

Genome wide association for addiction: replicated results and comparisons of two analytic approaches
- PMID: 20098672
- PMCID: PMC2809089
- DOI: 10.1371/journal.pone.0008832
Genome wide association for addiction: replicated results and comparisons of two analytic approaches
Abstract
Background: Vulnerabilities to dependence on addictive substances are substantially heritable complex disorders whose underlying genetic architecture is likely to be polygenic, with modest contributions from variants in many individual genes. "Nontemplate" genome wide association (GWA) approaches can identity groups of chromosomal regions and genes that, taken together, are much more likely to contain allelic variants that alter vulnerability to substance dependence than expected by chance.
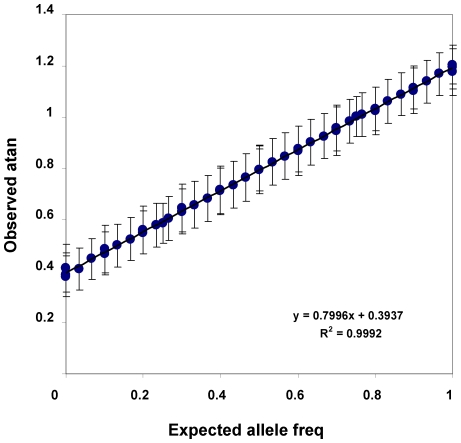
Methodology/principal findings: We report pooled "nontemplate" genome-wide association studies of two independent samples of substance dependent vs control research volunteers (n = 1620), one European-American and the other African-American using 1 million SNP (single nucleotide polymorphism) Affymetrix genotyping arrays. We assess convergence between results from these two samples using two related methods that seek clustering of nominally-positive results and assess significance levels with Monte Carlo and permutation approaches. Both "converge then cluster" and "cluster then converge" analyses document convergence between the results obtained from these two independent datasets in ways that are virtually never found by chance. The genes identified in this fashion are also identified by individually-genotyped dbGAP data that compare allele frequencies in cocaine dependent vs control individuals.
Conclusions/significance: These overlapping results identify small chromosomal regions that are also identified by genome wide data from studies of other relevant samples to extents much greater than chance. These chromosomal regions contain more genes related to "cell adhesion" processes than expected by chance. They also contain a number of genes that encode potential targets for anti-addiction pharmacotherapeutics. "Nontemplate" GWA approaches that seek chromosomal regions in which nominally-positive associations are found in multiple independent samples are likely to complement classical, "template" GWA approaches in which "genome wide" levels of significance are sought for SNP data from single case vs control comparisons.
Conflict of interest statement
Figures

References
-
- Uhl GR, Elmer GI, Labuda MC, Pickens RW. Genetic influences in drug abuse. In: Gloom FE, Kupfer DJ,, editors. Psychopharmacology: The Fourth Generation of Progress. New York: Raven Press; 1995. pp. 1793–2783.
-
- Tsuang MT, Lyons MJ, Meyer JM, Doyle T, Eisen SA, et al. Co-occurrence of abuse of different drugs in men: the role of drug-specific and shared vulnerabilities. Arch Gen Psychiatry. 1998;55:967–972. - PubMed
-
- Karkowski LM, Prescott CA, Kendler KS. Multivariate assessment of factors influencing illicit substance use in twins from female-female pairs. Am J Med Genet. 2000;96:665–670. - PubMed
-
- True WR, Heath AC, Scherrer JF, Xian H, Lin N, et al. Interrelationship of genetic and environmental influences on conduct disorder and alcohol and marijuana dependence symptoms. Am J Med Genet. 1999;88:391–397. - PubMed
-
- Kendler KS, Karkowski LM, Neale MC, Prescott CA. Illicit psychoactive substance use, heavy use, abuse, and dependence in a US population-based sample of male twins. Arch Gen Psychiatry. 2000;57:261–269. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
