

Advances in protein NMR provided by the NIGMS Protein Structure Initiative: impact on drug discovery
- PMID: 20443167
- PMCID: PMC4002360
Advances in protein NMR provided by the NIGMS Protein Structure Initiative: impact on drug discovery
Abstract
Rational drug design relies on the 3D structures of biological macromolecules, with a particular emphasis on proteins. The structural genomics-based high-throughput structure determination platforms established by the Protein Structure Initiative (PSI) of the National Institute of General Medical Science (NIGMS) of the NIH are uniquely suited to provide these structures. NMR plays a critical role in structure determination because many important protein targets do not form the single crystals required for X-ray diffraction. NMR can provide valuable structural and dynamic information on proteins and their drug complexes that cannot be obtained with X-ray crystallography. This review discusses recent advances in NMR that have been driven by structural genomics projects. These advances suggest that the future discovery and design of drugs can increasingly rely on protocols using NMR approaches for the rapid and accurate determination of structures.
Figures





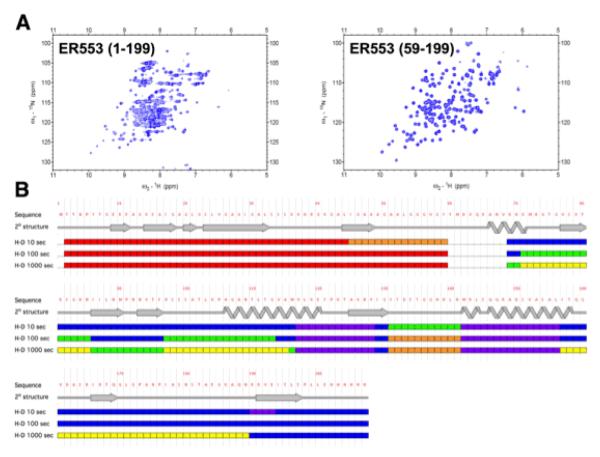
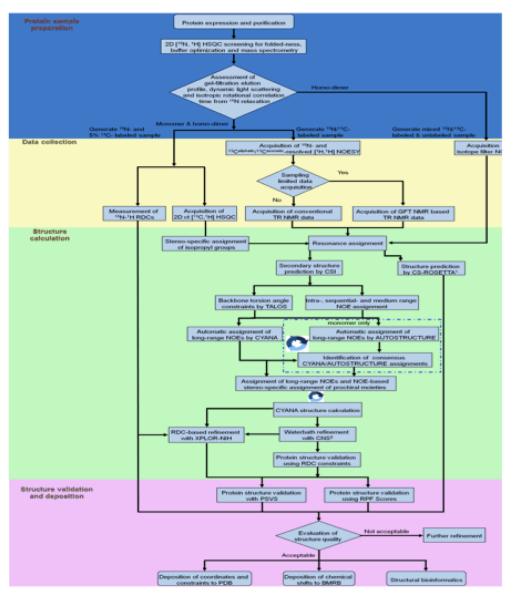
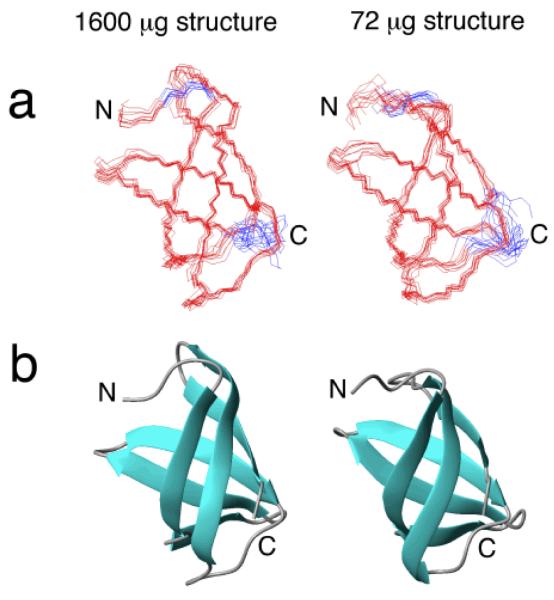
References
-
-
Liu J, Montelione GT, Rost B. Novel leverage of structural genomics. Nat Biotechnol. 2007;25:849–851. Describes the metric of “novel structural leverage” and an assessment of the impact of SG efforts in coverage of protein sequences with representative 3D structures.
-
-
-
Dessailly BH, Nair R, Jaroszewski L, Fajardo JE, Kouranov A, Lee D, Fiser A, Godzik A, Rost B, Orengo C. PSI-2: structural genomics to cover protein domain family space. Structure. 2009;17:869–881. Description of the targeting strategy of the PSI program for broad structural coverage, it rational, and progress, written by the group responsible for selecting these domain families.
-
-
-
Levitt M. Nature of the protein universe. Proc Natl Acad Sci U S A. 2009;106:11079–11084. Assessment of the numbers of domain families indicated by currently available protein sequence data, suggesting that the majority of protein sequences can be clustered into some 15,000 - 20,000 domain families.
-
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources