

Haplotype structure and expression divergence at the Drosophila cellular immune gene eater
- PMID: 20444883
- PMCID: PMC2944027
- DOI: 10.1093/molbev/msq114
Haplotype structure and expression divergence at the Drosophila cellular immune gene eater
Abstract
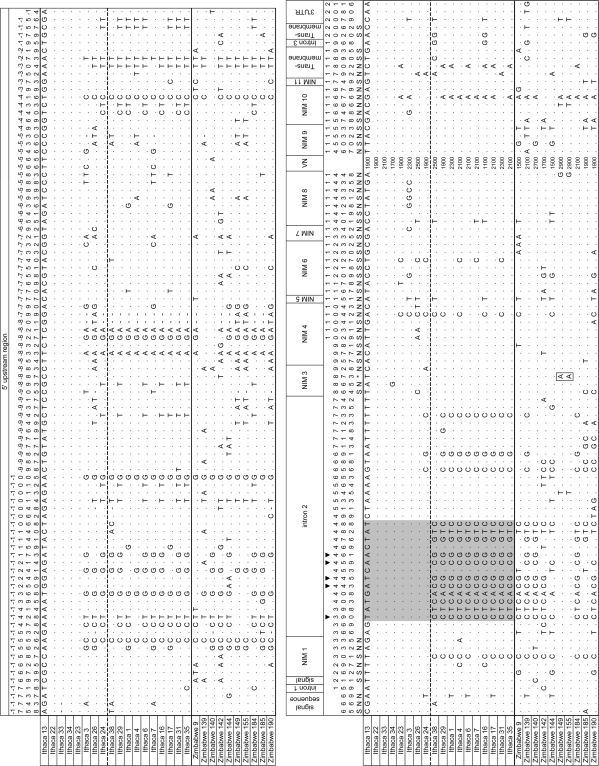
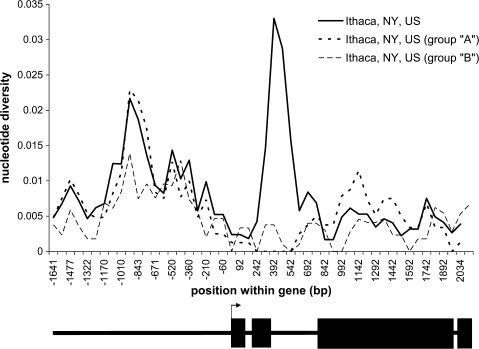
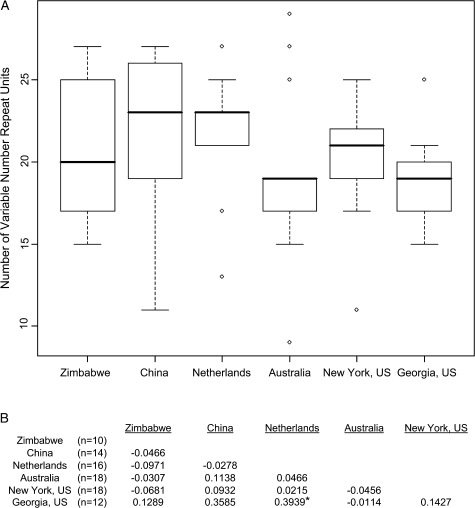
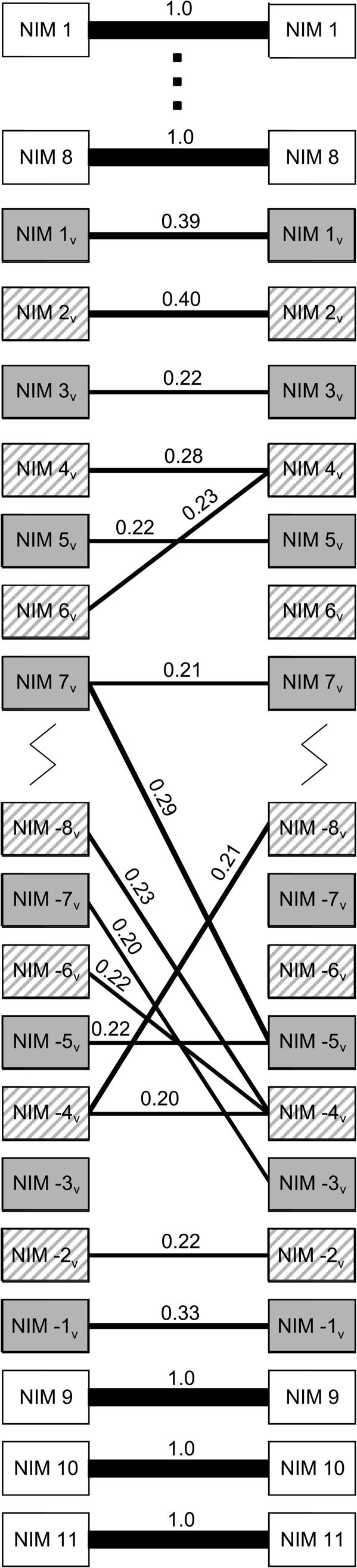
The protein Eater plays an important role in microbial recognition and defensive phagocytosis in Drosophila melanogaster. We sequenced multiple alleles of the eater gene from an African and a North American population of D. melanogaster and found signatures of a partial selective sweep in North America that is localized around the second intron. This pattern is consistent with local adaptation to novel selective pressures during range expansion out of Africa. The North American sample is divided into two predominant haplotype groups, and the putatively selected haplotype is associated with a significantly higher gene expression level, suggesting that gene regulation is a possible target of selection. The eater alleles contain from 22 to 40 repeat units that are characterized by the presence of a cysteine-rich NIM motif. NIM repeats in the structural stalk of the protein exhibit concerted evolution as a function of physical location in the repeat array. Several NIM repeats within eater have previously been implicated in binding to microbial ligands, a function which in principle might subject them to special evolutionary pressures. However, we find no evidence of elevated positive selection on these pathogen-interacting units. Our study presents an instance where gene expression rather than protein structure is thought to drive the adaptive evolution of a pathogen recognition molecule in the immune system.
Figures



References
-
- Adams MD, Celniker SE, Holt RA, et al. (195 co-authors) The genome sequence of Drosophila melanogaster. Science. 2000;287:2185–2195. - PubMed
-
- Aminetzach YT, Macpherson JM, Petrov DA. Pesticide resistance via transposition-mediated adaptive gene truncation in Drosophila. Science. 2005;309:764–767. - PubMed
-
- Baudry E, Viginier B, Veuille M. Non-African populations of Drosophila melanogaster. Mol Biol Evol. 2004;21:1482–1491. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
