

Candidates in Astroviruses, Seadornaviruses, Cytorhabdoviruses and Coronaviruses for +1 frame overlapping genes accessed by leaky scanning
- PMID: 20100346
- PMCID: PMC2832772
- DOI: 10.1186/1743-422X-7-17
Candidates in Astroviruses, Seadornaviruses, Cytorhabdoviruses and Coronaviruses for +1 frame overlapping genes accessed by leaky scanning
Abstract
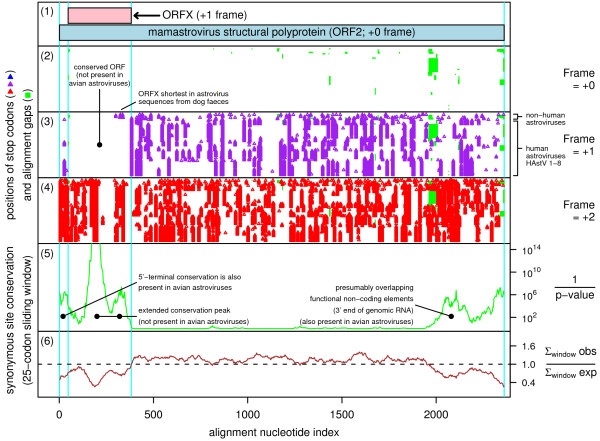
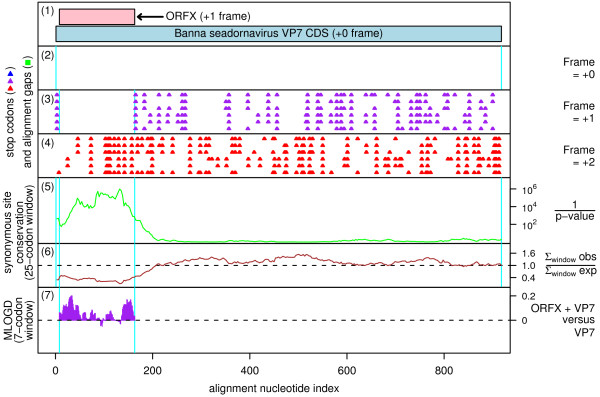
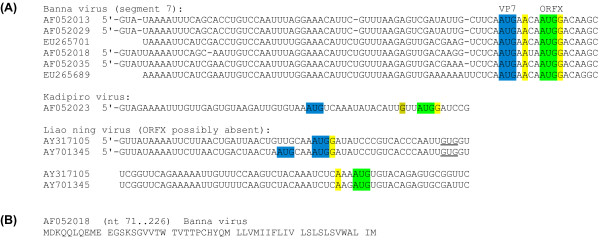
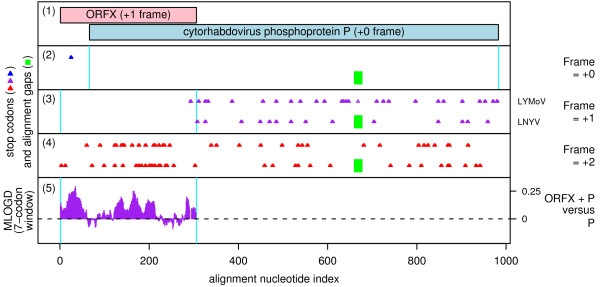
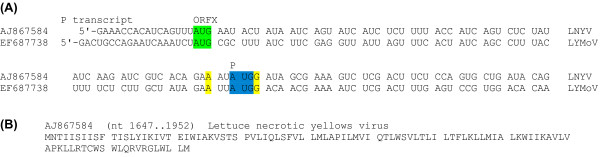
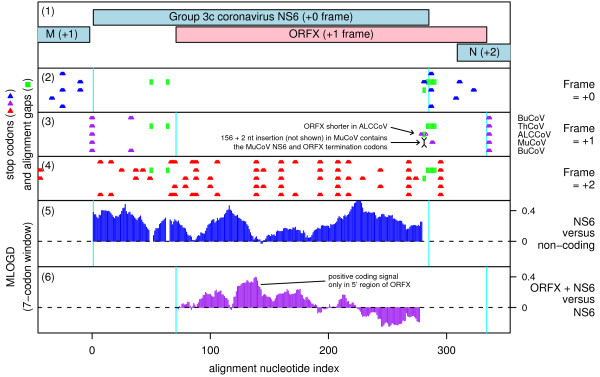
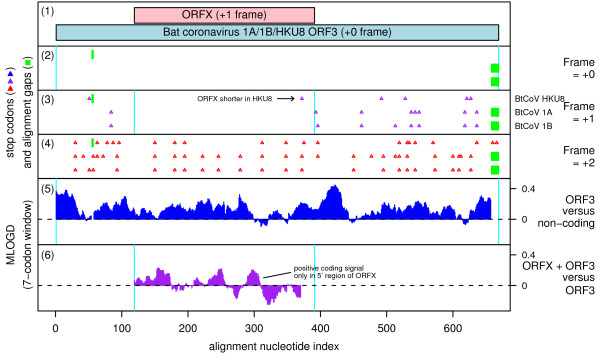
Background: Overlapping genes are common in RNA viruses where they serve as a mechanism to optimize the coding potential of compact genomes. However, annotation of overlapping genes can be difficult using conventional gene-finding software. Recently we have been using a number of complementary approaches to systematically identify previously undetected overlapping genes in RNA virus genomes. In this article we gather together a number of promising candidate new overlapping genes that may be of interest to the community.
Results: Overlapping gene predictions are presented for the astroviruses, seadornaviruses, cytorhabdoviruses and coronaviruses (families Astroviridae, Reoviridae, Rhabdoviridae and Coronaviridae, respectively).
Figures



References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
