

Mining protein loops using a structural alphabet and statistical exceptionality
- PMID: 20132552
- PMCID: PMC2833150
- DOI: 10.1186/1471-2105-11-75
Mining protein loops using a structural alphabet and statistical exceptionality
Abstract
Background: Protein loops encompass 50% of protein residues in available three-dimensional structures. These regions are often involved in protein functions, e.g. binding site, catalytic pocket... However, the description of protein loops with conventional tools is an uneasy task. Regular secondary structures, helices and strands, have been widely studied whereas loops, because they are highly variable in terms of sequence and structure, are difficult to analyze. Due to data sparsity, long loops have rarely been systematically studied.
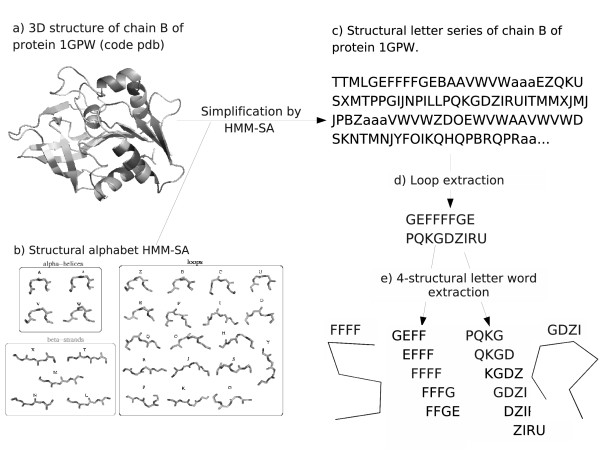
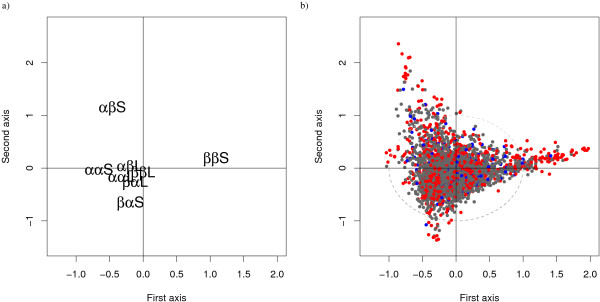
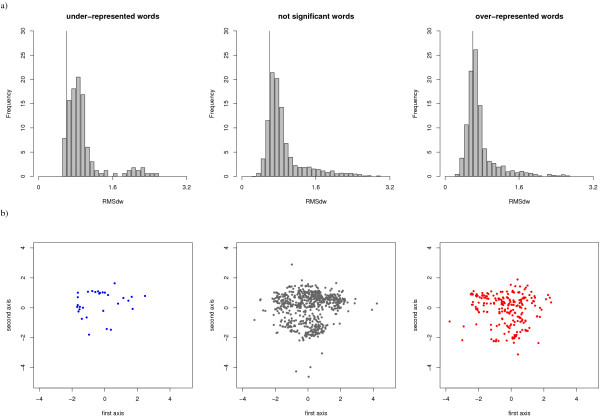
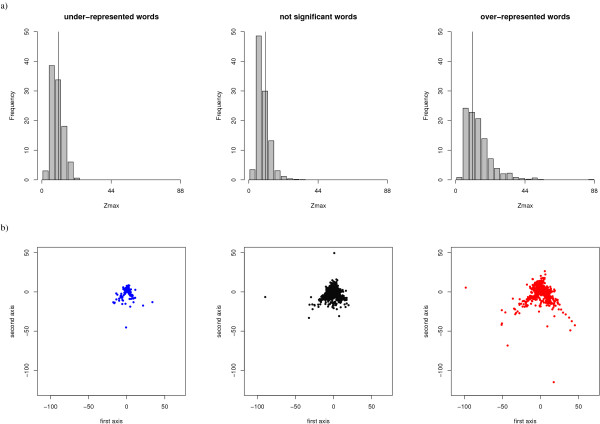
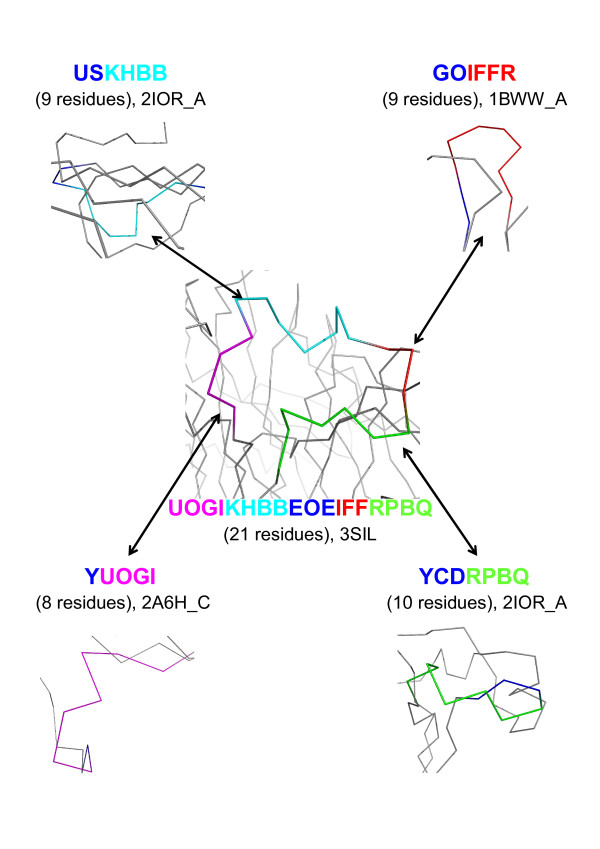
Results: We developed a simple and accurate method that allows the description and analysis of the structures of short and long loops using structural motifs without restriction on loop length. This method is based on the structural alphabet HMM-SA. HMM-SA allows the simplification of a three-dimensional protein structure into a one-dimensional string of states, where each state is a four-residue prototype fragment, called structural letter. The difficult task of the structural grouping of huge data sets is thus easily accomplished by handling structural letter strings as in conventional protein sequence analysis. We systematically extracted all seven-residue fragments in a bank of 93000 protein loops and grouped them according to the structural-letter sequence, named structural word. This approach permits a systematic analysis of loops of all sizes since we consider the structural motifs of seven residues rather than complete loops. We focused the analysis on highly recurrent words of loops (observed more than 30 times). Our study reveals that 73% of loop-lengths are covered by only 3310 highly recurrent structural words out of 28274 observed words). These structural words have low structural variability (mean RMSd of 0.85 A). As expected, half of these motifs display a flanking-region preference but interestingly, two thirds are shared by short (less than 12 residues) and long loops. Moreover, half of recurrent motifs exhibit a significant level of amino-acid conservation with at least four significant positions and 87% of long loops contain at least one such word. We complement our analysis with the detection of statistically over-represented patterns of structural letters as in conventional DNA sequence analysis. About 30% (930) of structural words are over-represented, and cover about 40% of loop lengths. Interestingly, these words exhibit lower structural variability and higher sequential specificity, suggesting structural or functional constraints.
Conclusions: We developed a method to systematically decompose and study protein loops using recurrent structural motifs. This method is based on the structural alphabet HMM-SA and not on structural alignment and geometrical parameters. We extracted meaningful structural motifs that are found in both short and long loops. To our knowledge, it is the first time that pattern mining helps to increase the signal-to-noise ratio in protein loops. This finding helps to better describe protein loops and might permit to decrease the complexity of long-loop analysis. Detailed results are available at http://www.mti.univ-paris-diderot.fr/publication/supplementary/2009/ACCLoop/.
Figures
Similar articles
-
Dissecting protein loops with a statistical scalpel suggests a functional implication of some structural motifs.BMC Bioinformatics. 2011 Jun 20;12:247. doi: 10.1186/1471-2105-12-247. BMC Bioinformatics. 2011. PMID: 21689388 Free PMC article.
-
SA-Mot: a web server for the identification of motifs of interest extracted from protein loops.Nucleic Acids Res. 2011 Jul;39(Web Server issue):W203-9. doi: 10.1093/nar/gkr410. Epub 2011 Jun 10. Nucleic Acids Res. 2011. PMID: 21665924 Free PMC article.
-
New efficient statistical sequence-dependent structure prediction of short to medium-sized protein loops based on an exhaustive loop classification.J Mol Biol. 1999 Jun 25;289(5):1469-90. doi: 10.1006/jmbi.1999.2826. J Mol Biol. 1999. PMID: 10373380
-
Protein structure mining using a structural alphabet.Proteins. 2008 May 1;71(2):920-37. doi: 10.1002/prot.21776. Proteins. 2008. PMID: 18004784
-
Five hierarchical levels of sequence-structure correlation in proteins.Appl Bioinformatics. 2004;3(2-3):97-104. doi: 10.2165/00822942-200403020-00004. Appl Bioinformatics. 2004. PMID: 15693735 Review.
Cited by
-
Dissecting protein loops with a statistical scalpel suggests a functional implication of some structural motifs.BMC Bioinformatics. 2011 Jun 20;12:247. doi: 10.1186/1471-2105-12-247. BMC Bioinformatics. 2011. PMID: 21689388 Free PMC article.
-
SA-Mot: a web server for the identification of motifs of interest extracted from protein loops.Nucleic Acids Res. 2011 Jul;39(Web Server issue):W203-9. doi: 10.1093/nar/gkr410. Epub 2011 Jun 10. Nucleic Acids Res. 2011. PMID: 21665924 Free PMC article.
-
Analysis of the HIV-2 protease's adaptation to various ligands: characterization of backbone asymmetry using a structural alphabet.Sci Rep. 2018 Jan 15;8(1):710. doi: 10.1038/s41598-017-18941-3. Sci Rep. 2018. PMID: 29335428 Free PMC article.
-
Accounting for large amplitude protein deformation during in silico macromolecular docking.Int J Mol Sci. 2011 Feb 22;12(2):1316-33. doi: 10.3390/ijms12021316. Int J Mol Sci. 2011. PMID: 21541061 Free PMC article.
-
Considerations of Protein Subpockets in Fragment-Based Drug Design.Chem Biol Drug Des. 2016 Jan;87(1):5-20. doi: 10.1111/cbdd.12631. Epub 2015 Aug 31. Chem Biol Drug Des. 2016. PMID: 26307335 Free PMC article.
References
-
- Fetrow JS. Omega loops: nonregular secondary structures significant in protein function and stability. FASEB J. 1995;9:708–717. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
