

Indicators of "healthy aging" in older women (65-69 years of age). A data-mining approach based on prediction of long-term survival
- PMID: 20716351
- PMCID: PMC2936300
- DOI: 10.1186/1471-2318-10-55
Indicators of "healthy aging" in older women (65-69 years of age). A data-mining approach based on prediction of long-term survival
Abstract
Background: Prediction of long-term survival in healthy adults requires recognition of features that serve as early indicators of successful aging. The aims of this study were to identify predictors of long-term survival in older women and to develop a multivariable model based upon longitudinal data from the Study of Osteoporotic Fractures (SOF).
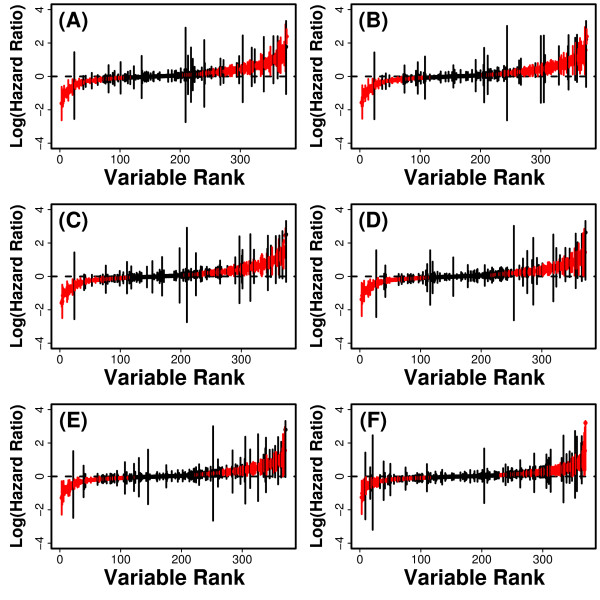
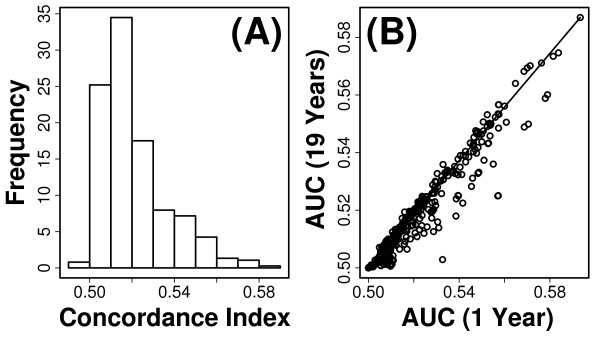
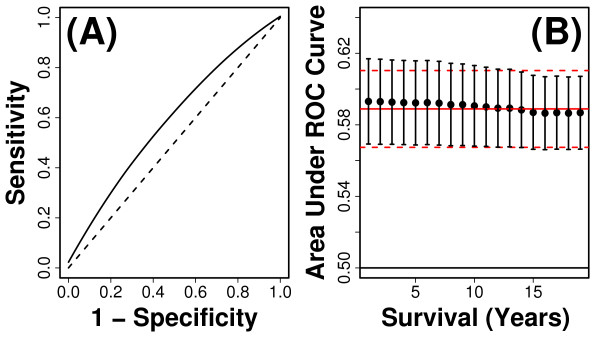
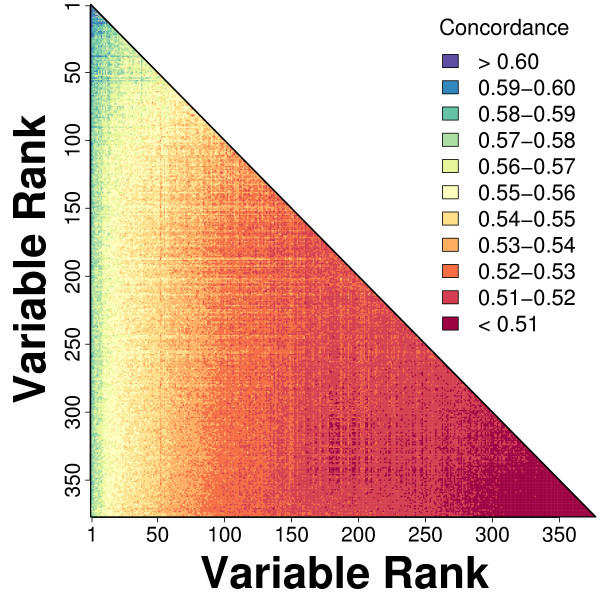
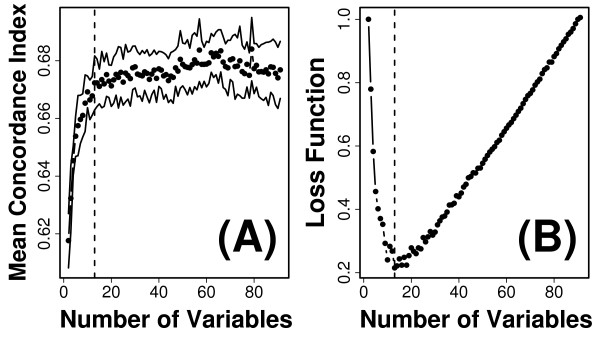
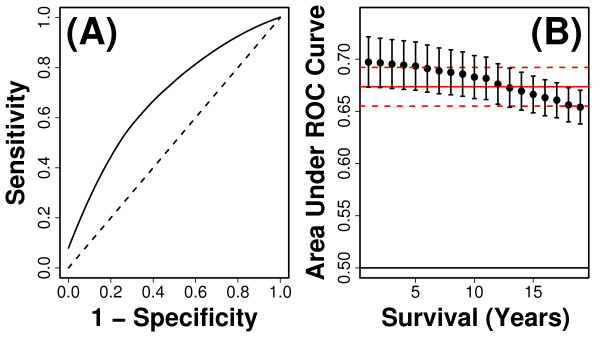
Methods: We considered only the youngest subjects (n = 4,097) enrolled in the SOF cohort (65 to 69 years of age) and excluded older SOF subjects more likely to exhibit a "frail" phenotype. A total of 377 phenotypic measures were screened to determine which were of most value for prediction of long-term (19-year) survival. Prognostic capacity of individual predictors, and combinations of predictors, was evaluated using a cross-validation criterion with prediction accuracy assessed according to time-specific AUC statistics.
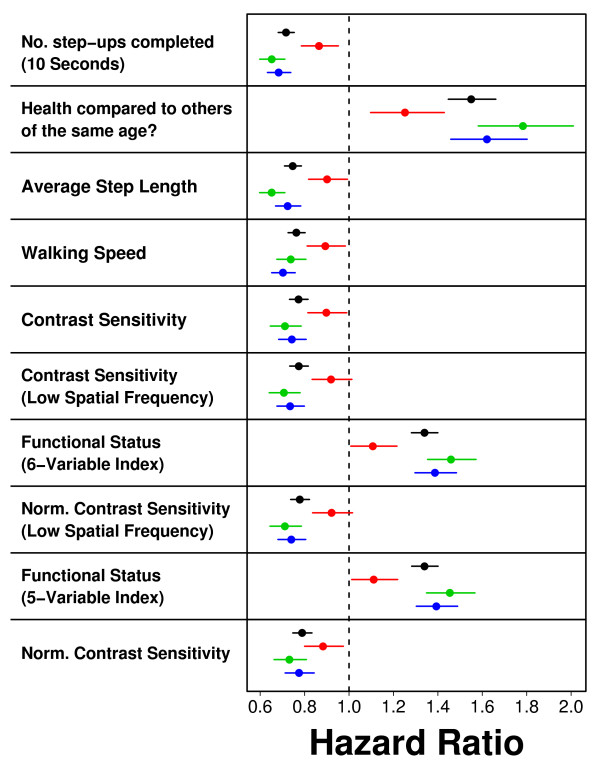
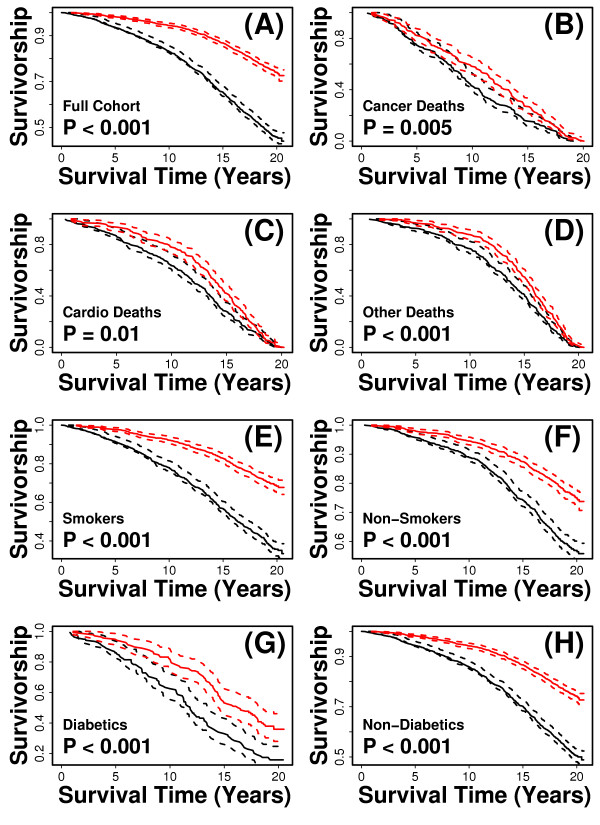
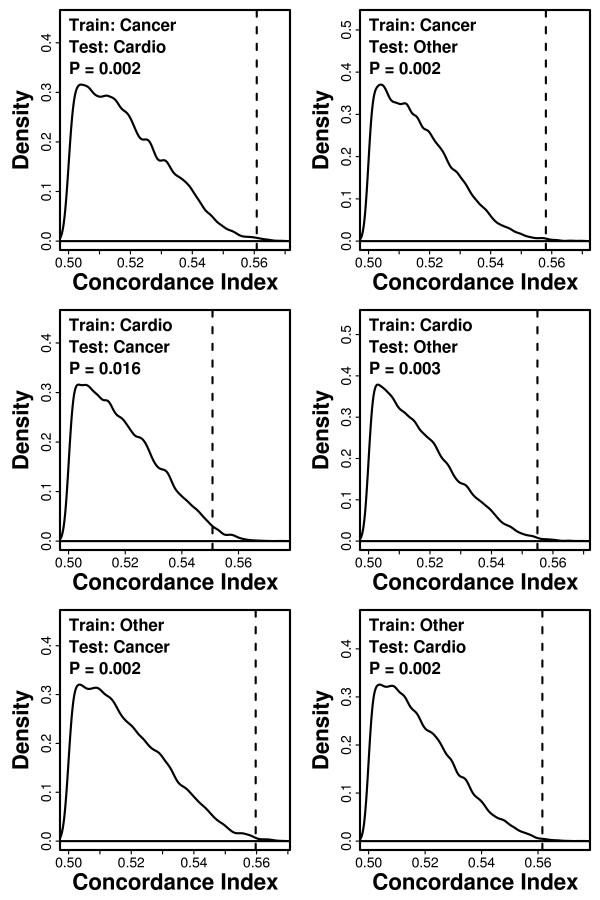
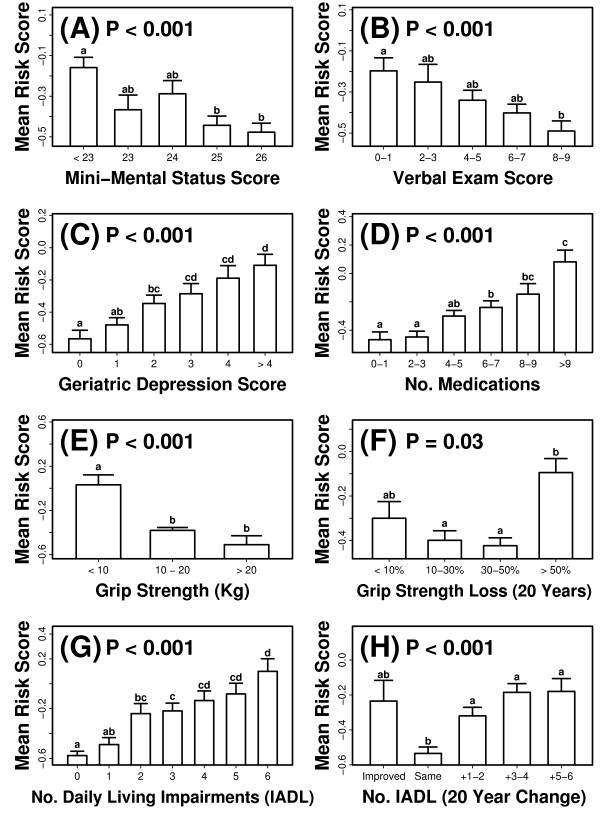
Results: Visual contrast sensitivity score was among the top 5 individual predictors relative to all 377 variables evaluated (mean AUC = 0.570). A 13-variable model with strong predictive performance was generated using a forward search strategy (mean AUC = 0.673). Variables within this model included a measure of physical function, smoking and diabetes status, self-reported health, contrast sensitivity, and functional status indices reflecting cumulative number of daily living impairments (HR >or= 0.879 or RH <or= 1.131; P < 0.001). We evaluated this model and show that it predicts long-term survival among subjects assigned differing causes of death (e.g., cancer, cardiovascular disease; P < 0.01). For an average follow-up time of 20 years, output from the model was associated with multiple outcomes among survivors, such as tests of cognitive function, geriatric depression, number of daily living impairments and grip strength (P < 0.03).
Conclusions: The multivariate model we developed characterizes a "healthy aging" phenotype based upon an integration of measures that together reflect multiple dimensions of an aging adult (65-69 years of age). Age-sensitive components of this model may be of value as biomarkers in human studies that evaluate anti-aging interventions. Our methodology could be applied to data from other longitudinal cohorts to generalize these findings, identify additional predictors of long-term survival, and to further develop the "healthy aging" concept.
Figures
Similar articles
-
Comparison of 2 frailty indexes for prediction of falls, disability, fractures, and death in older women.Arch Intern Med. 2008 Feb 25;168(4):382-9. doi: 10.1001/archinternmed.2007.113. Arch Intern Med. 2008. PMID: 18299493
-
Modifiable risk factors predict functional decline among older women: a prospectively validated clinical prediction tool. The Study of Osteoporotic Fractures Research Group.J Am Geriatr Soc. 2000 Feb;48(2):170-8. doi: 10.1111/j.1532-5415.2000.tb03908.x. J Am Geriatr Soc. 2000. PMID: 10682946
-
Global cardiovascular mortality risk in the adult Polish population: prospective assessment of the cohorts studied in multicentre national WOBASZ and WOBASZ Senior studies.Kardiol Pol. 2016;74(3):262-73. doi: 10.5603/KP.a2015.0175. Epub 2015 Sep 14. Kardiol Pol. 2016. PMID: 26365939
-
Effects of physical activity on health status in older adults. II. Intervention studies.Annu Rev Public Health. 1992;13:469-88. doi: 10.1146/annurev.pu.13.050192.002345. Annu Rev Public Health. 1992. PMID: 1599599 Review.
-
The ME-BYO index: A development and validation project of a novel comprehensive health index.Front Public Health. 2023 May 5;11:1142281. doi: 10.3389/fpubh.2023.1142281. eCollection 2023. Front Public Health. 2023. PMID: 37213649 Free PMC article. Review.
Cited by
-
ADAM33 gene polymorphisms and mortality. A prospective cohort study.PLoS One. 2013 Jul 4;8(7):e67768. doi: 10.1371/journal.pone.0067768. Print 2013. PLoS One. 2013. PMID: 23861802 Free PMC article.
-
Pilot study assessing the Rotterdam Healthy Aging Score in a cohort of HIV-positive adults in Toronto, Canada.AIDS. 2020 May 1;34(6):859-867. doi: 10.1097/QAD.0000000000002493. AIDS. 2020. PMID: 32271251 Free PMC article.
-
Association between vision impairment and mortality: a systematic review and meta-analysis.Lancet Glob Health. 2021 Apr;9(4):e418-e430. doi: 10.1016/S2214-109X(20)30549-0. Epub 2021 Feb 16. Lancet Glob Health. 2021. PMID: 33607015 Free PMC article.
-
Long-Chain Polyunsaturated Fatty Acids and Age-Related Macular Degeneration.Adv Exp Med Biol. 2019;1185:39-43. doi: 10.1007/978-3-030-27378-1_7. Adv Exp Med Biol. 2019. PMID: 31884586 Free PMC article. Review.
-
Mitochondrial Respiration in Outer Retina Contributes to Light-Evoked Increase in Hydration In Vivo.Invest Ophthalmol Vis Sci. 2018 Dec 3;59(15):5957-5964. doi: 10.1167/iovs.18-25682. Invest Ophthalmol Vis Sci. 2018. PMID: 30551203 Free PMC article.
References
-
- Nakasato YR, Carnes BA. Health promotion in older adults. Promoting successful aging in primary care settings. Geriatrics. 2006;61:27–31. - PubMed
-
- Butler RN, Sprott R, Warner H, Bland J, Feuers R, Forster M, Fillit H, Harman SM, Hewitt M, Hyman M, Johnson K, Kligman E, McClearn G, Nelson J, Richardson A, Sonntag W, Weindruch R, Wolf N. Biomarkers of aging: from primitive organisms to humans. J Gerontol A Biol Sci Med Sci. 2004;59:B560–7. - PubMed
Publication types
MeSH terms
Grants and funding
- 2R01 AG005394-22A1/AG/NIA NIH HHS/United States
- R01 AR035583/AR/NIAMS NIH HHS/United States
- AR35582/AR/NIAMS NIH HHS/United States
- AG05394/AG/NIA NIH HHS/United States
- R01 AG005407/AG/NIA NIH HHS/United States
- R01 AR035582/AR/NIAMS NIH HHS/United States
- AR35584/AR/NIAMS NIH HHS/United States
- T32-AG000114/AG/NIA NIH HHS/United States
- 2 R01 AG027574-22A/AG/NIA NIH HHS/United States
- U19 AG023122/AG/NIA NIH HHS/United States
- AG05407/AG/NIA NIH HHS/United States
- R01 AR035584/AR/NIAMS NIH HHS/United States
- AG023122/AG/NIA NIH HHS/United States
- R01 AG027576-22/AG/NIA NIH HHS/United States
- T32-AR007197/AR/NIAMS NIH HHS/United States
- AR35583/AR/NIAMS NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
