

Semantic annotation of morphological descriptions: an overall strategy
- PMID: 20500882
- PMCID: PMC2887808
- DOI: 10.1186/1471-2105-11-278
Semantic annotation of morphological descriptions: an overall strategy
Abstract
Background: Large volumes of morphological descriptions of whole organisms have been created as print or electronic text in a human-readable format. Converting the descriptions into computer- readable formats gives a new life to the valuable knowledge on biodiversity. Research in this area started 20 years ago, yet not sufficient progress has been made to produce an automated system that requires only minimal human intervention but works on descriptions of various plant and animal groups. This paper attempts to examine the hindering factors by identifying the mismatches between existing research and the characteristics of morphological descriptions.
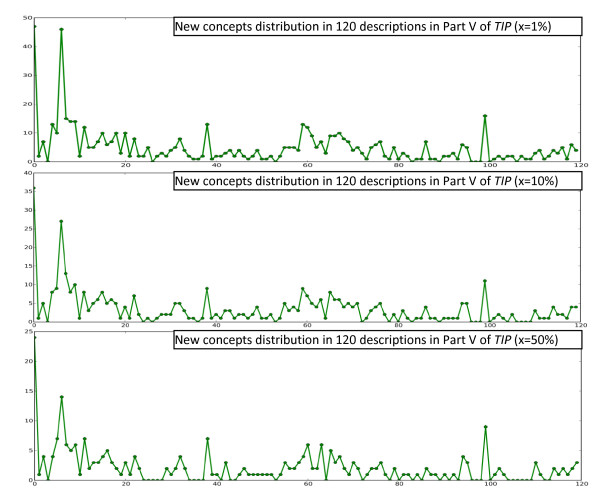
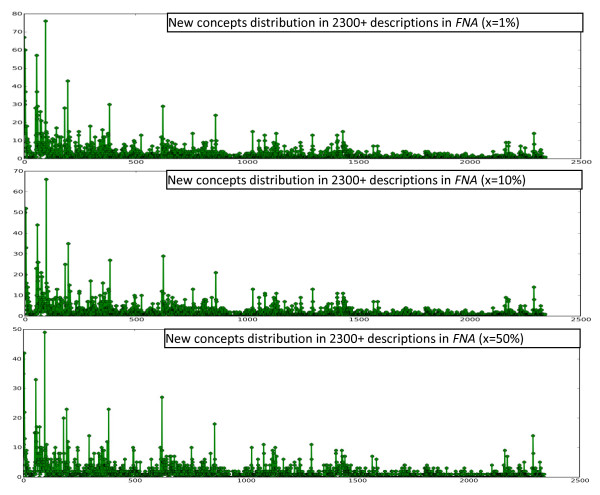
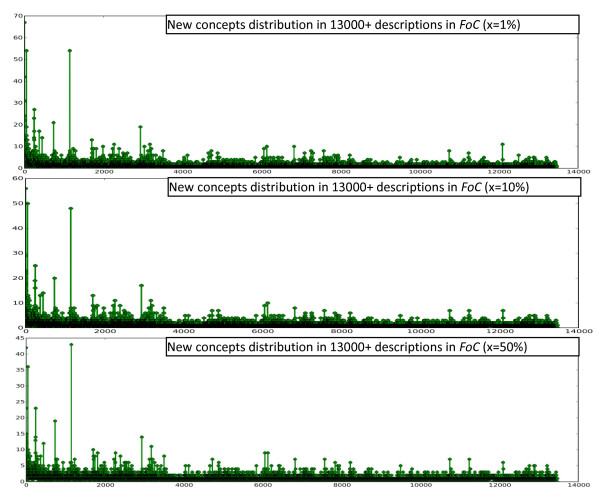
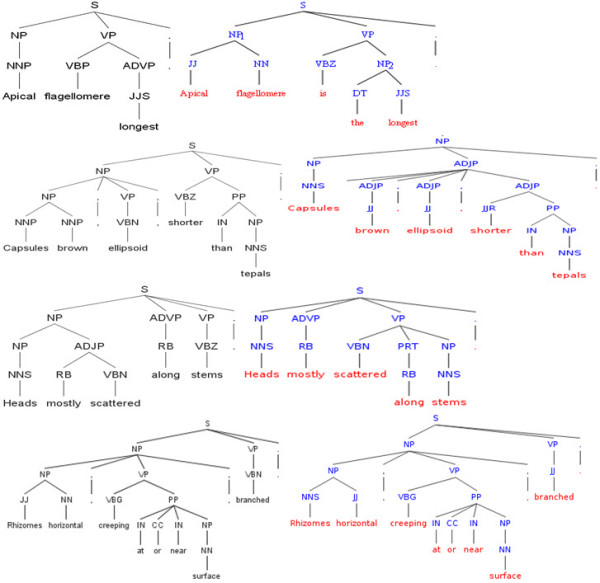
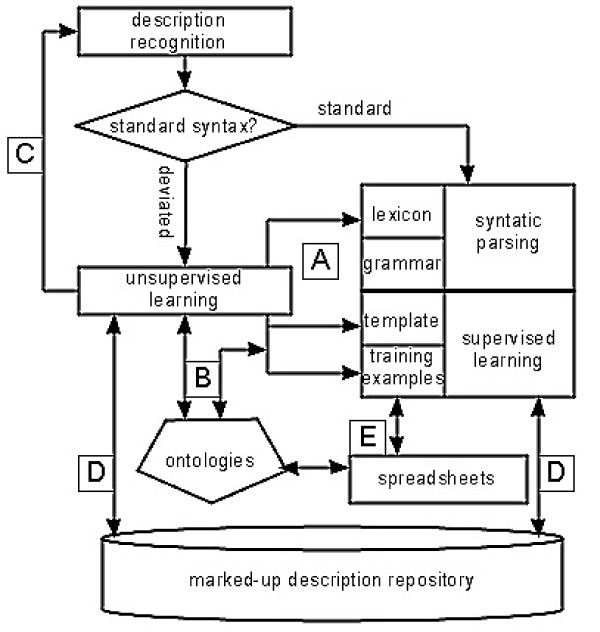
Results: This paper reviews the techniques that have been used for automated annotation, reports exploratory results on characteristics of morphological descriptions as a genre, and identifies challenges facing automated annotation systems. Based on these criteria, the paper proposes an overall strategy for converting descriptions of various taxon groups with the least human effort.
Conclusions: A combined unsupervised and supervised machine learning strategy is needed to construct domain ontologies and lexicons and to ultimately achieve automated semantic annotation of morphological descriptions. Further, we suggest that each effort in creating a new description or annotating an individual description collection should be shared and contribute to the "biodiversity information commons" for the Semantic Web. This cannot be done without a sound strategy and a close partnership between and among information scientists and biologists.
Figures


References
-
- Flora of North America Editorial Committee (Eds): Flora of North America. http://www.fna.org/
-
- Tang X, Heidorn PB. Using automatically extracted information in species page retrieval. Proceedings of TDWG. 2007. http://www.tdwg.org/proceedings/article/view/195
-
- Cui H, Macklin J, Yu C. Application of semantic annotation for quality insurance in biosystematics publishing. Proceedings of the Annual Meeting of American Society of Information Science and Technology 2009 (in CD) 2009.
-
- Taylor A. Extracting knowledge from biological descriptions. Proceedings of 2nd International Conference on Building and Sharing Very Large-Scale Knowledge Bases. 1995. pp. 114–119.
-
- Abascal R, Sanchenz J. X-tract: Structure extraction from botanical textual descriptions. Proceeding of the String Processing & Information Retrieval Symposium. 1999. pp. 2–7.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
