

Principal semantic components of language and the measurement of meaning
- PMID: 20552009
- PMCID: PMC2883995
- DOI: 10.1371/journal.pone.0010921
Principal semantic components of language and the measurement of meaning
Erratum in
- PLoS One. 2010;5(7). doi: 10.1371/annotation/76179ada-64b5-4931-8f2d-3528f17d8359. Samsonovic, Alexei V [corrected to Samsonovich, Alexei V]
Abstract
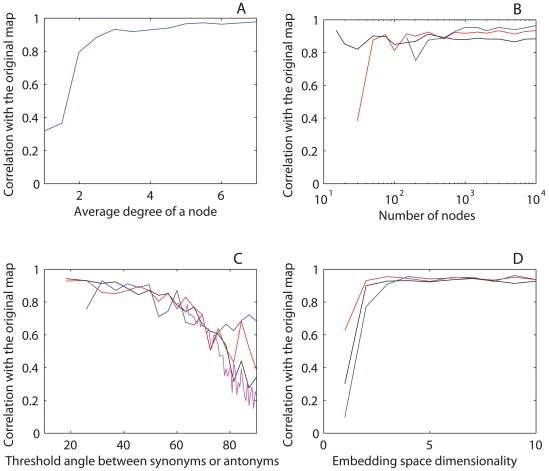
Metric systems for semantics, or semantic cognitive maps, are allocations of words or other representations in a metric space based on their meaning. Existing methods for semantic mapping, such as Latent Semantic Analysis and Latent Dirichlet Allocation, are based on paradigms involving dissimilarity metrics. They typically do not take into account relations of antonymy and yield a large number of domain-specific semantic dimensions. Here, using a novel self-organization approach, we construct a low-dimensional, context-independent semantic map of natural language that represents simultaneously synonymy and antonymy. Emergent semantics of the map principal components are clearly identifiable: the first three correspond to the meanings of "good/bad" (valence), "calm/excited" (arousal), and "open/closed" (freedom), respectively. The semantic map is sufficiently robust to allow the automated extraction of synonyms and antonyms not originally in the dictionaries used to construct the map and to predict connotation from their coordinates. The map geometric characteristics include a limited number ( approximately 4) of statistically significant dimensions, a bimodal distribution of the first component, increasing kurtosis of subsequent (unimodal) components, and a U-shaped maximum-spread planar projection. Both the semantic content and the main geometric features of the map are consistent between dictionaries (Microsoft Word and Princeton's WordNet), among Western languages (English, French, German, and Spanish), and with previously established psychometric measures. By defining the semantics of its dimensions, the constructed map provides a foundational metric system for the quantitative analysis of word meaning. Language can be viewed as a cumulative product of human experiences. Therefore, the extracted principal semantic dimensions may be useful to characterize the general semantic dimensions of the content of mental states. This is a fundamental step toward a universal metric system for semantics of human experiences, which is necessary for developing a rigorous science of the mind.
Conflict of interest statement
Figures









Similar articles
-
Augmenting weak semantic cognitive maps with an "abstractness" dimension.Comput Intell Neurosci. 2013;2013:308176. doi: 10.1155/2013/308176. Epub 2013 Jun 12. Comput Intell Neurosci. 2013. PMID: 23840200 Free PMC article.
-
Using EEG to decode semantics during an artificial language learning task.Brain Behav. 2021 Aug;11(8):e2234. doi: 10.1002/brb3.2234. Epub 2021 Jun 15. Brain Behav. 2021. PMID: 34129727 Free PMC article.
-
Latent Relations at Steady-state with Associative Nets.Cogn Sci. 2024 Sep;48(9):e13494. doi: 10.1111/cogs.13494. Cogn Sci. 2024. PMID: 39283248
-
The principals of meaning: Extracting semantic dimensions from co-occurrence models of semantics.Psychon Bull Rev. 2016 Dec;23(6):1744-1756. doi: 10.3758/s13423-016-1053-2. Psychon Bull Rev. 2016. PMID: 27138012 Review.
-
The principal components of meaning, revisited.Psychon Bull Rev. 2025 Feb;32(1):203-225. doi: 10.3758/s13423-024-02551-y. Epub 2024 Aug 22. Psychon Bull Rev. 2025. PMID: 39174751 Review.
Cited by
-
Wikipedia information flow analysis reveals the scale-free architecture of the semantic space.PLoS One. 2011 Feb 28;6(2):e17333. doi: 10.1371/journal.pone.0017333. PLoS One. 2011. PMID: 21407801 Free PMC article.
-
Augmenting weak semantic cognitive maps with an "abstractness" dimension.Comput Intell Neurosci. 2013;2013:308176. doi: 10.1155/2013/308176. Epub 2013 Jun 12. Comput Intell Neurosci. 2013. PMID: 23840200 Free PMC article.
-
The mind-brain relationship as a mathematical problem.ISRN Neurosci. 2013 Apr 14;2013:261364. doi: 10.1155/2013/261364. eCollection 2013. ISRN Neurosci. 2013. PMID: 24967307 Free PMC article. Review.
References
-
- Fellbaum C. WordNet: An electronic lexical database. Cambridge, MA: MIT Press; 1998.
-
- Ascoli GA, Samsonovich AV. Science of the conscious mind. Biol Bull. 2008;215:204–215. - PubMed
-
- Tversky A, Gati I. Similarity, separability, and the triangle inequality. Psychol Rev. 1982;89:123–154. - PubMed
-
- Landauer TK, Dumais ST. A solution to Plato's problem: the Latent Semantic Analysis theory of acquisition, induction, and representation of knowledge. Psyc Rev. 1997;104:211–240.
-
- Landauer TK, McNamara DS, Dennis S, Kintsch W, editors. Handbook of Latent Semantic Analysis. Mahwah, NJ: Lawrence Erlbaum Associates; 2007.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
