

SARS coronavirus unique domain: three-domain molecular architecture in solution and RNA binding
- PMID: 20493876
- PMCID: PMC2958096
- DOI: 10.1016/j.jmb.2010.05.027
SARS coronavirus unique domain: three-domain molecular architecture in solution and RNA binding
Abstract
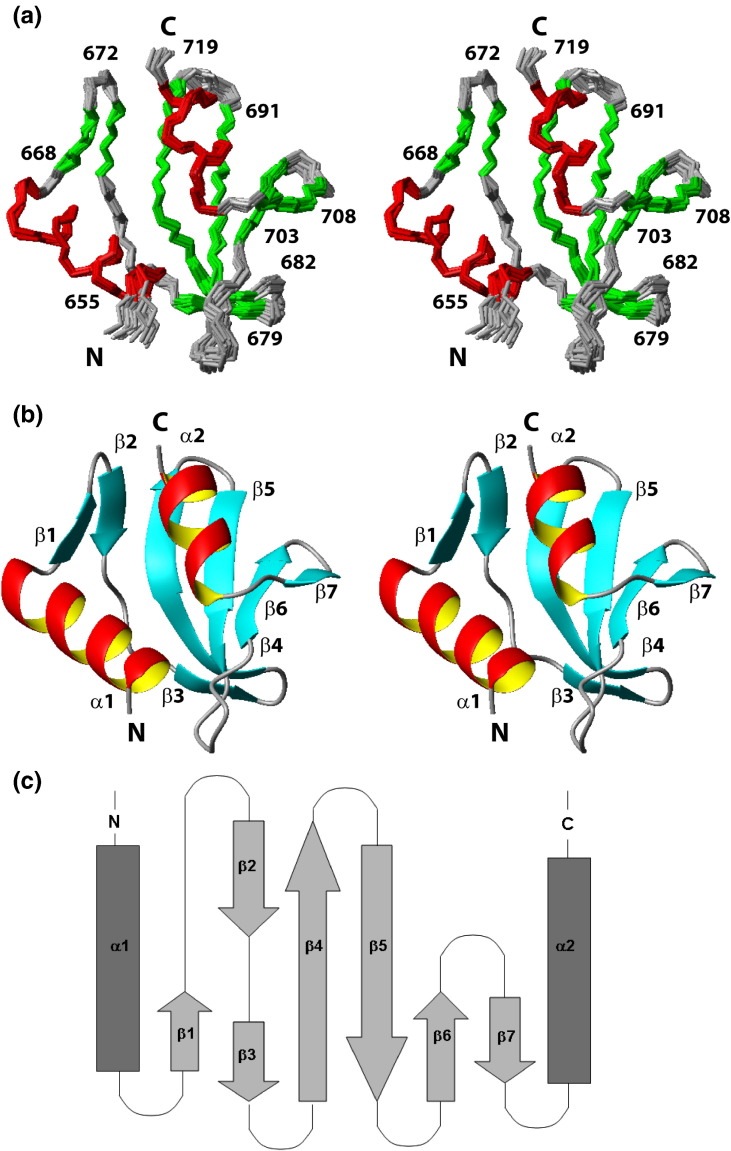
Nonstructural protein 3 of the severe acute respiratory syndrome (SARS) coronavirus includes a "SARS-unique domain" (SUD) consisting of three globular domains separated by short linker peptide segments. This work reports NMR structure determinations of the C-terminal domain (SUD-C) and a two-domain construct (SUD-MC) containing the middle domain (SUD-M) and the C-terminal domain, and NMR data on the conformational states of the N-terminal domain (SUD-N) and the SUD-NM two-domain construct. Both SUD-N and SUD-NM are monomeric and globular in solution; in SUD-NM, there is high mobility in the two-residue interdomain linking sequence, with no preferred relative orientation of the two domains. SUD-C adopts a frataxin like fold and has structural similarity to DNA-binding domains of DNA-modifying enzymes. The structures of both SUD-M (previously determined) and SUD-C (from the present study) are maintained in SUD-MC, where the two domains are flexibly linked. Gel-shift experiments showed that both SUD-C and SUD-MC bind to single-stranded RNA and recognize purine bases more strongly than pyrimidine bases, whereby SUD-MC binds to a more restricted set of purine-containing RNA sequences than SUD-M. NMR chemical shift perturbation experiments with observations of (15)N-labeled proteins further resulted in delineation of RNA binding sites (i.e., in SUD-M, a positively charged surface area with a pronounced cavity, and in SUD-C, several residues of an anti-parallel beta-sheet). Overall, the present data provide evidence for molecular mechanisms involving the concerted actions of SUD-M and SUD-C, which result in specific RNA binding that might be unique to the SUD and, thus, to the SARS coronavirus.
Copyright (c) 2010 Elsevier Ltd. All rights reserved.
Figures









References
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
