

Multi-PIE
- PMID: 20490373
- PMCID: PMC2873597
- DOI: 10.1016/j.imavis.2009.08.002
Multi-PIE
Abstract
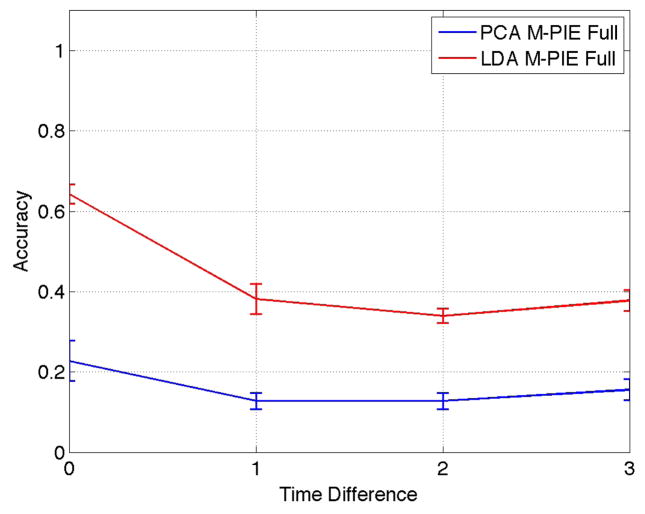
A close relationship exists between the advancement of face recognition algorithms and the availability of face databases varying factors that affect facial appearance in a controlled manner. The CMU PIE database has been very influential in advancing research in face recognition across pose and illumination. Despite its success the PIE database has several shortcomings: a limited number of subjects, single recording session and only few expressions captured. To address these issues we collected the CMU Multi-PIE database. It contains 337 subjects, imaged under 15 view points and 19 illumination conditions in up to four recording sessions. In this paper we introduce the database and describe the recording procedure. We furthermore present results from baseline experiments using PCA and LDA classifiers to highlight similarities and differences between PIE and Multi-PIE.
Figures











References
-
- Belhumeur P, Hespanha J, Kriegman D. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1997;19(7):711–720.
-
- Beveridge R, Bolme D, Draper B, Teixeira M. The CSU face identification evaluation system. Machine Vision and Applications. 2005;16:128–138.
-
- Cootes T, Edwards G, Taylor C. Active appearance models. IEEE Transaction on Pattern Analysis and Machine Intelligence. 2001;23(6)
-
- Delac K, Grgic M, Grgic S. Independent comparative study of PCA, ICA, and LDA on the FERET data set. International Journal of Imaging Systems and Technology. 2005;15(5):252–260.
-
- Georghiades A, Kriegman D, Belhumeur P. From few to many: generative models for recognition under variable pose and illumination. IEEE Transaction on Pattern Analysis and Machine Intelligence. 2001;23(6):643–660.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources