

An "almost exhaustive" search-based sequential permutation method for detecting epistasis in disease association studies
- PMID: 20583286
- PMCID: PMC4830696
- DOI: 10.1002/gepi.20496
An "almost exhaustive" search-based sequential permutation method for detecting epistasis in disease association studies
Abstract
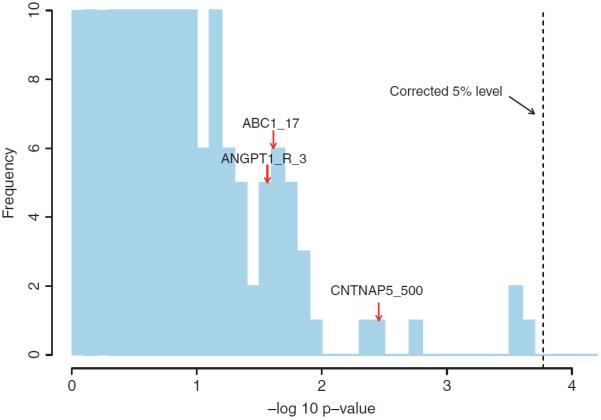
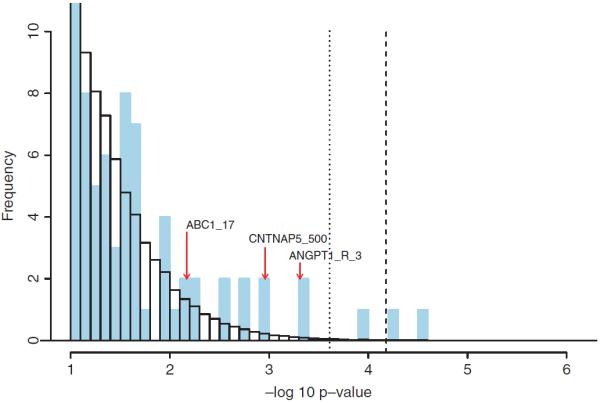
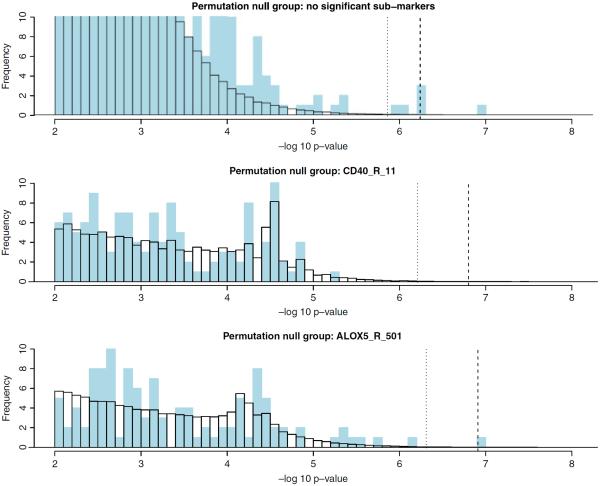
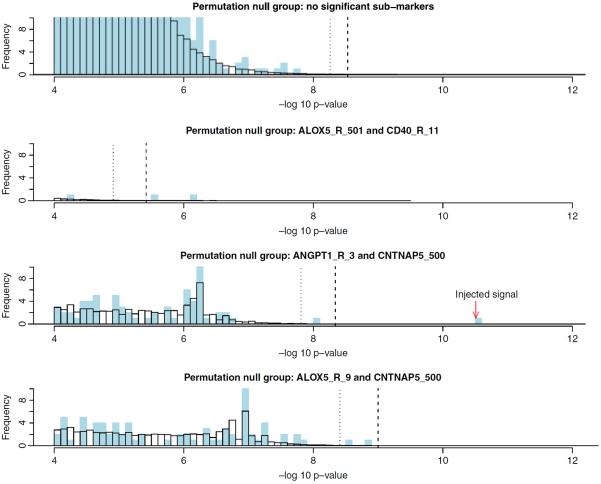
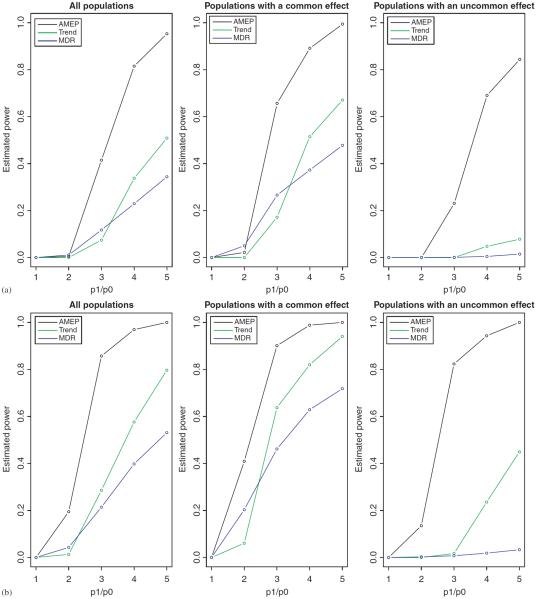
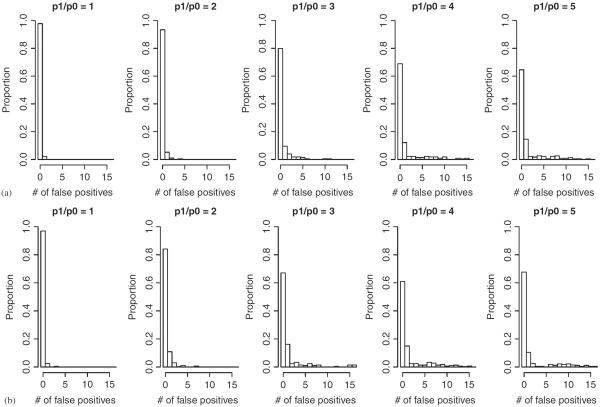
Due to the complex nature of common diseases, their etiology is likely to involve "uncommon but strong" (UBS) interactive effects--i.e. allelic combinations that are each present in only a small fraction of the patients but associated with high disease risk. However, the identification of such effects using standard methods for testing association can be difficult. In this work, we introduce a method for testing interactions that is particularly powerful in detecting UBS effects. The method consists of two modules--one is a pattern counting algorithm designed for efficiently evaluating the risk significance of each marker combination, and the other is a sequential permutation scheme for multiple testing correction. We demonstrate the work of our method using a candidate gene data set for cardiovascular and coronary diseases with an injected UBS three-locus interaction. In addition, we investigate the power and false rejection properties of our method using data sets simulated from a joint dominance three-locus model that gives rise to UBS interactive effects. The results show that our method can be much more powerful than standard approaches such as trend test and multifactor dimensionality reduction for detecting UBS interactions.
(c) 2010 Wiley-Liss, Inc.
Figures
References
-
- Assimes TL, Knowles JW, Basu A, Iribarren C, Southwick A, Tang H, Absher D, Li J, Fair JM, Rubin GD, Sidney S, Fortmann SP, Go AS, Hlatky MA, Myers RM, Risch N, Quertermous T. Susceptibility locus for clinical and subclinical coronary artery disease at chromosome 9p21 in the multi-ethnic ADVANCE study. Hum Mol Genet. 2008;17:2320–2328. - PMC - PubMed
-
- Borgelt C. Workshop Open Source Data Mining Software (OSDM'05) CM Press; New York, Illinois: 2005. An implementation of the fp-growth algorithm; pp. 1–5.
-
- Han J, Pei J, Yin Y, Mao R. Mining frequent patterns without candidate generation: a frequent-pattern tree approach. Data Min Knowl Discov. 2004;8:53–87.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
