

Heterogeneity in spike protein genes of porcine epidemic diarrhea viruses isolated in Korea
- PMID: 20132850
- PMCID: PMC7114470
- DOI: 10.1016/j.virusres.2010.01.015
Heterogeneity in spike protein genes of porcine epidemic diarrhea viruses isolated in Korea
Abstract
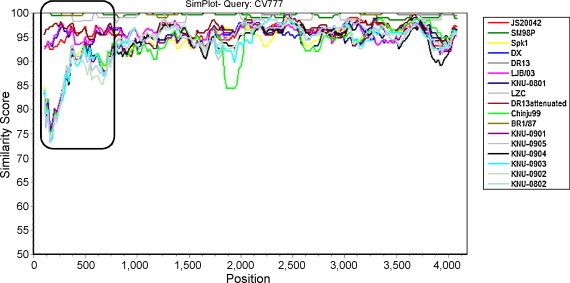
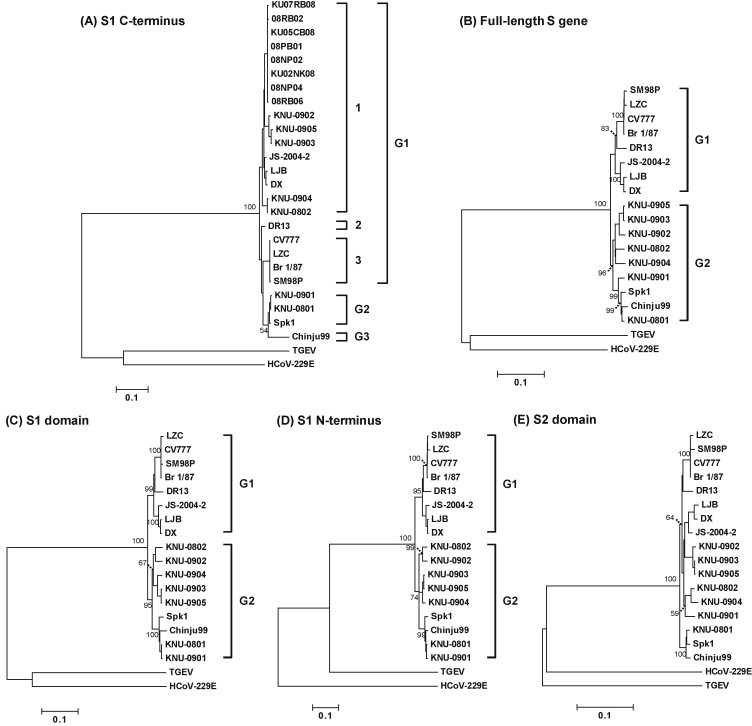
Porcine epidemic diarrhea virus (PEDV) has plagued the domestic swine industry in Korea causing significant economic impacts on pig production nationwide. In the present study, we determined the complete nucleotide sequences of the spike (S) glycoprotein genes of seven Korean PEDV isolates. The entire S genes of all isolates were found to be nine nucleotides longer in length than other PEDV reference strains. This size difference was due to the combined presence of notable 15 bp insertion and 6 bp deletion within the N-terminal region of the S1 domain of the Korean isolates. In addition, the largest number of amino acid variations was accumulated in the S1 N-terminal region, leading to the presence of hypervariability in the isolates. Sequence comparisons at the peptide level of the S proteins revealed that all seven Korean isolates shared diverse similarities ranging from a 93.6% to 99.6% identity with each other but exhibited a 92.2% to 93.7% identity with other reference strains. Collectively, the sequence analysis data indicate the diversity of the PEDV isolates currently prevalent in Korea that represents a heterogeneous group. Phylogenetic analyses showed two separate clusters, in which all Korean field isolates were grouped together in the second cluster (group 2). The results indicate that prevailing isolates in Korea are phylogenetically more closely related to each other rather than other reference strains. Interestingly, the tree topology based on the nucleotide sequences representing the S1 domain or the S1 N-terminal region most nearly resembled the full S gene-based phylogenetic tree. Therefore, our data implicates a potential usefulness of the partial S protein gene including the N-terminal region in unveiling genetic relatedness of PEDV isolates.
(c) 2010 Elsevier B.V. All rights reserved.
Figures


References
-
- Chang S.H., Bae J.L., Kang T.J., Kim J., Chung G.H., Lim C.W., Laude H., Yang M.S., Jang Y.S. Identification of the epitope region capable of inducing neutralizing antibodies against the porcine epidemic diarrhea virus. Mol. Cells. 2002;14:295–299. - PubMed
-
- Debouck P., Pensaert M. Experimental infection of pigs with a new porcine enteric coronavirus, CV777. Am. J. Vet. Res. 1980;41:219–223. - PubMed
-
- Duarte M., Laude H. Sequence of the spike protein of porcine epidemic diarrhea virus. J. Gen. Virol. 1994;75:1195–1200. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Other Literature Sources
