

Modelling the role of task in the control of gaze
- PMID: 20411027
- PMCID: PMC2856937
- DOI: 10.1080/13506280902978477
Modelling the role of task in the control of gaze
Abstract
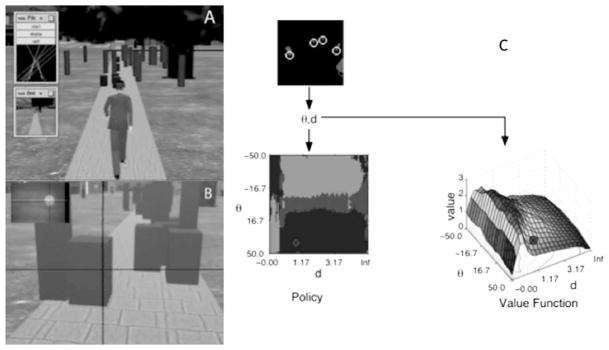
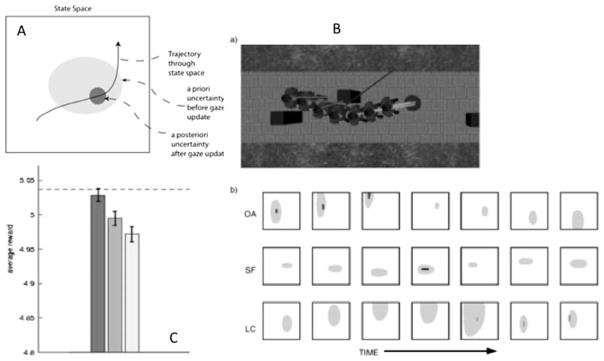
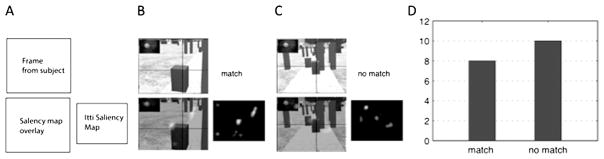
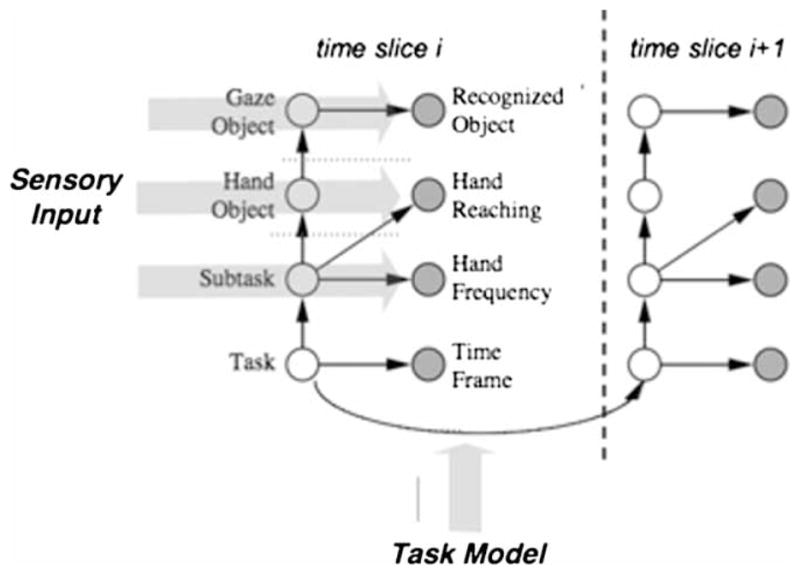
Gaze changes and the resultant fixations that orchestrate the sequential acquisition of information from the visual environment are the central feature of primate vision. How are we to understand their function? For the most part, theories of fixation targets have been image based: The hypothesis being that the eye is drawn to places in the scene that contain discontinuities in image features such as motion, colour, and texture. But are these features the cause of the fixations, or merely the result of fixations that have been planned to serve some visual function? This paper examines the issue and reviews evidence from various image-based and task-based sources. Our conclusion is that the evidence is overwhelmingly in favour of fixation control being essentially task based.
Figures


References
-
- Aivar P, Hayhoe M, Mruczek R. Role of spatial memory in saccadic targeting in natural tasks. Journal of Vision. 2005;5:177–193. - PubMed
-
- Ballard D, Hayhoe M, Pelz J. Memory representations in natural tasks. Journal of Cognitive Neuroscience. 1995;7:66–80. - PubMed
-
- Ballard D, Hayhoe M, Pook P, Rao R. Deictic codes for the embodiment of cognition. Behavioral and Brain Sciences. 1997;20:723–767. - PubMed
-
- Bonasso R, Firby R, Kortenkamp D, Miller D, Slack M. Experiences with an architecture for intelligent reactive agents. Journal of Experimental and Theoretical Artificial Intelligence. 1997;9:237–256.
-
- Buswell GT. How people look at pictures. Chicago: University of Chicago Press; 1935.
Grants and funding
LinkOut - more resources
Full Text Sources