

Shared probe design and existing microarray reanalysis using PICKY
- PMID: 20406469
- PMCID: PMC2875240
- DOI: 10.1186/1471-2105-11-196
Shared probe design and existing microarray reanalysis using PICKY
Abstract
Background: Large genomes contain families of highly similar genes that cannot be individually identified by microarray probes. This limitation is due to thermodynamic restrictions and cannot be resolved by any computational method. Since gene annotations are updated more frequently than microarrays, another common issue facing microarray users is that existing microarrays must be routinely reanalyzed to determine probes that are still useful with respect to the updated annotations.
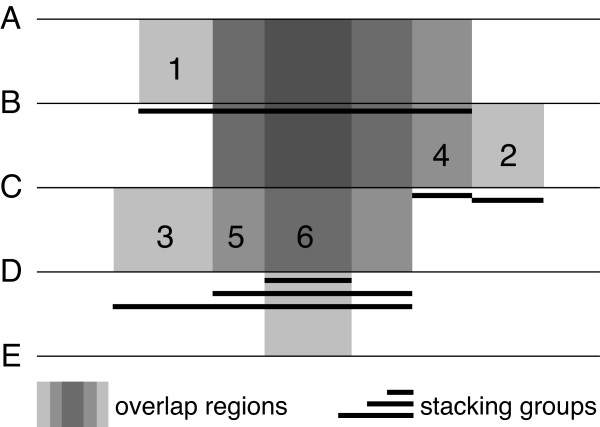
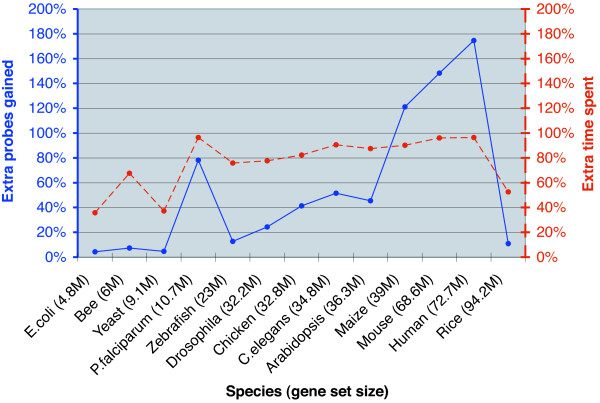
Results: PICKY 2.0 can design shared probes for sets of genes that cannot be individually identified using unique probes. PICKY 2.0 uses novel algorithms to track sharable regions among genes and to strictly distinguish them from other highly similar but nontarget regions during thermodynamic comparisons. Therefore, PICKY does not sacrifice the quality of shared probes when choosing them. The latest PICKY 2.1 includes the new capability to reanalyze existing microarray probes against updated gene sets to determine probes that are still valid to use. In addition, more precise nonlinear salt effect estimates and other improvements are added, making PICKY 2.1 more versatile to microarray users.
Conclusions: Shared probes allow expressed gene family members to be detected; this capability is generally more desirable than not knowing anything about these genes. Shared probes also enable the design of cross-genome microarrays, which facilitate multiple species identification in environmental samples. The new nonlinear salt effect calculation significantly increases the precision of probes at a lower buffer salt concentration, and the probe reanalysis function improves existing microarray result interpretations.
Figures




References
-
- Coblentz FE, Towle DW, Shafer TH. Expressed sequence tags from normalized cDNA libraries prepared from gill and hypodermal tissues of the blue crab, Callinectes sapidus. Comparative Biochemistry And Physiology D-Genomics & Proteomics. 2006;1:200–208. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
