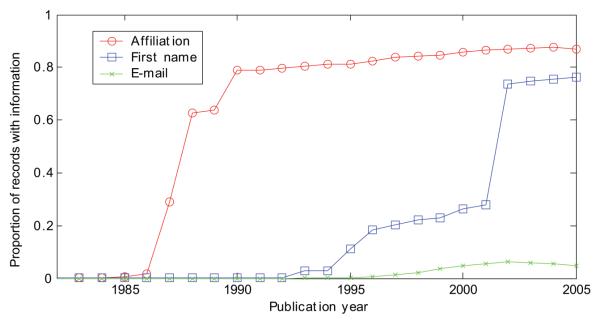
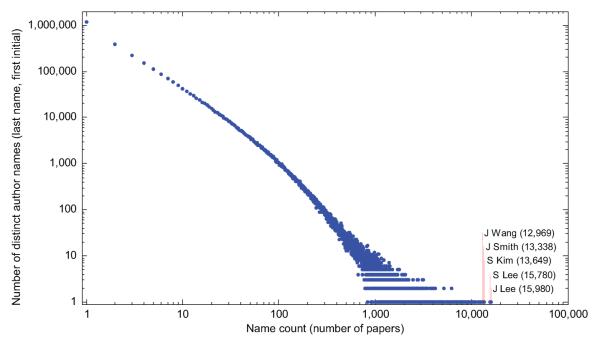
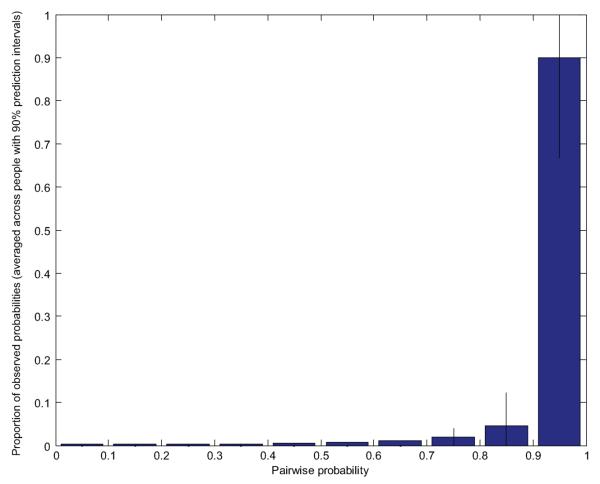
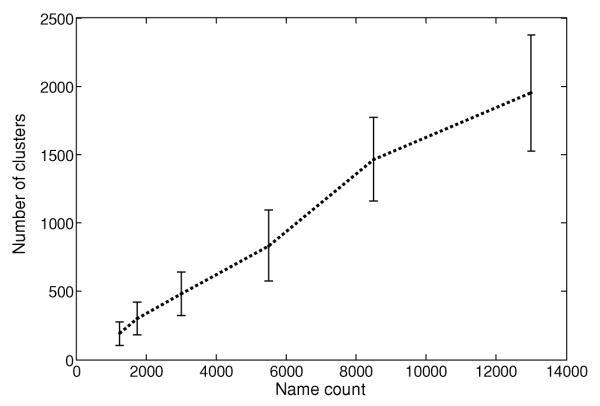
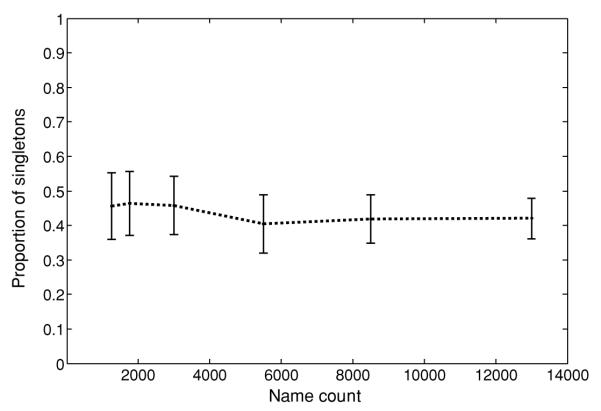
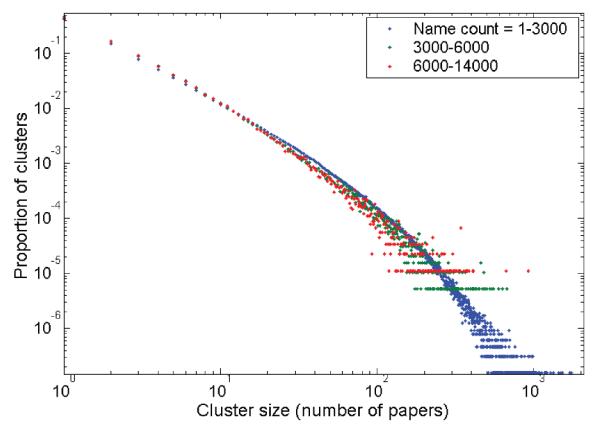
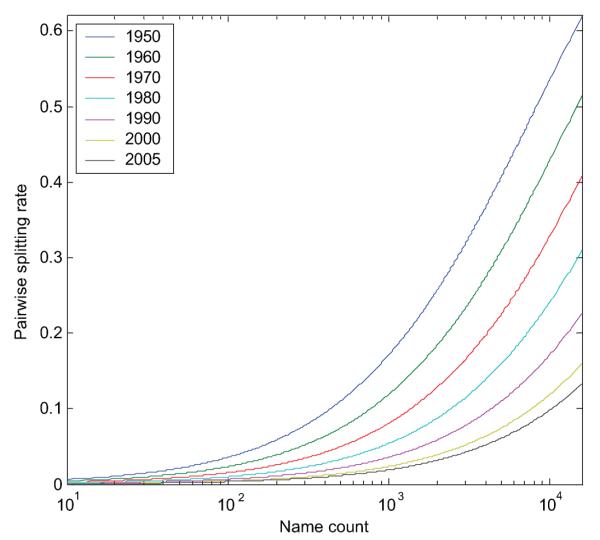
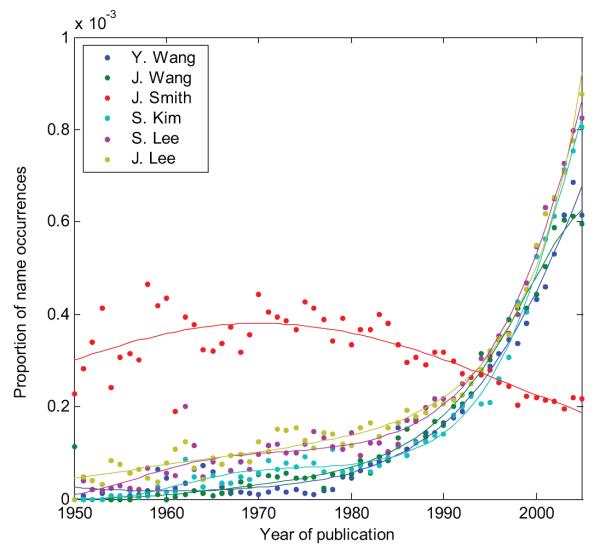
BACKGROUND: We recently described "Author-ity," a model for estimating the probability that two articles in MEDLINE, sharing the same author name, were written by the same individual. Features include shared title words, journal name, coauthors, medical subject headings, language, affiliations, and author name features (middle initial, suffix, and prevalence in MEDLINE). Here we test the hypothesis that the Author-ity model will suffice to disambiguate author names for the vast majority of articles in MEDLINE. METHODS: Enhancements include: (a) incorporating first names and their variants, email addresses, and correlations between specific last names and affiliation words; (b) new methods of generating large unbiased training sets; (c) new methods for estimating the prior probability; (d) a weighted least squares algorithm for correcting transitivity violations; and (e) a maximum likelihood based agglomerative algorithm for computing clusters of articles that represent inferred author-individuals. RESULTS: Pairwise comparisons were computed for all author names on all 15.3 million articles in MEDLINE (2006 baseline), that share last name and first initial, to create Author-ity 2006, a database that has each name on each article assigned to one of 6.7 million inferred author-individual clusters. Recall is estimated at ~98.8%. Lumping (putting two different individuals into the same cluster) affects ~0.5% of clusters, whereas splitting (assigning articles written by the same individual to >1 cluster) affects ~2% of articles. IMPACT: The Author-ity model can be applied generally to other bibliographic databases. Author name disambiguation allows information retrieval and data integration to become person-centered, not just document-centered, setting the stage for new data mining and social network tools that will facilitate the analysis of scholarly publishing and collaboration behavior. AVAILABILITY: The Author-ity 2006 database is available for nonprofit academic research, and can be freely queried via http://arrowsmith.psych.uic.edu.
Figures
References
-
- Bhattacharya I, Getoor L. A latent Dirichlet model for unsupervised entity resolution. In: Ghosh J, Lambert D, Skillicorn DB, Srivastava J, editors. Proceedings of the 6th SIAM Conference on Data Mining; SIAM; 2006. pp. 47–58.
-
- Bhattacharya I, Getoor L. Collective entity resolution in relational data. ACM Trans. Knowl. Discov. Data. 2007;1:1–36.
-
- Bilenko M, Kamath B, Mooney RJ. Adaptive blocking: Learning to scale up record linkage. Proceedings of the IEEE Computer Society 6th International Conference on Data Mining.2006. pp. 87–96.
-
- Culotta A, McCallum A. Tractable learning and inference of high-order representations. Proceedings of the ICML Workshop on Open Problems in Statistical Relational Learning; 2006. http://www.cs.umd.edu/projects/srl2006/proceedings.html.
-
- Culotta A, Kanani P, Hall R, Wick M, Mccallum A. Author disambiguation using error-driven machine learning with a ranking loss function. Proceedings of the 6th AAAI International Workshop on Information Integration on the Web.2007.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources