

Using text to build semantic networks for pharmacogenomics
- PMID: 20723615
- PMCID: PMC2991587
- DOI: 10.1016/j.jbi.2010.08.005
Using text to build semantic networks for pharmacogenomics
Abstract
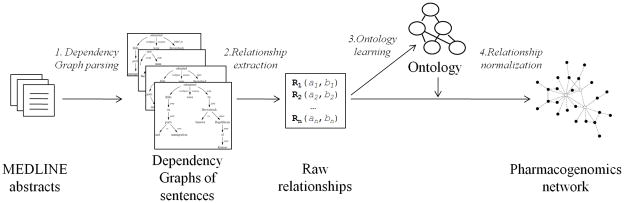
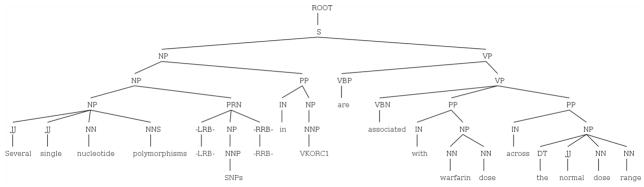
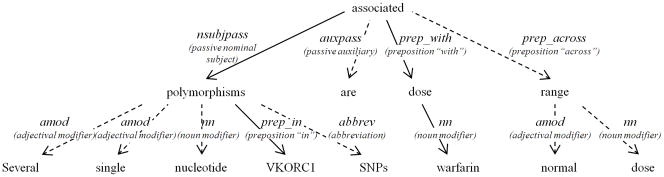
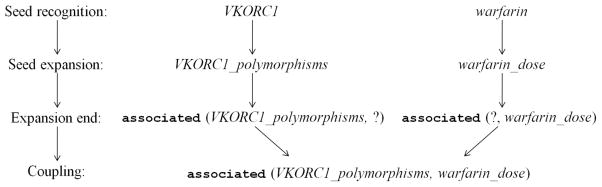
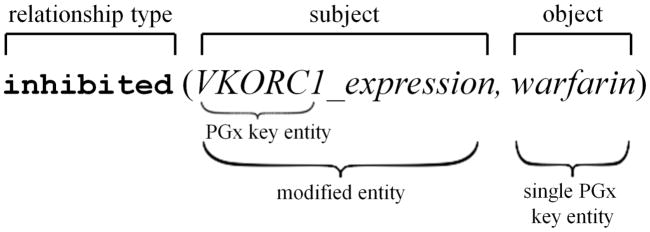
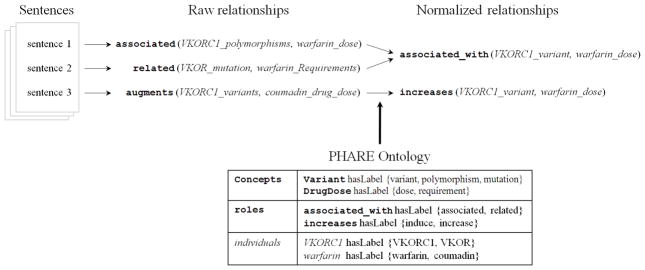
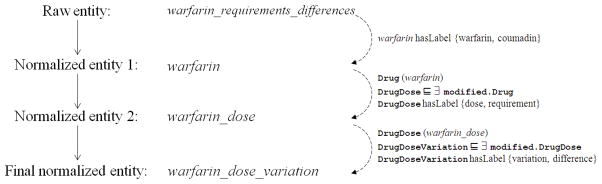
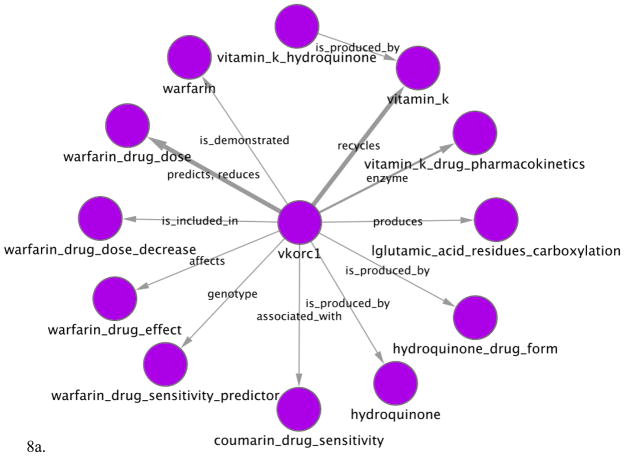
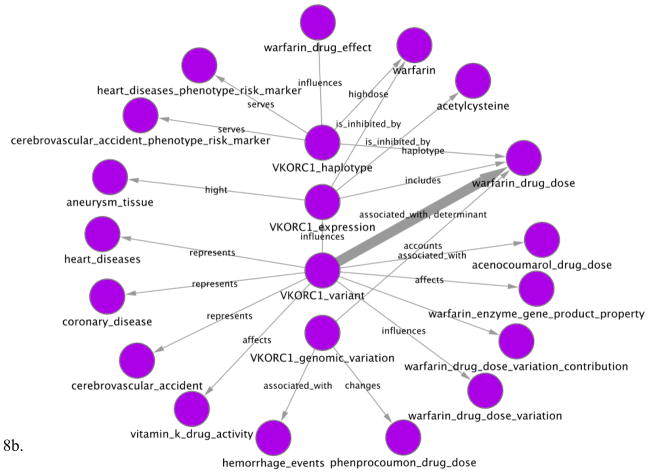
Most pharmacogenomics knowledge is contained in the text of published studies, and is thus not available for automated computation. Natural Language Processing (NLP) techniques for extracting relationships in specific domains often rely on hand-built rules and domain-specific ontologies to achieve good performance. In a new and evolving field such as pharmacogenomics (PGx), rules and ontologies may not be available. Recent progress in syntactic NLP parsing in the context of a large corpus of pharmacogenomics text provides new opportunities for automated relationship extraction. We describe an ontology of PGx relationships built starting from a lexicon of key pharmacogenomic entities and a syntactic parse of more than 87 million sentences from 17 million MEDLINE abstracts. We used the syntactic structure of PGx statements to systematically extract commonly occurring relationships and to map them to a common schema. Our extracted relationships have a 70-87.7% precision and involve not only key PGx entities such as genes, drugs, and phenotypes (e.g., VKORC1, warfarin, clotting disorder), but also critical entities that are frequently modified by these key entities (e.g., VKORC1 polymorphism, warfarin response, clotting disorder treatment). The result of our analysis is a network of 40,000 relationships between more than 200 entity types with clear semantics. This network is used to guide the curation of PGx knowledge and provide a computable resource for knowledge discovery.
Copyright © 2010 Elsevier Inc. All rights reserved.
Figures

References
-
- Klein T, Chang J, Cho M, Easton K, Fergerson R, Hewett M, Lin Z, Liu Y, Liu S, Oliver D, Rubin D, Shafa F, Stuart J, Altman R. Integrating genotype and phenotype information: An overview of the PharmGKB project. The Pharmacogenomics Journal. 1:167–170. - PubMed
-
- Blaschke C, Andrade MA, Ouzounis C, Valencia A. Automatic Extraction of Biological Information from Scientific Text: Protein–Protein Interactions. ISMB; 1999. pp. 60–67. - PubMed
-
- Rosario B, Hearst MA. Classifying semantic relations in bioscience texts. ACL; 2004. pp. 430–437.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
