

SpectraClassifier 1.0: a user friendly, automated MRS-based classifier-development system
- PMID: 20181285
- PMCID: PMC2846905
- DOI: 10.1186/1471-2105-11-106
SpectraClassifier 1.0: a user friendly, automated MRS-based classifier-development system
Abstract
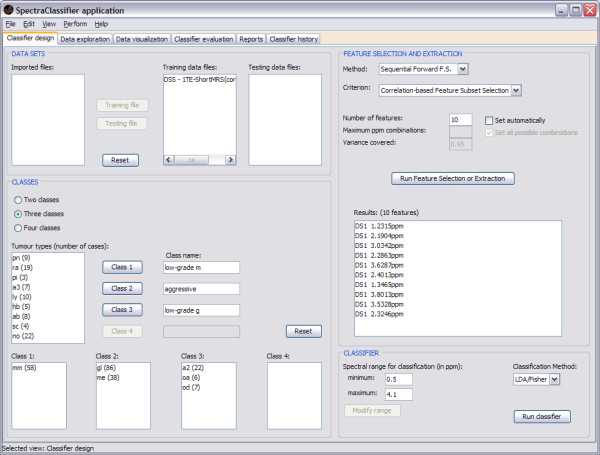
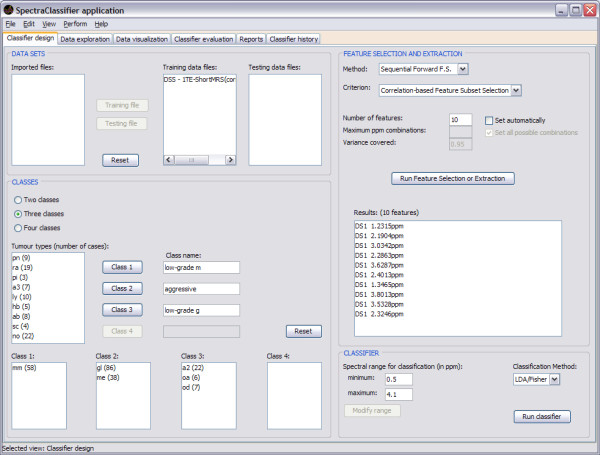
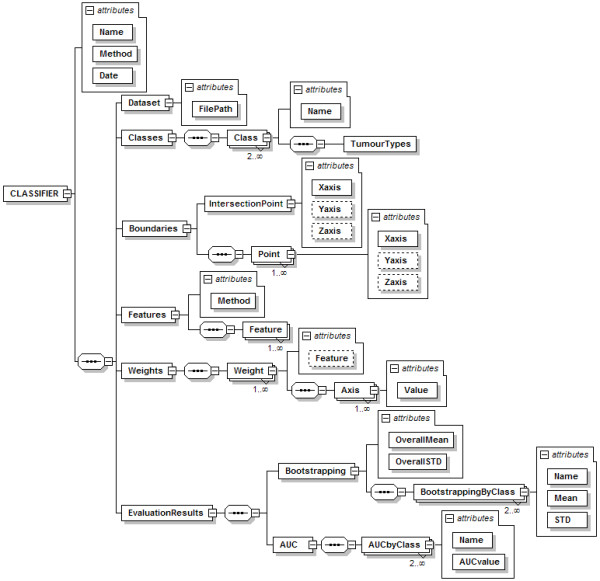
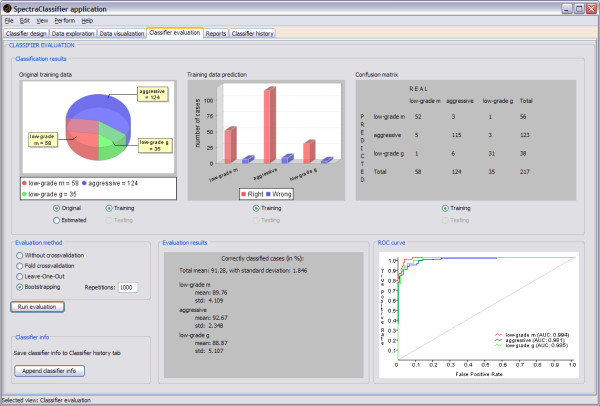
Background: SpectraClassifier (SC) is a Java solution for designing and implementing Magnetic Resonance Spectroscopy (MRS)-based classifiers. The main goal of SC is to allow users with minimum background knowledge of multivariate statistics to perform a fully automated pattern recognition analysis. SC incorporates feature selection (greedy stepwise approach, either forward or backward), and feature extraction (PCA). Fisher Linear Discriminant Analysis is the method of choice for classification. Classifier evaluation is performed through various methods: display of the confusion matrix of the training and testing datasets; K-fold cross-validation, leave-one-out and bootstrapping as well as Receiver Operating Characteristic (ROC) curves.
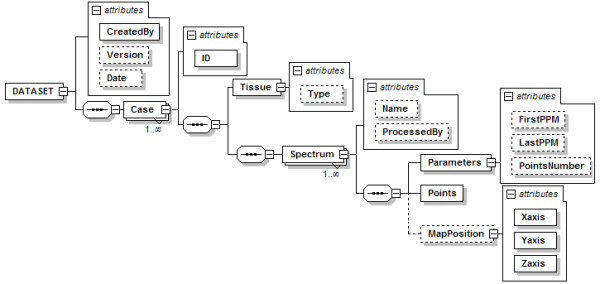
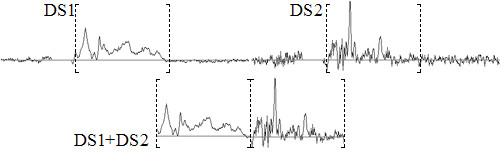
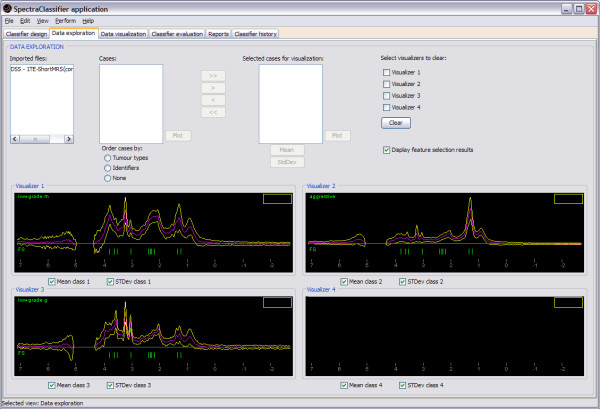
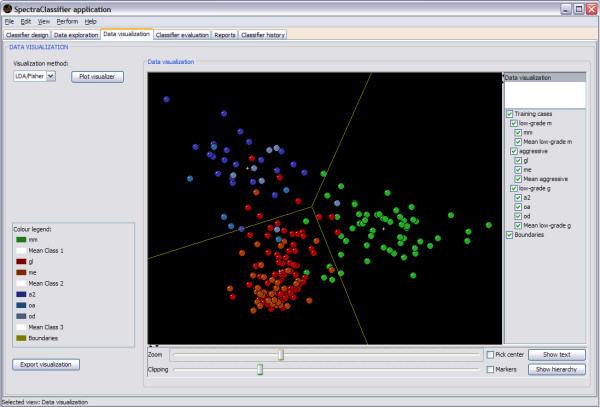
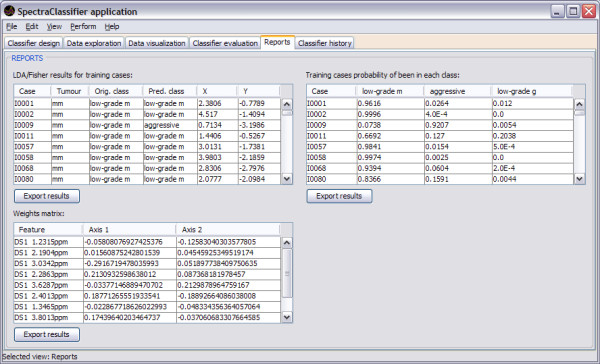
Results: SC is composed of the following modules: Classifier design, Data exploration, Data visualisation, Classifier evaluation, Reports, and Classifier history. It is able to read low resolution in-vivo MRS (single-voxel and multi-voxel) and high resolution tissue MRS (HRMAS), processed with existing tools (jMRUI, INTERPRET, 3DiCSI or TopSpin). In addition, to facilitate exchanging data between applications, a standard format capable of storing all the information needed for a dataset was developed. Each functionality of SC has been specifically validated with real data with the purpose of bug-testing and methods validation. Data from the INTERPRET project was used.
Conclusions: SC is a user-friendly software designed to fulfil the needs of potential users in the MRS community. It accepts all kinds of pre-processed MRS data types and classifies them semi-automatically, allowing spectroscopists to concentrate on interpretation of results with the use of its visualisation tools.
Figures

Similar articles
-
Feature selection and nearest centroid classification for protein mass spectrometry.BMC Bioinformatics. 2005 Mar 23;6:68. doi: 10.1186/1471-2105-6-68. BMC Bioinformatics. 2005. PMID: 15788095 Free PMC article.
-
Comparison of feature selection and classification for MALDI-MS data.BMC Genomics. 2009 Jul 7;10 Suppl 1(Suppl 1):S3. doi: 10.1186/1471-2164-10-S1-S3. BMC Genomics. 2009. PMID: 19594880 Free PMC article.
-
Brain metabolic pattern analysis using a magnetic resonance spectra classification software in experimental stroke.BMC Neurosci. 2017 Jan 13;18(1):13. doi: 10.1186/s12868-016-0328-x. BMC Neurosci. 2017. PMID: 28086802 Free PMC article.
-
Effect of finite sample size on feature selection and classification: a simulation study.Med Phys. 2010 Feb;37(2):907-20. doi: 10.1118/1.3284974. Med Phys. 2010. PMID: 20229900 Free PMC article.
-
Comparing radiomic classifiers and classifier ensembles for detection of peripheral zone prostate tumors on T2-weighted MRI: a multi-site study.BMC Med Imaging. 2019 Feb 28;19(1):22. doi: 10.1186/s12880-019-0308-6. BMC Med Imaging. 2019. PMID: 30819131 Free PMC article.
Cited by
-
Tracking Therapy Response in Glioblastoma Using 1D Convolutional Neural Networks.Cancers (Basel). 2023 Aug 7;15(15):4002. doi: 10.3390/cancers15154002. Cancers (Basel). 2023. PMID: 37568818 Free PMC article.
-
Robust Conditional Independence maps of single-voxel Magnetic Resonance Spectra to elucidate associations between brain tumours and metabolites.PLoS One. 2020 Jul 1;15(7):e0235057. doi: 10.1371/journal.pone.0235057. eCollection 2020. PLoS One. 2020. PMID: 32609725 Free PMC article.
-
Noninvasive Quantification of 2-Hydroxyglutarate in Human Gliomas with IDH1 and IDH2 Mutations.Cancer Res. 2016 Jan 1;76(1):43-9. doi: 10.1158/0008-5472.CAN-15-0934. Epub 2015 Dec 15. Cancer Res. 2016. PMID: 26669865 Free PMC article.
-
Non-negative matrix factorisation methods for the spectral decomposition of MRS data from human brain tumours.BMC Bioinformatics. 2012 Mar 8;13:38. doi: 10.1186/1471-2105-13-38. BMC Bioinformatics. 2012. PMID: 22401579 Free PMC article.
-
Embedding MRI information into MRSI data source extraction improves brain tumour delineation in animal models.PLoS One. 2019 Aug 15;14(8):e0220809. doi: 10.1371/journal.pone.0220809. eCollection 2019. PLoS One. 2019. PMID: 31415601 Free PMC article.
References
-
- Bruhn H, Frahm J, Gyngell ML, Merboldt KD, Hänicke W, Sauter R, Hamburger C. Noninvasive differentiation of tumors with use of localized H-1 MR spectroscopy in vivo: initial experience in patients with cerebral tumors. Radiology. 1989;172(2):541–548. - PubMed
-
- Negendank W. Studies of human tumors by MRS: a review. NMR in Biomedicine. 1992;5(5):303–324. - PubMed
-
- Tate AR, Griffiths JR, Martínez-Pérez I, À M, Barba I, Cabañas ME, Watson D, Alonso J, Bartumeus F, Isamat F. Towards a method for automated classification of 1H MRS spectra from brain tumours. NMR in Biomedicine. 1998;11(4-5):177–191. doi: 10.1002/(SICI)1099-1492(199806/08)11:4/5<177::AID-NBM534>3.0.CO;2-U. - DOI - PubMed
-
- Tate A, Underwood J, Acosta D, Julià-Sapé M, Majós C, Moreno-Torres A, Howe F, Graaf M van der, Lefournier V, Murphy M. Development of a decision support system for diagnosis and grading of brain tumours using in vivo magnetic resonance single voxel spectra. NMR in Biomedicine. 2006;19(4):411–434. doi: 10.1002/nbm.1016. - DOI - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
