

Integration of sensory and reward information during perceptual decision-making in lateral intraparietal cortex (LIP) of the macaque monkey
- PMID: 20174574
- PMCID: PMC2824817
- DOI: 10.1371/journal.pone.0009308
Integration of sensory and reward information during perceptual decision-making in lateral intraparietal cortex (LIP) of the macaque monkey
Abstract
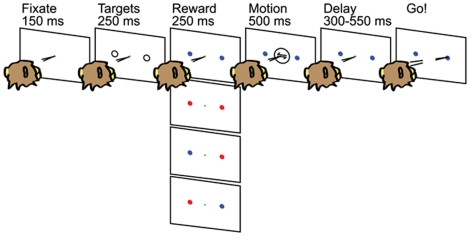
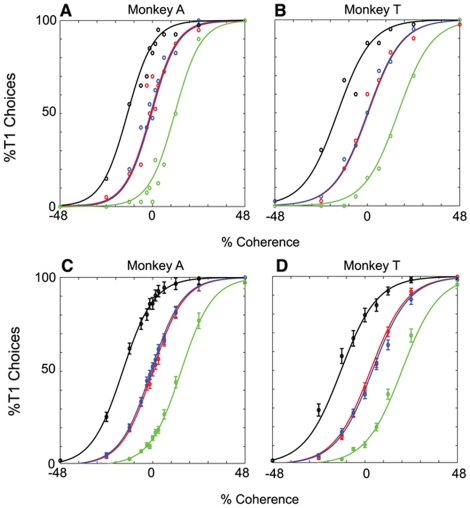
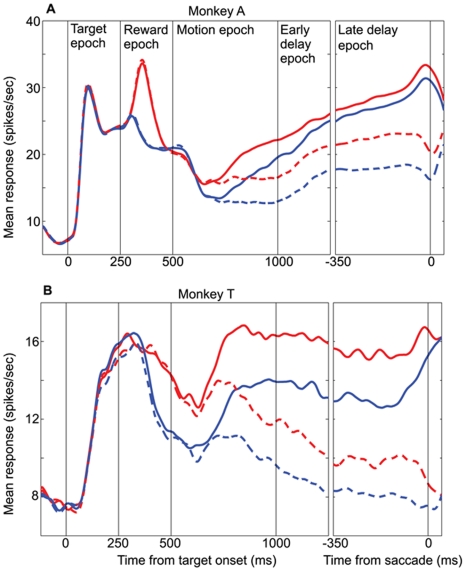
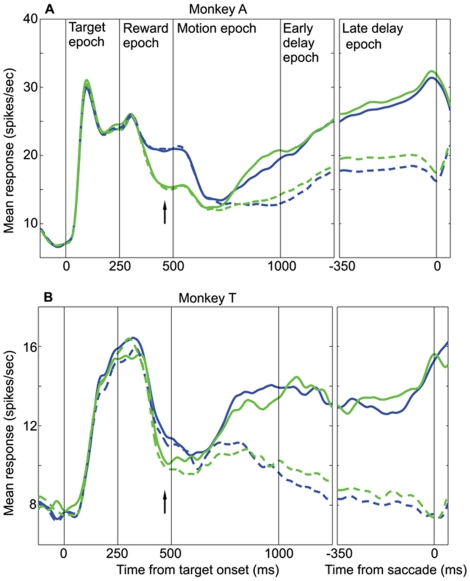
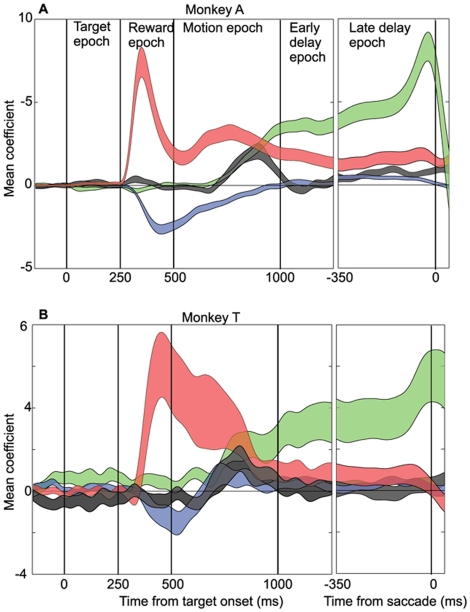
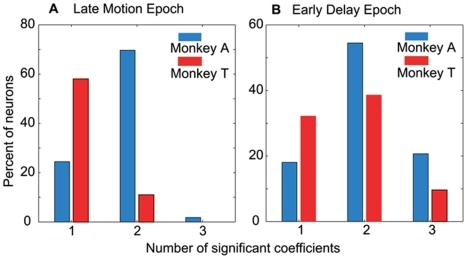
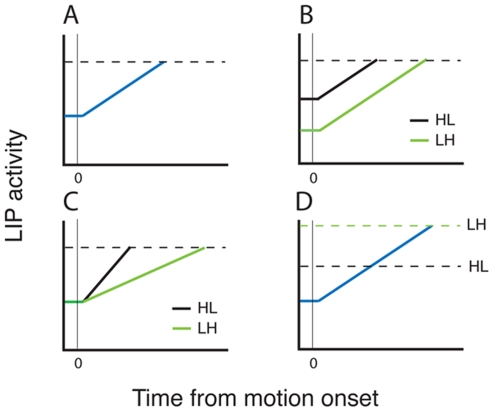
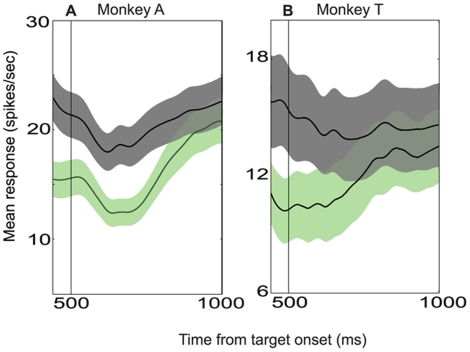
Single neurons in cortical area LIP are known to carry information relevant to both sensory and value-based decisions that are reported by eye movements. It is not known, however, how sensory and value information are combined in LIP when individual decisions must be based on a combination of these variables. To investigate this issue, we conducted behavioral and electrophysiological experiments in rhesus monkeys during performance of a two-alternative, forced-choice discrimination of motion direction (sensory component). Monkeys reported each decision by making an eye movement to one of two visual targets associated with the two possible directions of motion. We introduced choice biases to the monkeys' decision process (value component) by randomly interleaving balanced reward conditions (equal reward value for the two choices) with unbalanced conditions (one alternative worth twice as much as the other). The monkeys' behavior, as well as that of most LIP neurons, reflected the influence of all relevant variables: the strength of the sensory information, the value of the target in the neuron's response field, and the value of the target outside the response field. Overall, detailed analysis and computer simulation reveal that our data are consistent with a two-stage drift diffusion model proposed by Diederich and Bussmeyer for the effect of payoffs in the context of sensory discrimination tasks. Initial processing of payoff information strongly influences the starting point for the accumulation of sensory evidence, while exerting little if any effect on the rate of accumulation of sensory evidence.
Conflict of interest statement
Figures

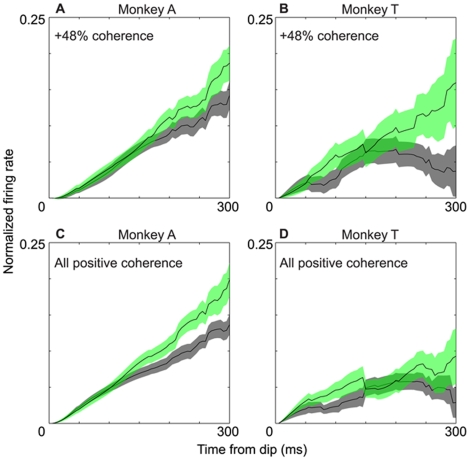
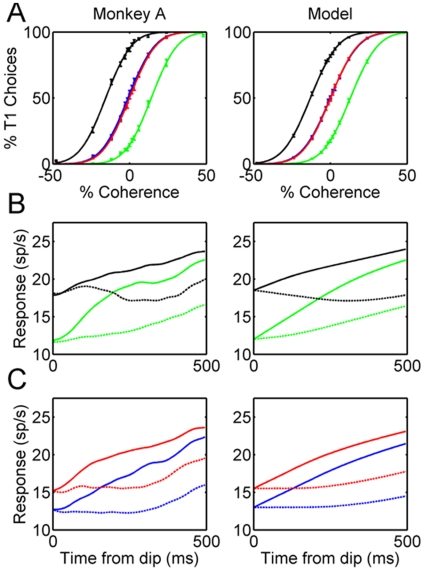
References
-
- Diederich A, Busemeyer JR. Modeling the effects of payoff on response bias in a perceptual discrimination task: bound-change, drift-rate-change, or two-stage-processing hypothesis. Percept Psychophys. 2006;68:194–207. - PubMed
-
- Green DM, Swets JA. New York: Wiley; 1966. Signal detection and psychophysics.
-
- Laming D. New York: Academic Press; 1968. Information theory of choice reaction times.
-
- Link S, Heath R. A sequential theory of psychological discrimination. Psychometrika. 1975;40:77–105.
-
- Ratcliff R. A theory of memory retrieval. Psychol Rev. 1978;85:59–108.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
