

QuickGO: a user tutorial for the web-based Gene Ontology browser
- PMID: 20157483
- PMCID: PMC2794795
- DOI: 10.1093/database/bap010
QuickGO: a user tutorial for the web-based Gene Ontology browser
Abstract
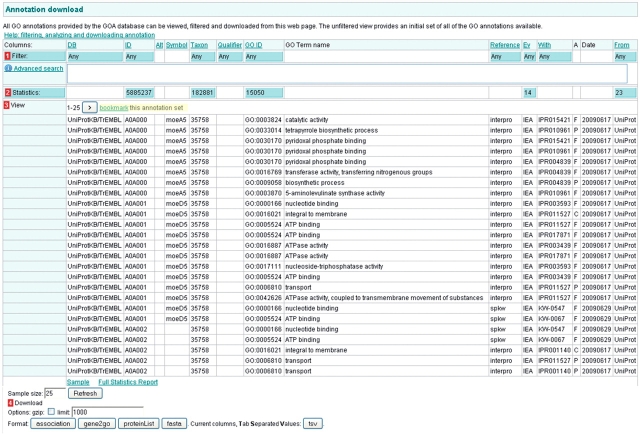
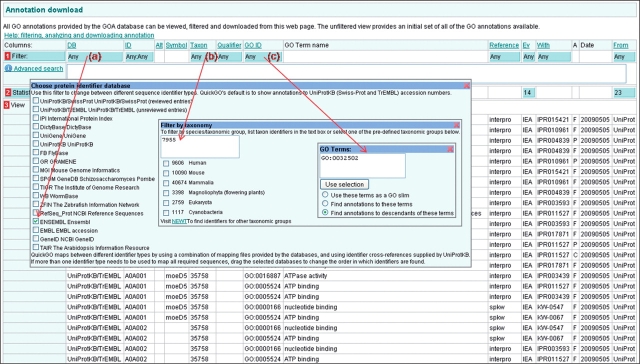
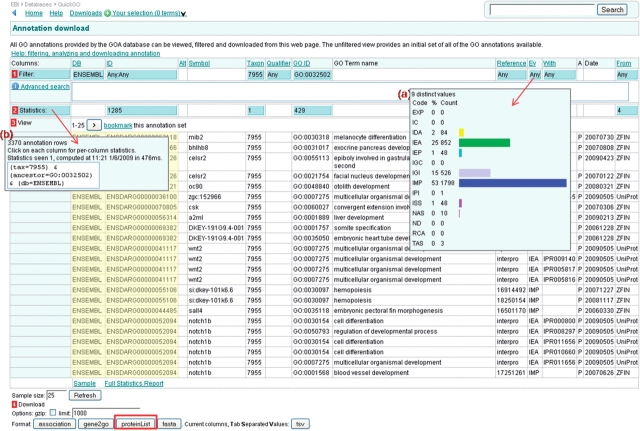
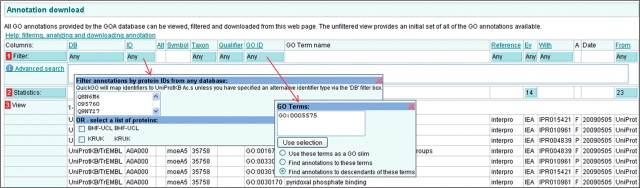
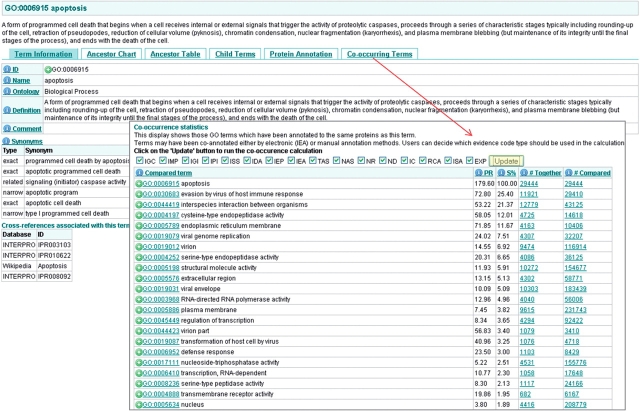
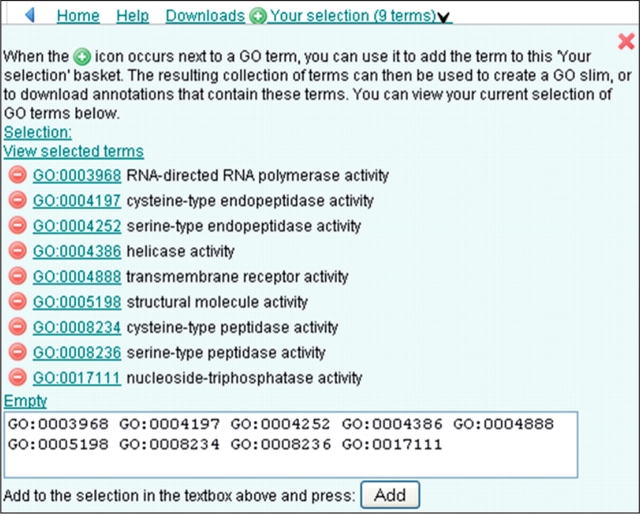
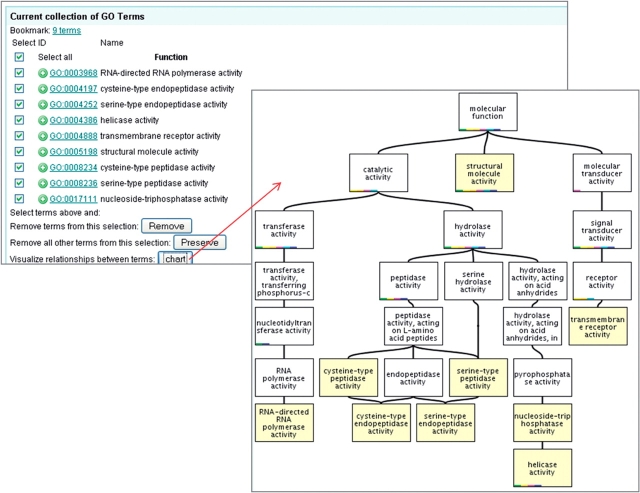
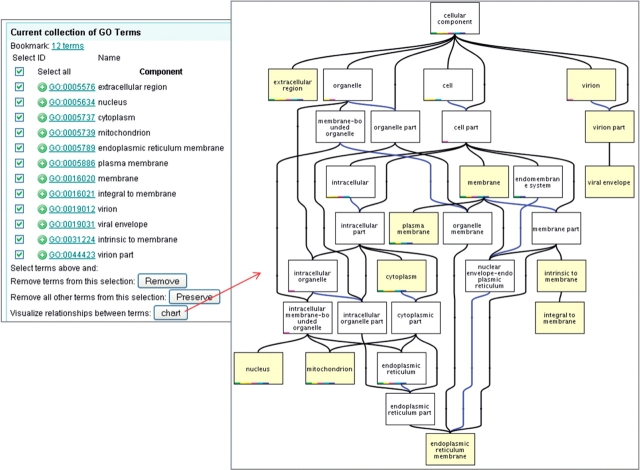
The Gene Ontology (GO) has proven to be a valuable resource for functional annotation of gene products. At well over 27 000 terms, the descriptiveness of GO has increased rapidly in line with the biological data it represents. Therefore, it is vital to be able to easily and quickly mine the functional information that has been made available through these GO terms being associated with gene products. QuickGO is a fast, web-based tool for browsing the GO and all associated GO annotations provided by the GOA group. After undergoing a redevelopment, QuickGO is now able to offer many more features beyond simple browsing. Users have responded well to the new tool and given very positive feedback about its usefulness. This tutorial will demonstrate how some of these features could be useful to the researcher wanting to discover more about their dataset, particular areas of biology or to find new ways of directing their research.Database URL:http://www.ebi.ac.uk/QuickGO.
Figures
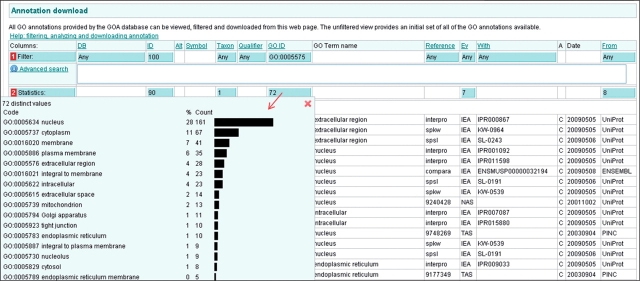
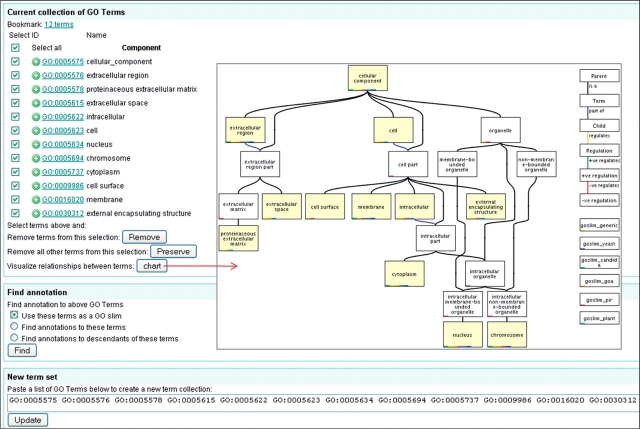
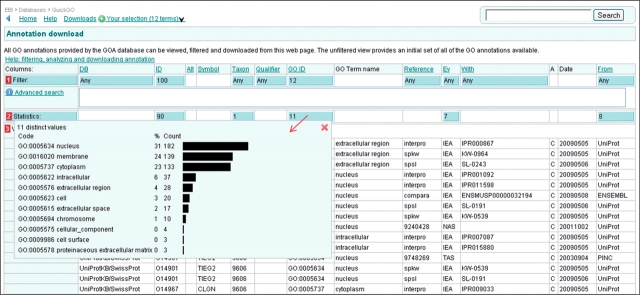
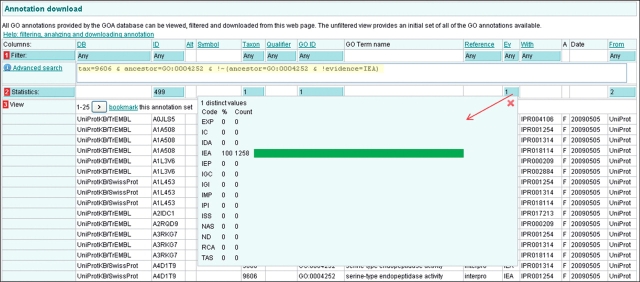

References
-
- Pereira GS, Brandão RM, Giuliatti S, et al. Gene Class expression: analysis tool of Gene Ontology terms with gene expression data. Genet. Mol. Res. 2006;5:108–114. - PubMed
-
- Pirooznia M, Habib T, Perkins EJ, et al. GOfetcher: a database with complex searching facility for gene ontology. Bioinformatics. 2008;24:2561–2563. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
