

Efficient encoding of vocalizations in the auditory midbrain
- PMID: 20089889
- PMCID: PMC6633079
- DOI: 10.1523/JNEUROSCI.1964-09.2010
Efficient encoding of vocalizations in the auditory midbrain
Abstract
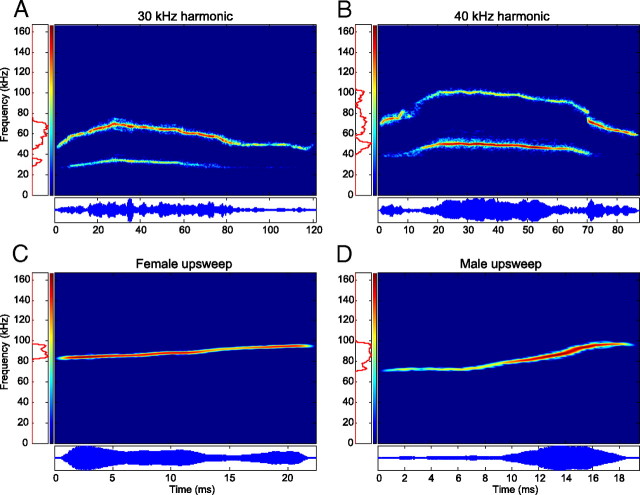
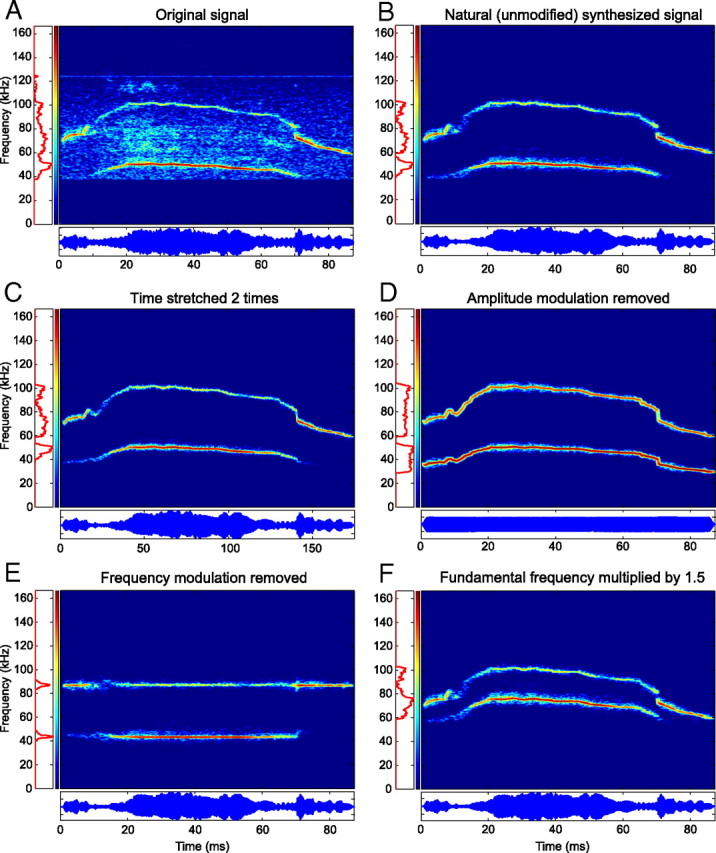
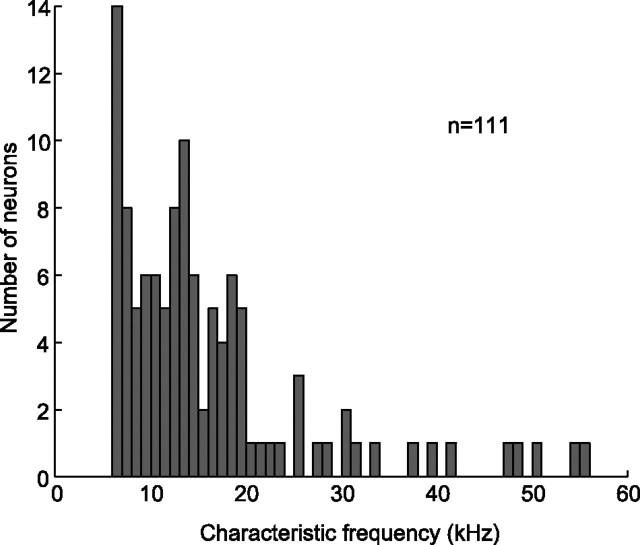
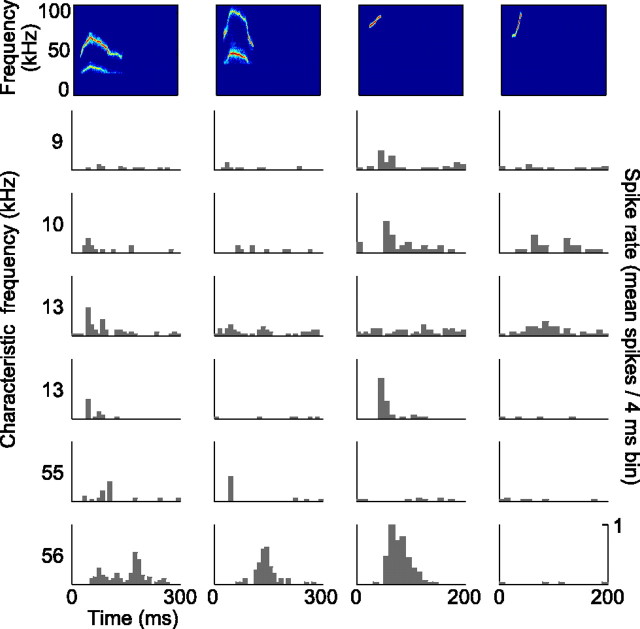
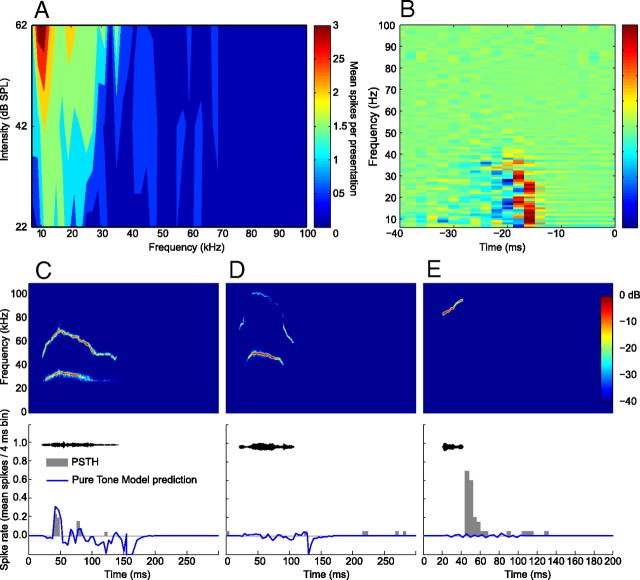
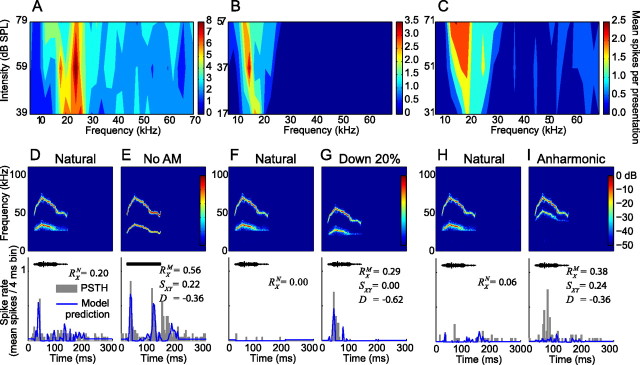
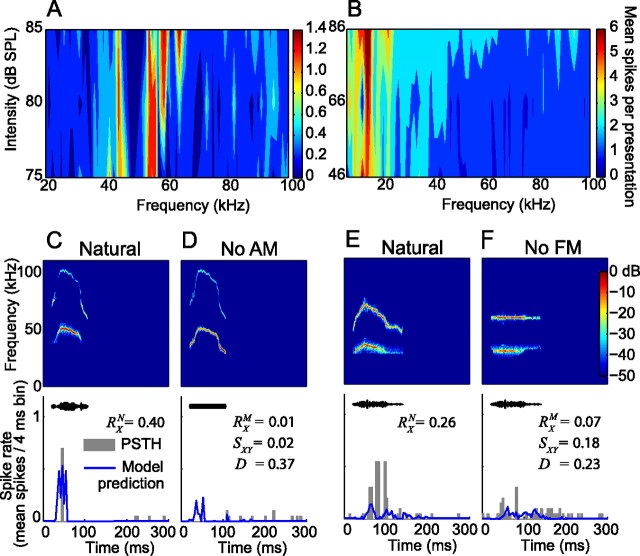
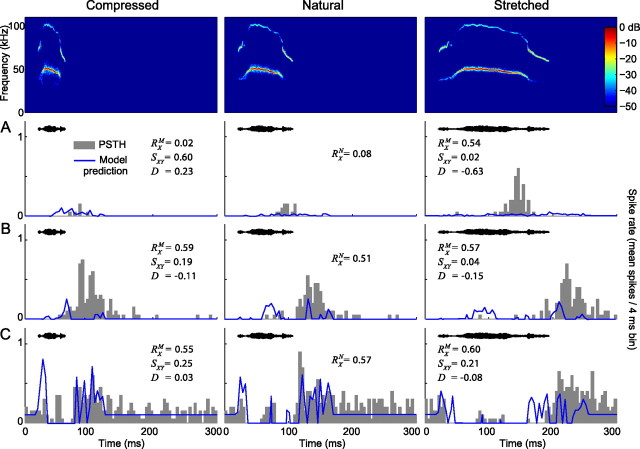
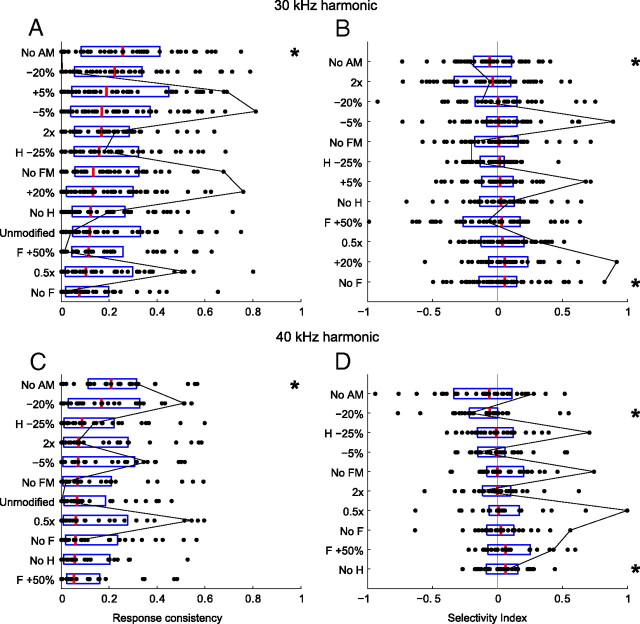
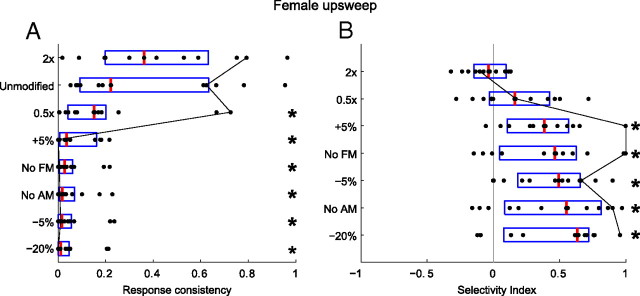
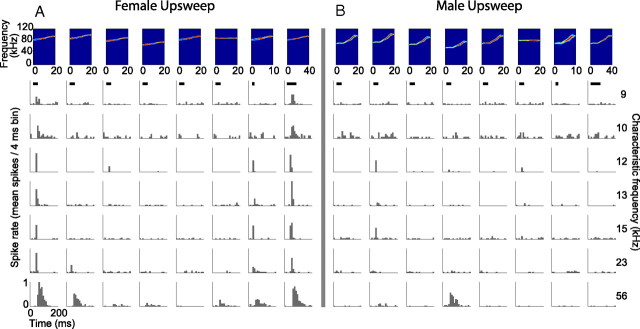
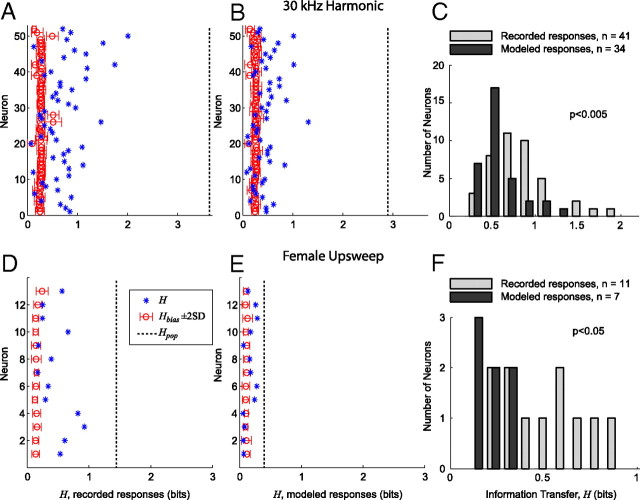
An important question in sensory neuroscience is what coding strategies and mechanisms are used by the brain to detect and discriminate among behaviorally relevant stimuli. There is evidence that sensory systems migrate from a distributed and redundant encoding strategy at the periphery to a more heterogeneous encoding in cortical structures. It has been hypothesized that heterogeneity is an efficient encoding strategy that minimizes the redundancy of the neural code and maximizes information throughput. Evidence of this mechanism has been documented in cortical structures. In this study, we examined whether heterogeneous encoding of complex sounds contributes to efficient encoding in the auditory midbrain by characterizing neural responses to behaviorally relevant vocalizations in the mouse inferior colliculus (IC). We independently manipulated the frequency, amplitude, duration, and harmonic structure of the vocalizations to create a suite of modified vocalizations. Based on measures of both spike rate and timing, we characterized the heterogeneity of neural responses to the natural vocalizations and their perturbed variants. Using information theoretic measures, we found that heterogeneous response properties of IC neurons contribute to efficient encoding of behaviorally relevant vocalizations.
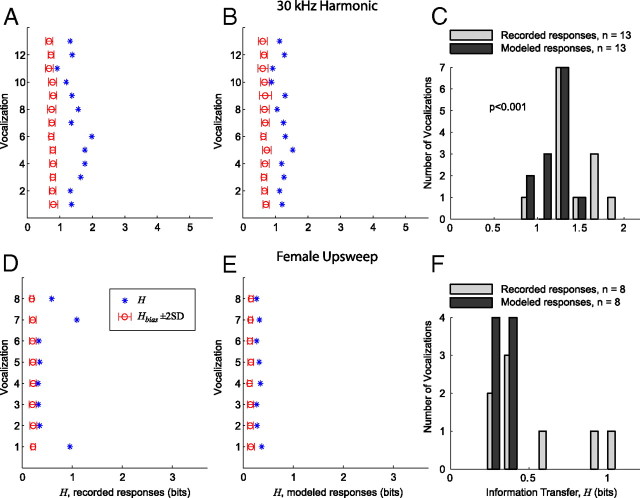
Figures
Similar articles
-
Spatial organization of receptive fields in the auditory midbrain of awake mouse.Neuroscience. 2011 Oct 13;193:429-39. doi: 10.1016/j.neuroscience.2011.07.025. Epub 2011 Jul 24. Neuroscience. 2011. PMID: 21807069
-
Natural Vocalizations in the Mammalian Inferior Colliculus are Broadly Encoded by a Small Number of Independent Multi-Units.Front Neural Circuits. 2016 Feb 1;9:91. doi: 10.3389/fncir.2015.00091. eCollection 2015. Front Neural Circuits. 2016. PMID: 26869890 Free PMC article.
-
Discrimination of ultrasonic vocalizations by CBA/CaJ mice (Mus musculus) is related to spectrotemporal dissimilarity of vocalizations.PLoS One. 2014 Jan 9;9(1):e85405. doi: 10.1371/journal.pone.0085405. eCollection 2014. PLoS One. 2014. PMID: 24416405 Free PMC article.
-
Serotonin in the inferior colliculus.Hear Res. 2002 Jun;168(1-2):1-11. doi: 10.1016/s0378-5955(02)00365-9. Hear Res. 2002. PMID: 12117504 Review.
-
Coding of communication calls in the subcortical and cortical structures of the auditory system.Physiol Res. 2008;57 Suppl 3:S149-S159. doi: 10.33549/physiolres.931608. Epub 2008 May 13. Physiol Res. 2008. PMID: 18481905 Review.
Cited by
-
Best sensitivity of temporal modulation transfer functions in laboratory mice matches the amplitude modulation embedded in vocalizations.J Acoust Soc Am. 2020 Jan;147(1):337. doi: 10.1121/10.0000583. J Acoust Soc Am. 2020. PMID: 32006990 Free PMC article.
-
Neural representation in the auditory midbrain of the envelope of vocalizations based on a peripheral ear model.Front Neural Circuits. 2013 Oct 21;7:166. doi: 10.3389/fncir.2013.00166. eCollection 2013. Front Neural Circuits. 2013. PMID: 24155694 Free PMC article.
-
Subcortical pathways: Towards a better understanding of auditory disorders.Hear Res. 2018 May;362:48-60. doi: 10.1016/j.heares.2018.01.008. Epub 2018 Jan 31. Hear Res. 2018. PMID: 29395615 Free PMC article. Review.
-
Subcortical input heterogeneity in the mouse inferior colliculus.J Physiol. 2011 Aug 15;589(Pt 16):3955-67. doi: 10.1113/jphysiol.2011.210278. Epub 2011 Jul 4. J Physiol. 2011. PMID: 21727222 Free PMC article.
-
Serotonin modulates response properties of neurons in the dorsal cochlear nucleus of the mouse.Hear Res. 2017 Feb;344:13-23. doi: 10.1016/j.heares.2016.10.017. Epub 2016 Nov 9. Hear Res. 2017. PMID: 27838373 Free PMC article.
References
-
- Abel C, Kössl M. Sensitive response to low frequency cochlear distortion products in the auditory midbrain. J Neurophysiol. 2009;101:1560–1574. - PubMed
-
- Adams JC. Ascending projections to the inferior colliculus. J Comp Neurol. 1979;183:519–538. - PubMed
-
- Aertsen AM, Johannesma PI. The spectro-temporal receptive field: a functional characteristic of auditory neurons. Biol Cybern. 1981;42:133–143. - PubMed
-
- Amin N, Doupe A, Theunissen FE. Development of selectivity for natural sounds in the songbird auditory forebrain. J Neurophysiol. 2007;97:3517–3531. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources