

Computational solutions to large-scale data management and analysis
- PMID: 20717155
- PMCID: PMC3124937
- DOI: 10.1038/nrg2857
Computational solutions to large-scale data management and analysis
Abstract
Today we can generate hundreds of gigabases of DNA and RNA sequencing data in a week for less than US$5,000. The astonishing rate of data generation by these low-cost, high-throughput technologies in genomics is being matched by that of other technologies, such as real-time imaging and mass spectrometry-based flow cytometry. Success in the life sciences will depend on our ability to properly interpret the large-scale, high-dimensional data sets that are generated by these technologies, which in turn requires us to adopt advances in informatics. Here we discuss how we can master the different types of computational environments that exist - such as cloud and heterogeneous computing - to successfully tackle our big data problems.
Figures
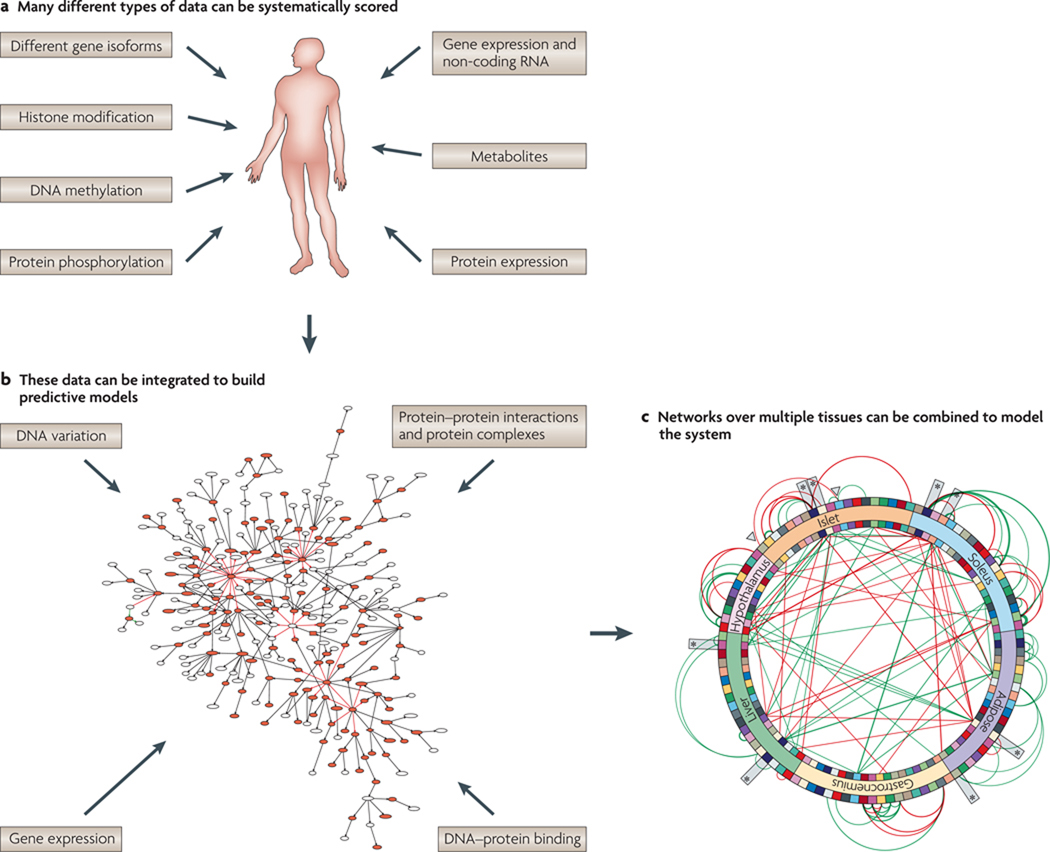
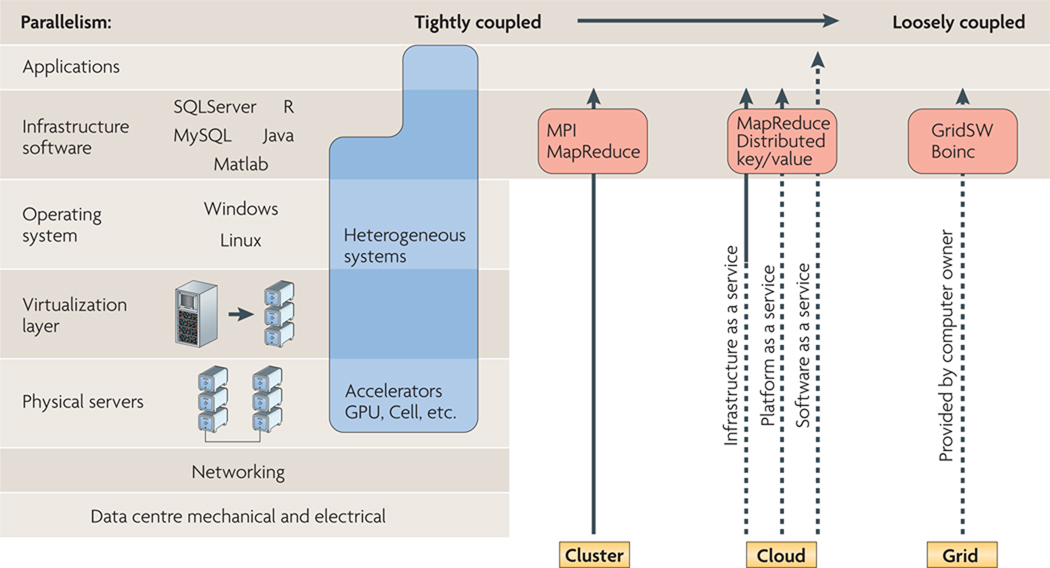
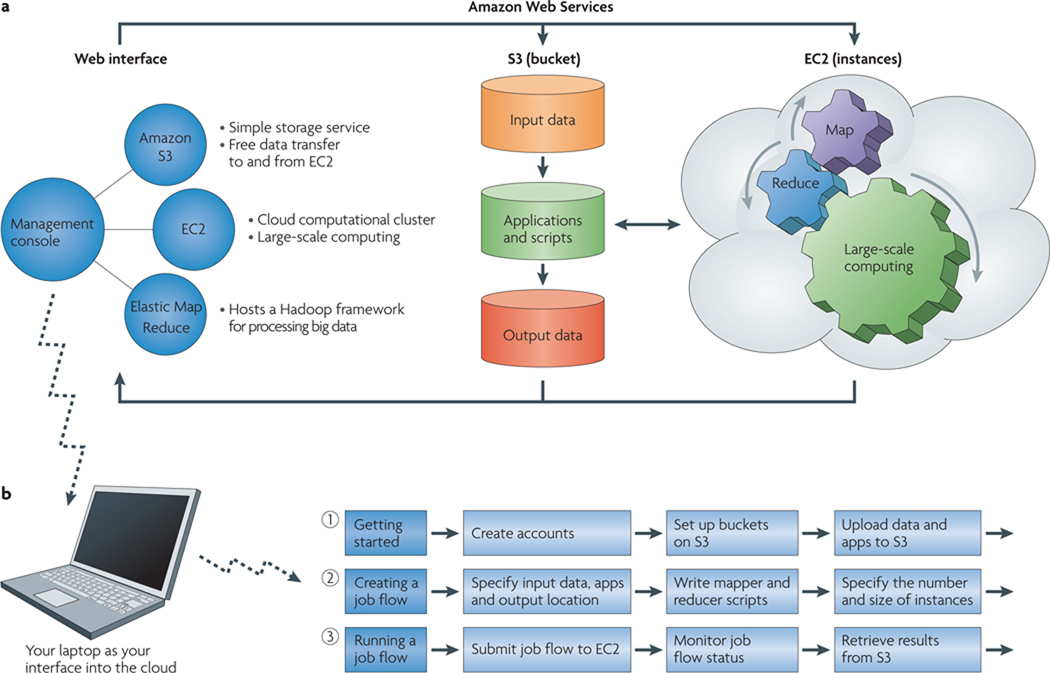
References
-
- Eid J, et al. Real-time DNA sequencing from single polymerase molecules. Science. 2009;323:133–138. - PubMed
-
- Bandura DR, et al. Mass cytometry: technique for real time single cell multitarget immunoassay based on inductively coupled plasma time-of-flight mass spectrometry. Anal. Chem. 2009;81:6813–6822. - PubMed
-
- Emilsson V, et al. Genetics of gene expression and its effect on disease. Nature. 2008;452:423–428. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
