

Proteogenomics of Pristionchus pacificus reveals distinct proteome structure of nematode models
- PMID: 20237107
- PMCID: PMC2877580
- DOI: 10.1101/gr.103119.109
Proteogenomics of Pristionchus pacificus reveals distinct proteome structure of nematode models
Abstract
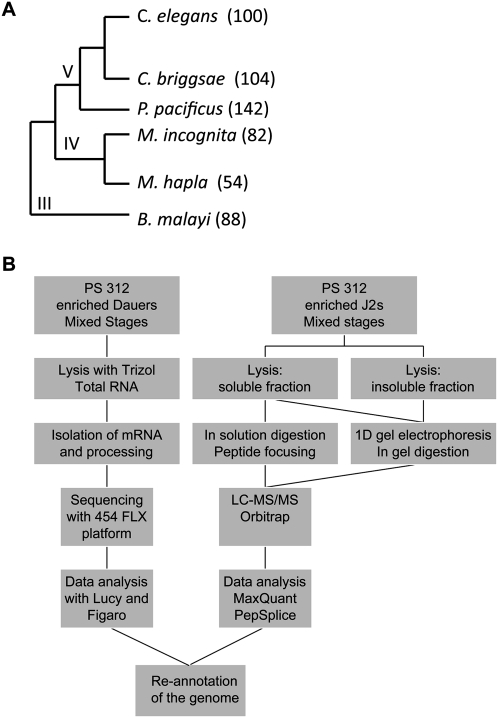
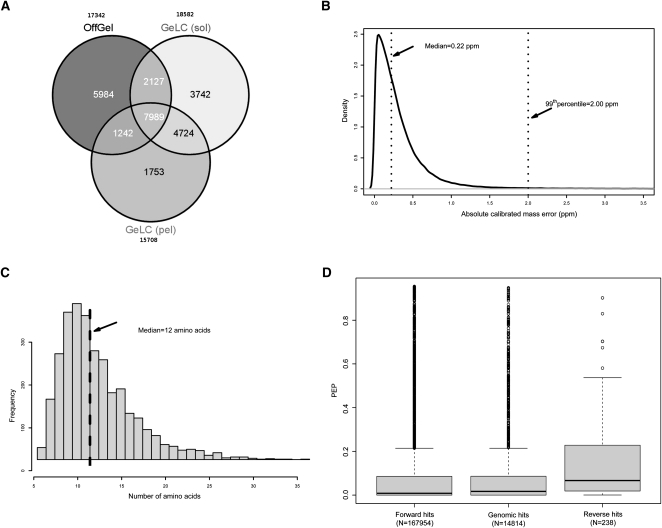
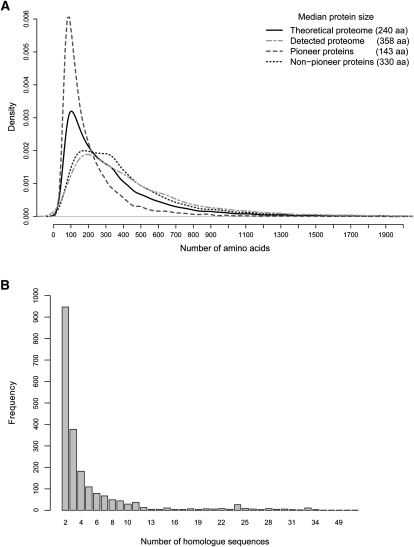
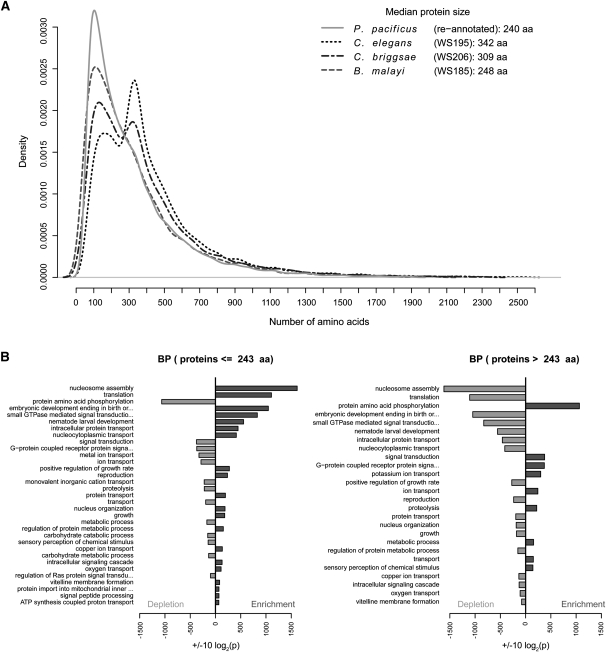
Pristionchus pacificus is a nematode model organism whose genome has recently been sequenced. To refine the genome annotation we performed transcriptome and proteome analysis and gathered comprehensive experimental information on gene expression. Transcriptome analysis on a 454 Life Sciences (Roche) FLX platform generated >700,000 expressed sequence tags (ESTs) from two normalized EST libraries, whereas proteome analysis on an LTQ-Orbitrap mass spectrometer detected >27,000 nonredundant peptide sequences from more than 4000 proteins at sub-parts-per-million (ppm) mass accuracy and a false discovery rate of <1%. Retraining of the SNAP gene prediction algorithm using the gene expression data led to a decrease in the number of previously predicted protein-coding genes from 29,000 to 24,000 and refinement of numerous gene models. The P. pacificus proteome contains a high proportion of small proteins with no known homologs in other species ("pioneer" proteins). Some of these proteins appear to be products of highly homologous genes, pointing to their common origin. We show that >50% of all pioneer genes are transcribed under standard culture conditions and that pioneer proteins significantly contribute to a unimodal distribution of predicted protein sizes in P. pacificus, which has an unusually low median size of 240 amino acids (26.8 kDa). In contrast, the predicted proteome of Caenorhabditis elegans follows a distinct bimodal protein size distribution, with significant functional differences between small and large protein populations. Combined, these results provide the first catalog of the expressed genome of P. pacificus, refinement of its genome annotation, and the first comparison of related nematode models at the proteome level.
Figures

References
-
- Alexa A, Rahnenfuhrer J, Lengauer T 2006. Improved scoring of functional groups from gene expression data by decorrelating GO graph structure. Bioinformatics 22: 1600–1607 - PubMed
-
- Ansong C, Purvine SO, Adkins JN, Lipton MS, Smith RD 2008. Proteogenomics: Needs and roles to be filled by proteomics in genome annotation. Brief Funct Genomics Proteomics 7: 50–62 - PubMed
-
- Baerenfaller K, Grossmann J, Grobei MA, Hull R, Hirsch-Hoffmann M, Yalovsky S, Zimmermann P, Grossniklaus U, Gruissem W, Baginsky S 2008. Genome-scale proteomics reveals Arabidopsis thaliana gene models and proteome dynamics. Science 320: 938–941 - PubMed
-
- Benjamini Y, Hochberg Y 1995. Controlling the false discovery rate—a practical and powerful approach to multiple testing. J R Stat Soc Ser B Methodol 57: 289–300
-
- The C. elegans Sequencing Consortium 1998. Genome sequence of the nematode C. elegans: A platform for investigating biology. Science 282: 2012–2018 - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials