

Encoding and decoding in fMRI
- PMID: 20691790
- PMCID: PMC3037423
- DOI: 10.1016/j.neuroimage.2010.07.073
Encoding and decoding in fMRI
Abstract
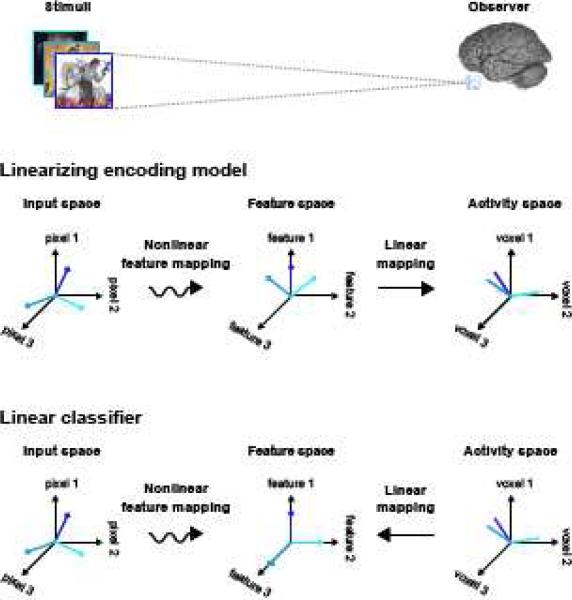
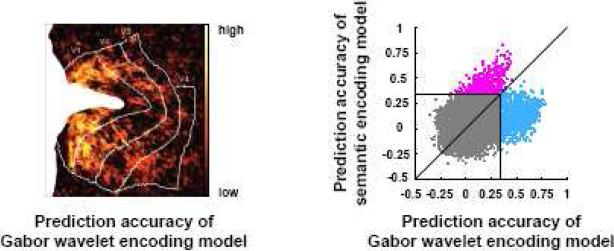
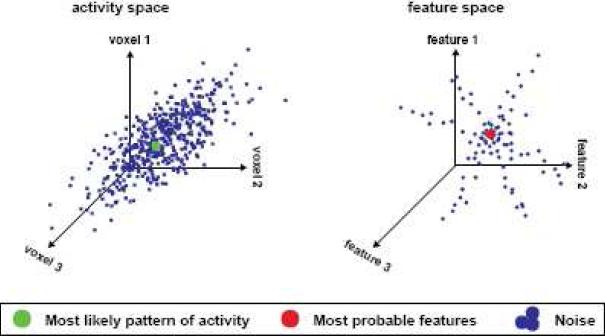
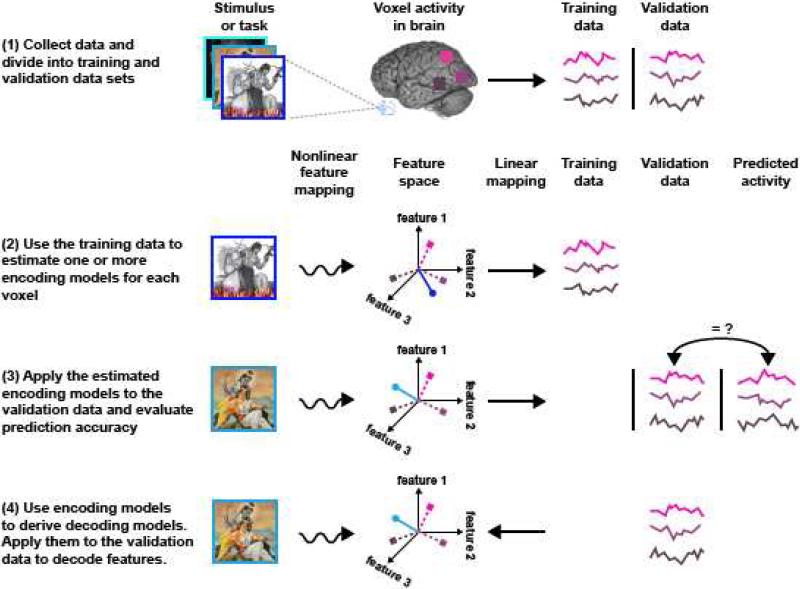
Over the past decade fMRI researchers have developed increasingly sensitive techniques for analyzing the information represented in BOLD activity. The most popular of these techniques is linear classification, a simple technique for decoding information about experimental stimuli or tasks from patterns of activity across an array of voxels. A more recent development is the voxel-based encoding model, which describes the information about the stimulus or task that is represented in the activity of single voxels. Encoding and decoding are complementary operations: encoding uses stimuli to predict activity while decoding uses activity to predict information about the stimuli. However, in practice these two operations are often confused, and their respective strengths and weaknesses have not been made clear. Here we use the concept of a linearizing feature space to clarify the relationship between encoding and decoding. We show that encoding and decoding operations can both be used to investigate some of the most common questions about how information is represented in the brain. However, focusing on encoding models offers two important advantages over decoding. First, an encoding model can in principle provide a complete functional description of a region of interest, while a decoding model can provide only a partial description. Second, while it is straightforward to derive an optimal decoding model from an encoding model it is much more difficult to derive an encoding model from a decoding model. We propose a systematic modeling approach that begins by estimating an encoding model for every voxel in a scan and ends by using the estimated encoding models to perform decoding.
Published by Elsevier Inc.
Figures
References
-
- Adelson EH, Bergen JR. Spatiotemporal energy models for the perception of motion. J. Opt. Soc. Am. A. 1985;2(2):284–299. - PubMed
-
- Aertsen A, Johannesma P. The spectro-temporal receptive field. A functional characteristic of auditory neurons. Biol. Cybern. 1981;42(2):133–143. - PubMed
-
- Bishop CM. Pattern recognition and machine learning. Springer; New York: 2006.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
