

The effect of orthology and coregulation on detecting regulatory motifs
- PMID: 20140085
- PMCID: PMC2815771
- DOI: 10.1371/journal.pone.0008938
The effect of orthology and coregulation on detecting regulatory motifs
Abstract
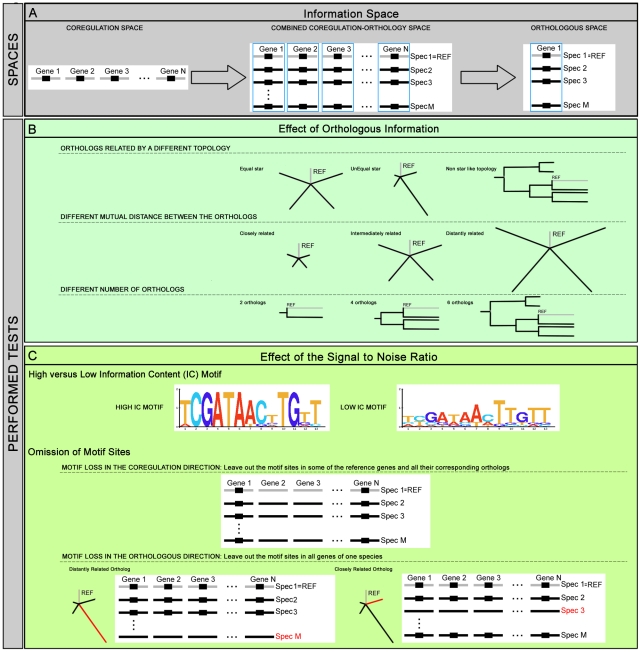
Background: Computational de novo discovery of transcription factor binding sites is still a challenging problem. The growing number of sequenced genomes allows integrating orthology evidence with coregulation information when searching for motifs. Moreover, the more advanced motif detection algorithms explicitly model the phylogenetic relatedness between the orthologous input sequences and thus should be well adapted towards using orthologous information. In this study, we evaluated the conditions under which complementing coregulation with orthologous information improves motif detection for the class of probabilistic motif detection algorithms with an explicit evolutionary model.
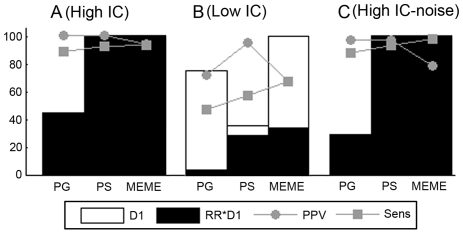
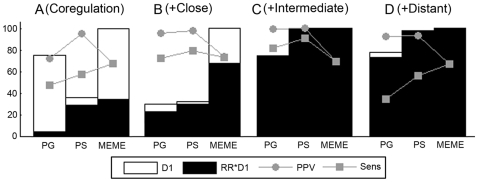
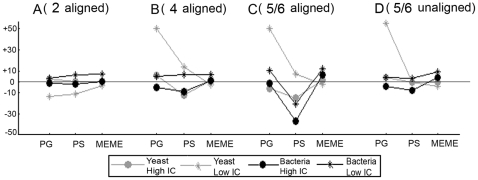
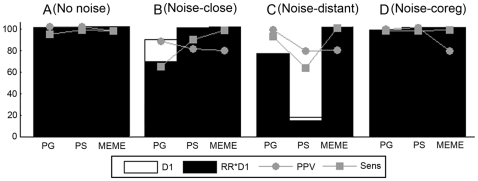
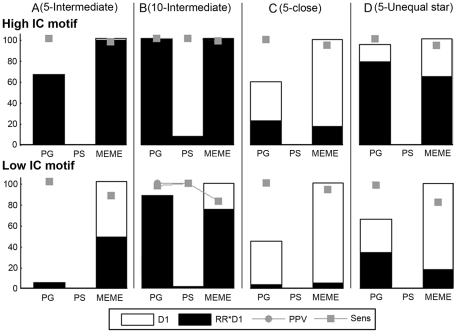
Methodology: We designed datasets (real and synthetic) covering different degrees of coregulation and orthologous information to test how well Phylogibbs and Phylogenetic sampler, as representatives of the motif detection algorithms with evolutionary model performed as compared to MEME, a more classical motif detection algorithm that treats orthologs independently.
Results and conclusions: Under certain conditions detecting motifs in the combined coregulation-orthology space is indeed more efficient than using each space separately, but this is not always the case. Moreover, the difference in success rate between the advanced algorithms and MEME is still marginal. The success rate of motif detection depends on the complex interplay between the added information and the specificities of the applied algorithms. Insights in this relation provide information useful to both developers and users. All benchmark datasets are available at http://homes.esat.kuleuven.be/~kmarchal/Supplementary_Storms_Valerie_PlosONE.
Conflict of interest statement
Figures
Similar articles
-
PhyloGibbs: a Gibbs sampling motif finder that incorporates phylogeny.PLoS Comput Biol. 2005 Dec;1(7):e67. doi: 10.1371/journal.pcbi.0010067. Epub 2005 Dec 9. PLoS Comput Biol. 2005. PMID: 16477324 Free PMC article.
-
The value of position-specific priors in motif discovery using MEME.BMC Bioinformatics. 2010 Apr 9;11:179. doi: 10.1186/1471-2105-11-179. BMC Bioinformatics. 2010. PMID: 20380693 Free PMC article.
-
Phylogenetic motif detection by expectation-maximization on evolutionary mixtures.Pac Symp Biocomput. 2004:324-35. doi: 10.1142/9789812704856_0031. Pac Symp Biocomput. 2004. PMID: 14992514
-
Parsing regulatory DNA: general tasks, techniques, and the PhyloGibbs approach.J Biosci. 2007 Aug;32(5):863-70. doi: 10.1007/s12038-007-0086-0. J Biosci. 2007. PMID: 17914228 Review.
-
New Tools in Orthology Analysis: A Brief Review of Promising Perspectives.Front Genet. 2017 Oct 31;8:165. doi: 10.3389/fgene.2017.00165. eCollection 2017. Front Genet. 2017. PMID: 29163633 Free PMC article. Review.
Cited by
-
A mutation degree model for the identification of transcriptional regulatory elements.BMC Bioinformatics. 2011 Jun 27;12:262. doi: 10.1186/1471-2105-12-262. BMC Bioinformatics. 2011. PMID: 21708002 Free PMC article.
-
Known and novel post-transcriptional regulatory sequences are conserved across plant families.RNA. 2012 Mar;18(3):368-84. doi: 10.1261/rna.031179.111. Epub 2012 Jan 11. RNA. 2012. PMID: 22237150 Free PMC article.
References
-
- Venter JC, Remington K, Heidelberg JF, Halpern AL, Rusch D, et al. Environmental genome shotgun sequencing of the Sargasso Sea. Science. 2004;304:66–74. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
