

Perception of speech in noise: neural correlates
- PMID: 20681749
- PMCID: PMC3253852
- DOI: 10.1162/jocn.2010.21556
Perception of speech in noise: neural correlates
Abstract
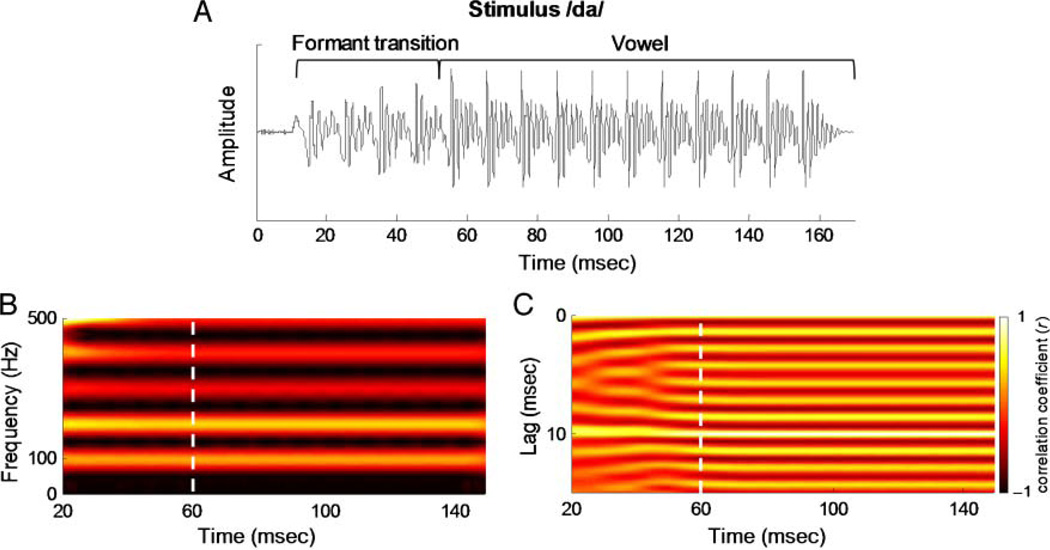
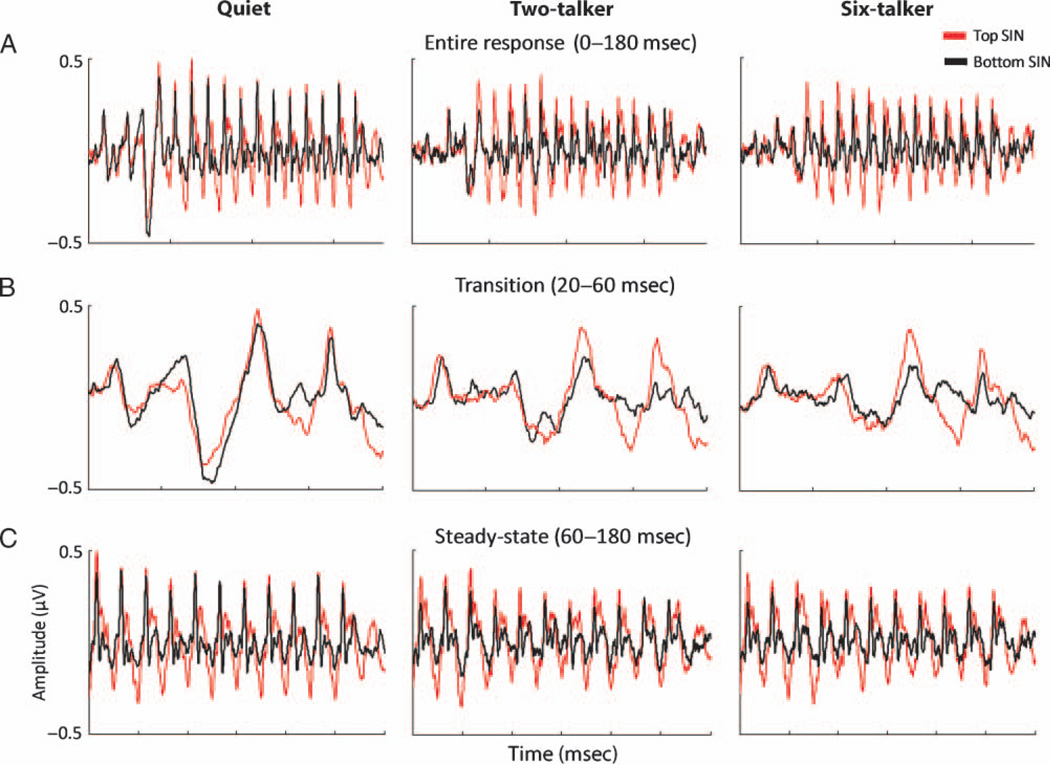
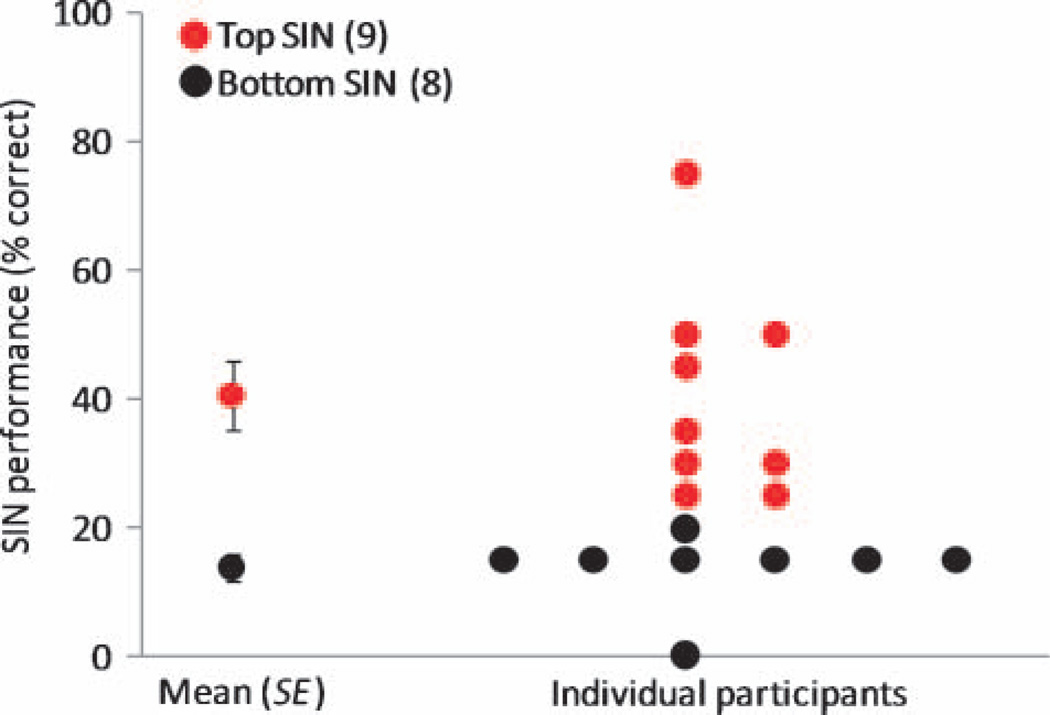
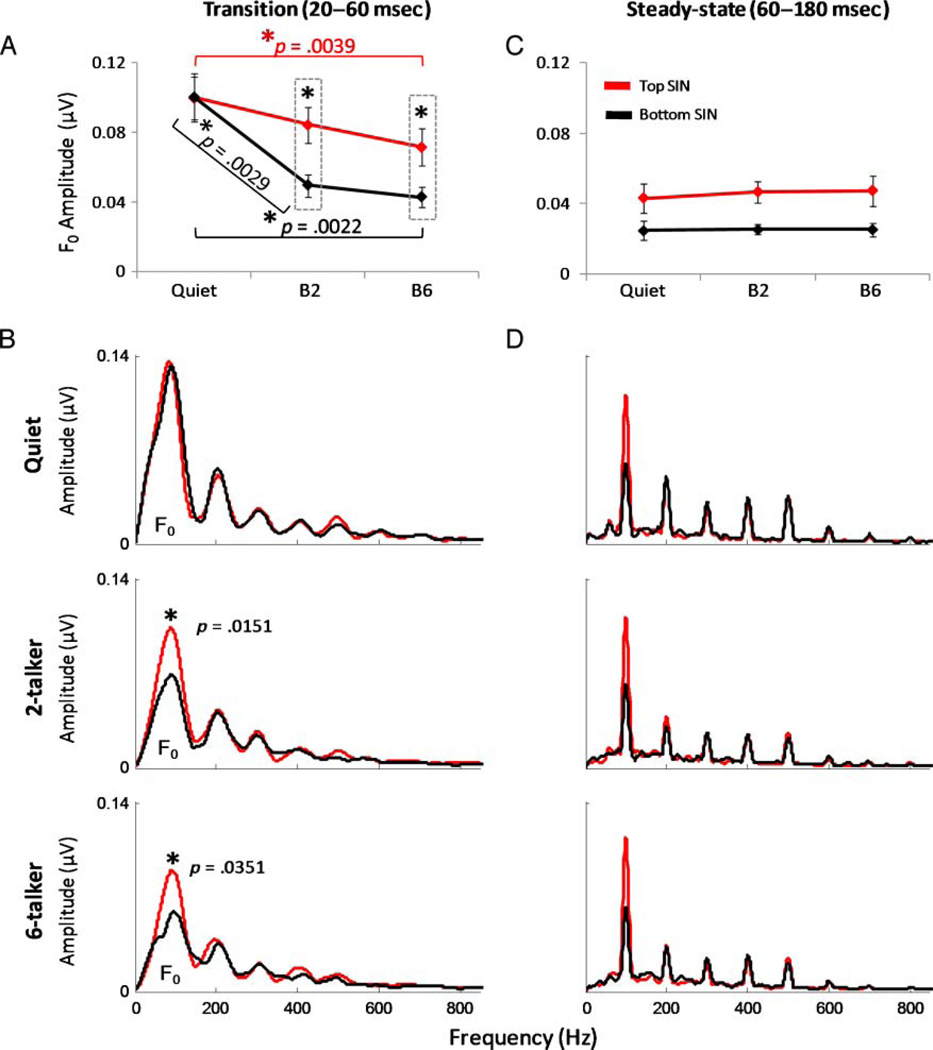
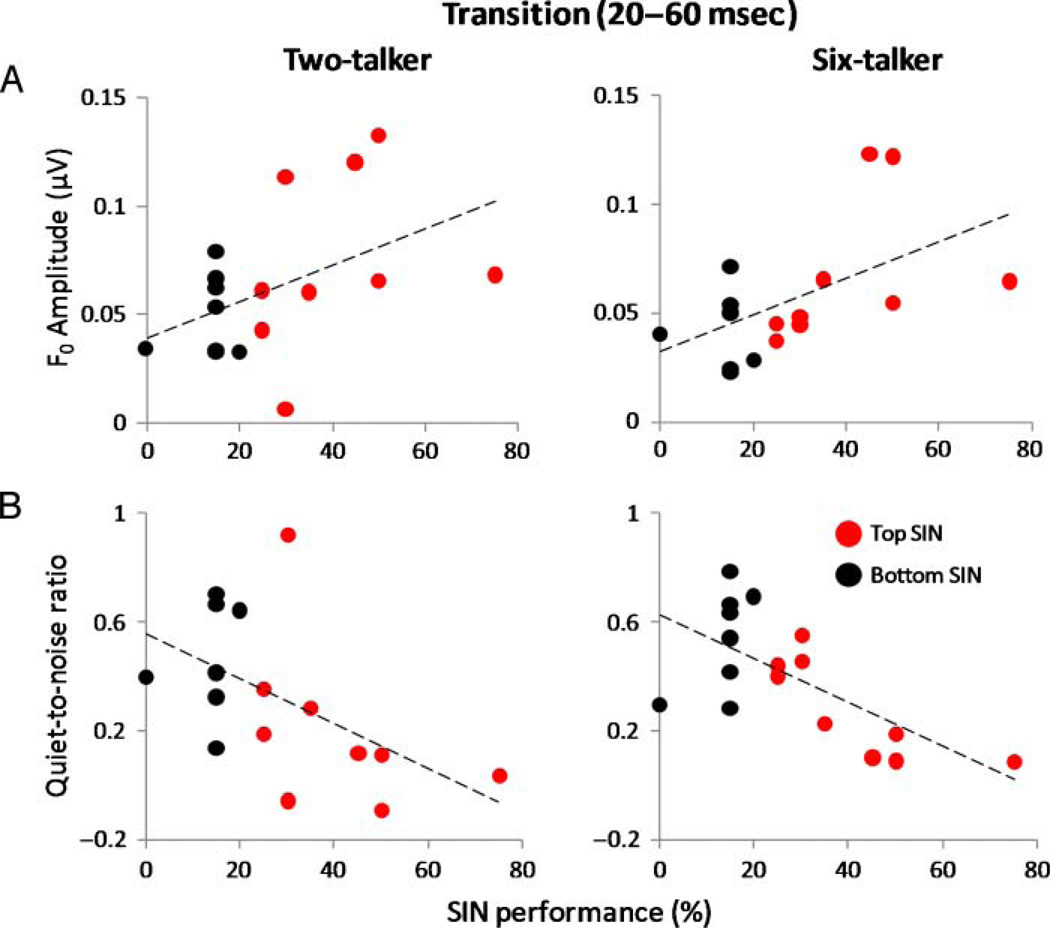
The presence of irrelevant auditory information (other talkers, environmental noises) presents a major challenge to listening to speech. The fundamental frequency (F(0)) of the target speaker is thought to provide an important cue for the extraction of the speaker's voice from background noise, but little is known about the relationship between speech-in-noise (SIN) perceptual ability and neural encoding of the F(0). Motivated by recent findings that music and language experience enhance brainstem representation of sound, we examined the hypothesis that brainstem encoding of the F(0) is diminished to a greater degree by background noise in people with poorer perceptual abilities in noise. To this end, we measured speech-evoked auditory brainstem responses to /da/ in quiet and two multitalker babble conditions (two-talker and six-talker) in native English-speaking young adults who ranged in their ability to perceive and recall SIN. Listeners who were poorer performers on a standardized SIN measure demonstrated greater susceptibility to the degradative effects of noise on the neural encoding of the F(0). Particularly diminished was their phase-locked activity to the fundamental frequency in the portion of the syllable known to be most vulnerable to perceptual disruption (i.e., the formant transition period). Our findings suggest that the subcortical representation of the F(0) in noise contributes to the perception of speech in noisy conditions.
Figures
References
-
- Ahissar M, Hochstein S. The reverse hierarchy theory of visual perceptual learning. Trends in Cognitive Sciences. 2004;8:457–464. - PubMed
-
- Aiken SJ, Picton TW. Envelope and spectral frequency-following responses to vowel sounds. Hearing Research. 2008;245:35–47. - PubMed
-
- Akhoun I, Gallégo S, Moulin A, Menard M, Veuillet E, Berger-Vachon C, et al. The temporal relationship between speech auditory brainstem responses and the acoustic pattern of the phoneme /ba/ in normal-hearing adults. Clinical Neurophysiology. 2008;119:922–933. - PubMed
-
- Amitay S. Forward and reverse hierarchies in auditory perceptual learning. Learning & Perception. 2009;1:59–68.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical