

Polyglutamine induced misfolding of huntingtin exon1 is modulated by the flanking sequences
- PMID: 20442863
- PMCID: PMC2861695
- DOI: 10.1371/journal.pcbi.1000772
Polyglutamine induced misfolding of huntingtin exon1 is modulated by the flanking sequences
Abstract
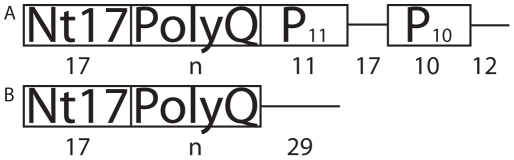
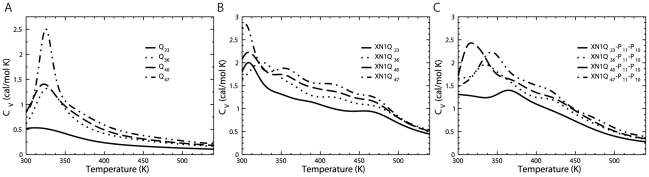
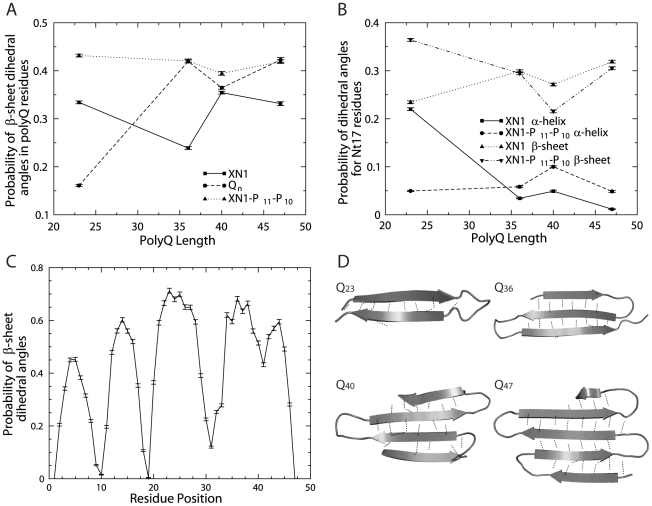
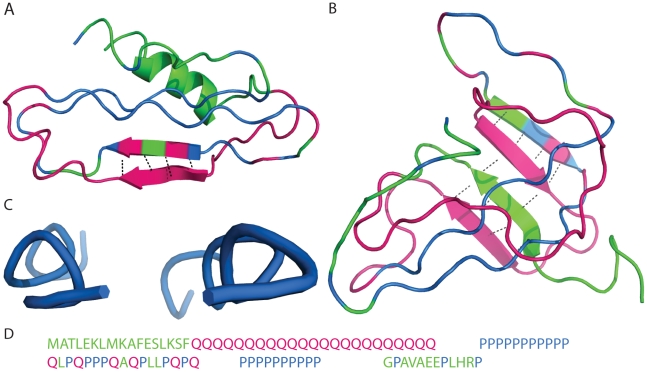
Polyglutamine (polyQ) expansion in exon1 (XN1) of the huntingtin protein is linked to Huntington's disease. When the number of glutamines exceeds a threshold of approximately 36-40 repeats, XN1 can readily form amyloid aggregates similar to those associated with disease. Many experiments suggest that misfolding of monomeric XN1 plays an important role in the length-dependent aggregation. Elucidating the misfolding of a XN1 monomer can help determine the molecular mechanism of XN1 aggregation and potentially help develop strategies to inhibit XN1 aggregation. The flanking sequences surrounding the polyQ region can play a critical role in determining the structural rearrangement and aggregation mechanism of XN1. Few experiments have studied XN1 in its entirety, with all flanking regions. To obtain structural insights into the misfolding of XN1 toward amyloid aggregation, we perform molecular dynamics simulations on monomeric XN1 with full flanking regions, a variant missing the polyproline regions, which are hypothesized to prevent aggregation, and an isolated polyQ peptide (Q(n)). For each of these three constructs, we study glutamine repeat lengths of 23, 36, 40 and 47. We find that polyQ peptides have a positive correlation between their probability to form a beta-rich misfolded state and their expansion length. We also find that the flanking regions of XN1 affect its probability to form a beta-rich state compared to the isolated polyQ. Particularly, the polyproline regions form polyproline type II helices and decrease the probability of the polyQ region to form a beta-rich state. Additionally, by lengthening polyQ, the first N-terminal 17 residues are more likely to adopt a beta-sheet conformation rather than an alpha-helix conformation. Therefore, our molecular dynamics study provides a structural insight of XN1 misfolding and elucidates the possible role of the flanking sequences in XN1 aggregation.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Similar articles
-
Structural insights into the aggregation mechanism of huntingtin exon 1 protein fragment with different polyQ-lengths.J Cell Biochem. 2019 Jun;120(6):10519-10529. doi: 10.1002/jcb.28338. Epub 2019 Jan 22. J Cell Biochem. 2019. PMID: 30672003
-
Polyglutamine amyloid core boundaries and flanking domain dynamics in huntingtin fragment fibrils determined by solid-state nuclear magnetic resonance.Biochemistry. 2014 Oct 28;53(42):6653-66. doi: 10.1021/bi501010q. Epub 2014 Oct 16. Biochemistry. 2014. PMID: 25280367 Free PMC article.
-
Slow amyloid nucleation via α-helix-rich oligomeric intermediates in short polyglutamine-containing huntingtin fragments.J Mol Biol. 2012 Feb 3;415(5):881-99. doi: 10.1016/j.jmb.2011.12.010. Epub 2011 Dec 9. J Mol Biol. 2012. PMID: 22178474 Free PMC article.
-
Multi-domain misfolding: understanding the aggregation pathway of polyglutamine proteins.Protein Eng Des Sel. 2009 Aug;22(8):447-51. doi: 10.1093/protein/gzp033. Epub 2009 Jul 9. Protein Eng Des Sel. 2009. PMID: 19589877 Review.
-
Towards the treatment of polyglutamine diseases: the modulatory role of protein context.Curr Med Chem. 2010;17(27):3058-68. doi: 10.2174/092986710791959800. Curr Med Chem. 2010. PMID: 20629626 Review.
Cited by
-
Substrate recognition in nuclear protein quality control degradation is governed by exposed hydrophobicity that correlates with aggregation and insolubility.J Biol Chem. 2013 Mar 1;288(9):6130-9. doi: 10.1074/jbc.M112.406710. Epub 2013 Jan 18. J Biol Chem. 2013. PMID: 23335508 Free PMC article.
-
Monomeric, oligomeric and polymeric proteins in huntington disease and other diseases of polyglutamine expansion.Brain Sci. 2014 Mar 3;4(1):91-122. doi: 10.3390/brainsci4010091. Brain Sci. 2014. PMID: 24961702 Free PMC article.
-
Polyglutamine- and temperature-dependent conformational rigidity in mutant huntingtin revealed by immunoassays and circular dichroism spectroscopy.PLoS One. 2014 Dec 2;9(12):e112262. doi: 10.1371/journal.pone.0112262. eCollection 2014. PLoS One. 2014. PMID: 25464275 Free PMC article.
-
Proteins Containing Expanded Polyglutamine Tracts and Neurodegenerative Disease.Biochemistry. 2017 Mar 7;56(9):1199-1217. doi: 10.1021/acs.biochem.6b00936. Epub 2017 Feb 21. Biochemistry. 2017. PMID: 28170216 Free PMC article. Review.
-
Defining the Neuropathological Aggresome across in Silico, in Vitro, and ex Vivo Experiments.J Phys Chem B. 2021 Mar 4;125(8):1974-1996. doi: 10.1021/acs.jpcb.0c09193. Epub 2021 Jan 19. J Phys Chem B. 2021. PMID: 33464098 Free PMC article. Review.
References
-
- Truant R, Atwal RS, Desmond C, Munsie L, Tran T. Huntington's disease: revisiting the aggregation hypothesis in polyglutamine neurodegenerative diseases. FEBS J. 2008;275:4252–62. - PubMed
-
- Ross CA. Polyglutamine Pathogenesis: Emergence of Unifying Mechanisms for Huntington's Disease and Related Disorders. Neuron. 2002;35:819–822. - PubMed
-
- Saunders HM, Bottomley SP. Multi-domain misfolding: understanding the aggregation pathway of polyglutamine proteins. Protein Eng Des Sel. 2009;22:447–51. - PubMed
-
- Ross CA, Poirier MA. Protein aggregation and neurodegenerative disease. Nat Med. 2004;10(Suppl):S10–7. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
