

k-Nearest neighbor models for microarray gene expression analysis and clinical outcome prediction
- PMID: 20676068
- PMCID: PMC2920072
- DOI: 10.1038/tpj.2010.56
k-Nearest neighbor models for microarray gene expression analysis and clinical outcome prediction
Abstract
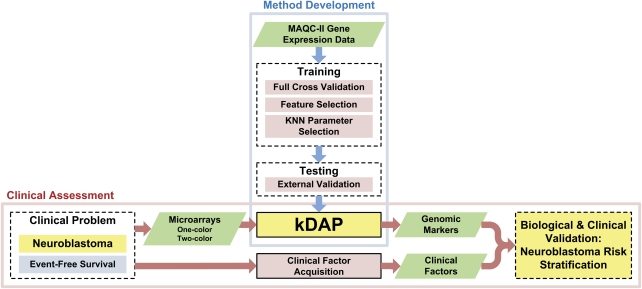
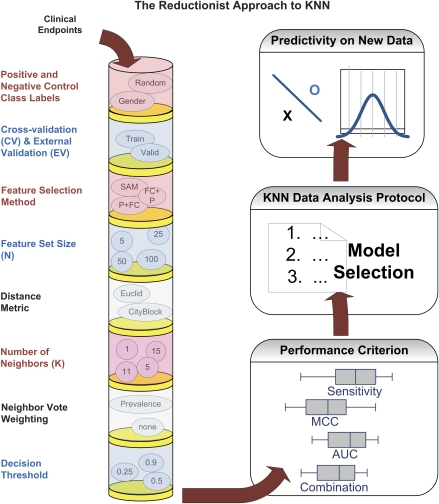
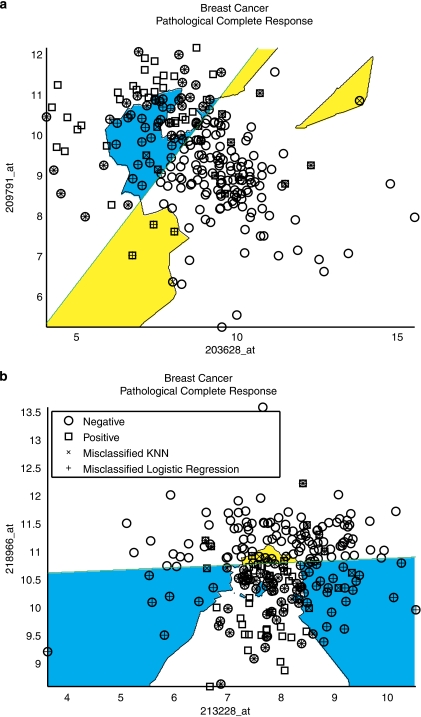
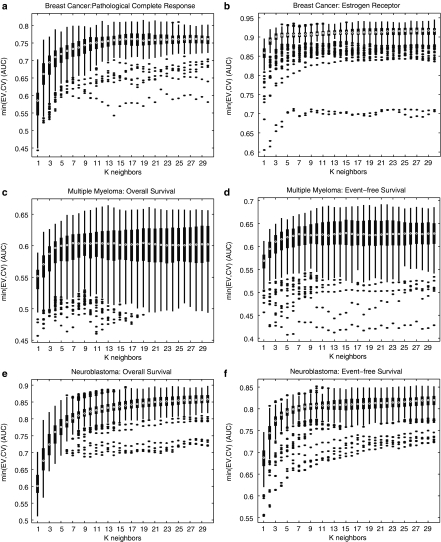
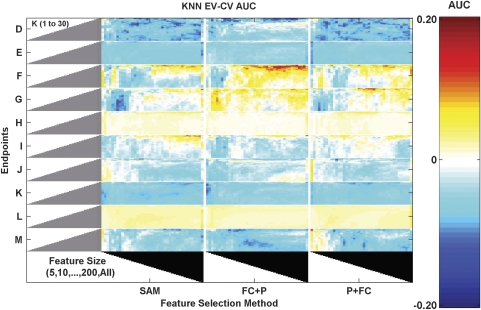
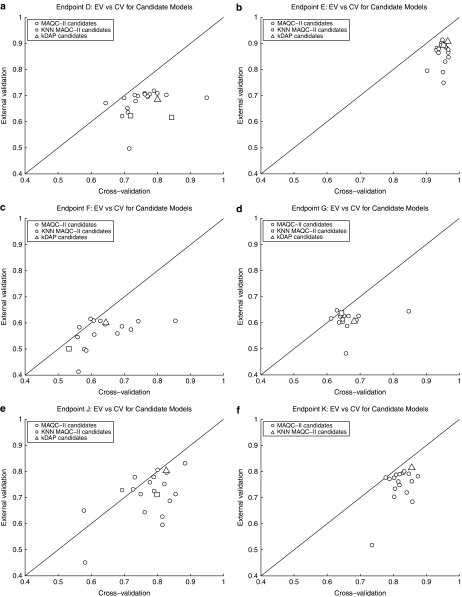
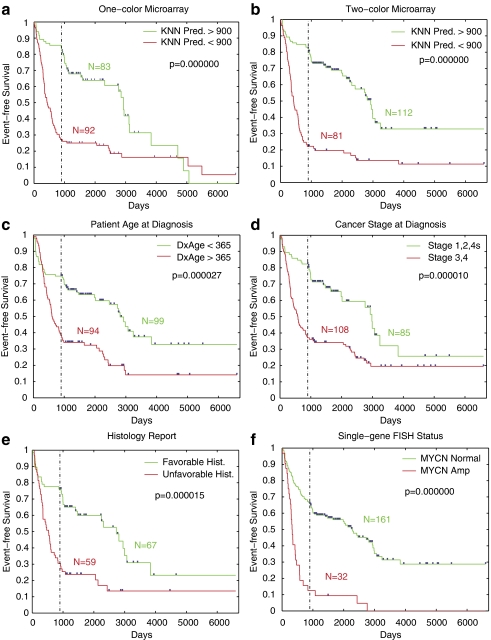
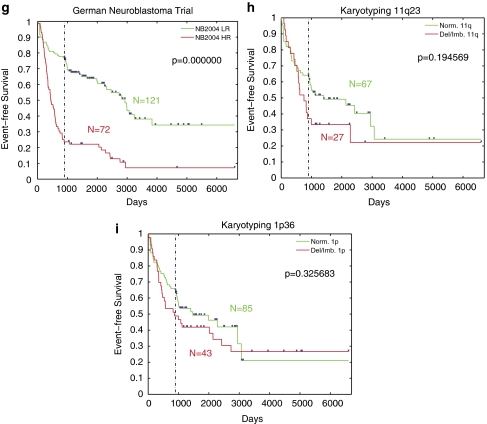
In the clinical application of genomic data analysis and modeling, a number of factors contribute to the performance of disease classification and clinical outcome prediction. This study focuses on the k-nearest neighbor (KNN) modeling strategy and its clinical use. Although KNN is simple and clinically appealing, large performance variations were found among experienced data analysis teams in the MicroArray Quality Control Phase II (MAQC-II) project. For clinical end points and controls from breast cancer, neuroblastoma and multiple myeloma, we systematically generated 463,320 KNN models by varying feature ranking method, number of features, distance metric, number of neighbors, vote weighting and decision threshold. We identified factors that contribute to the MAQC-II project performance variation, and validated a KNN data analysis protocol using a newly generated clinical data set with 478 neuroblastoma patients. We interpreted the biological and practical significance of the derived KNN models, and compared their performance with existing clinical factors.
Figures
References
-
- Gong Y, Yan K, Lin F, Anderson K, Sotiriou C, Andre F, et al. Determination of oestrogen-receptor status and ERBB2 status of breast carcinoma: a gene-expression profiling study. Lancet Oncol. 2007;8:203–211. - PubMed
-
- Shaughnessy JD, Jr, Zhan F, Burington BE, Huang Y, Colla S, Hanamura I, et al. A validated gene expression model of high-risk multiple myeloma is defined by deregulated expression of genes mapping to chromosome 1. Blood. 2007;109:2276–2284. - PubMed
-
- Oberthuer A, Berthold F, Warnat P, Hero B, Kahlert Y, Spitz R, et al. Customized oligonucleotide microarray gene expression-based classification of neuroblastoma patients outperforms current clinical risk stratification. J Clin Oncol. 2006;24:5070–5078. - PubMed
-
- Dudoit S, Fridlyand J, Speed TP. Comparison of discrimination methods for the classification of tumors using gene expression data. J Am Stat Assoc. 2002;97:77–87.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
