

Reinforcement learning on slow features of high-dimensional input streams
- PMID: 20808883
- PMCID: PMC2924248
- DOI: 10.1371/journal.pcbi.1000894
Reinforcement learning on slow features of high-dimensional input streams
Abstract
Humans and animals are able to learn complex behaviors based on a massive stream of sensory information from different modalities. Early animal studies have identified learning mechanisms that are based on reward and punishment such that animals tend to avoid actions that lead to punishment whereas rewarded actions are reinforced. However, most algorithms for reward-based learning are only applicable if the dimensionality of the state-space is sufficiently small or its structure is sufficiently simple. Therefore, the question arises how the problem of learning on high-dimensional data is solved in the brain. In this article, we propose a biologically plausible generic two-stage learning system that can directly be applied to raw high-dimensional input streams. The system is composed of a hierarchical slow feature analysis (SFA) network for preprocessing and a simple neural network on top that is trained based on rewards. We demonstrate by computer simulations that this generic architecture is able to learn quite demanding reinforcement learning tasks on high-dimensional visual input streams in a time that is comparable to the time needed when an explicit highly informative low-dimensional state-space representation is given instead of the high-dimensional visual input. The learning speed of the proposed architecture in a task similar to the Morris water maze task is comparable to that found in experimental studies with rats. This study thus supports the hypothesis that slowness learning is one important unsupervised learning principle utilized in the brain to form efficient state representations for behavioral learning.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
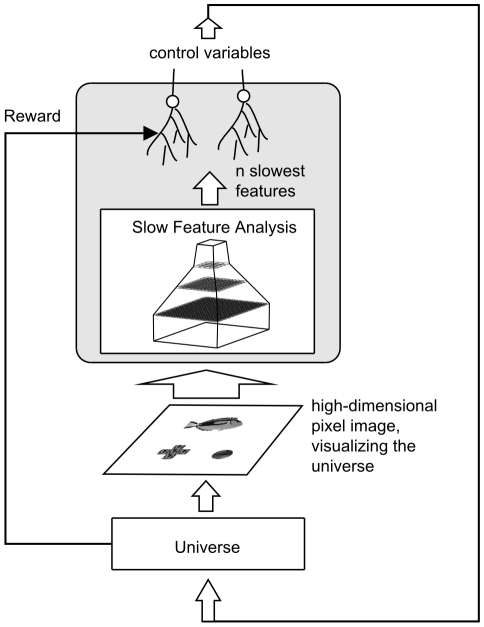
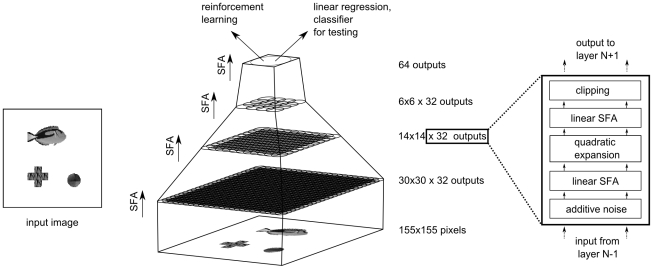
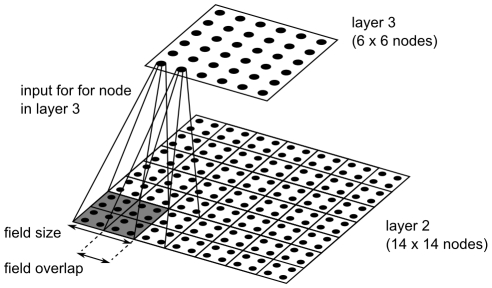
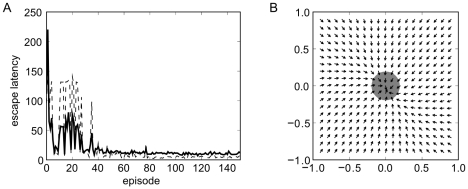
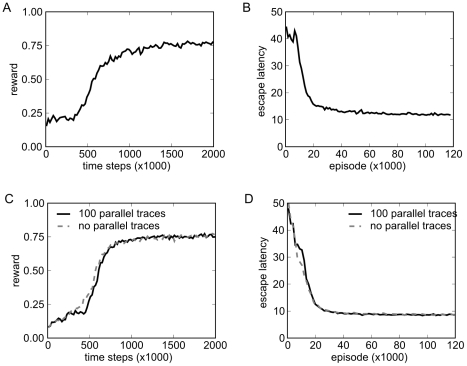
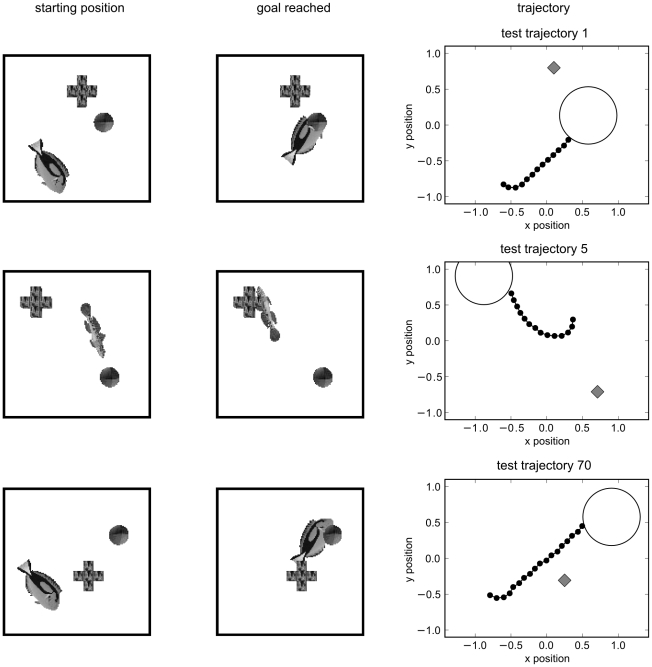
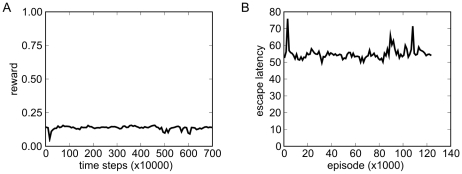
 155. A reward signal was made accessible to the control network for learning.
155. A reward signal was made accessible to the control network for learning.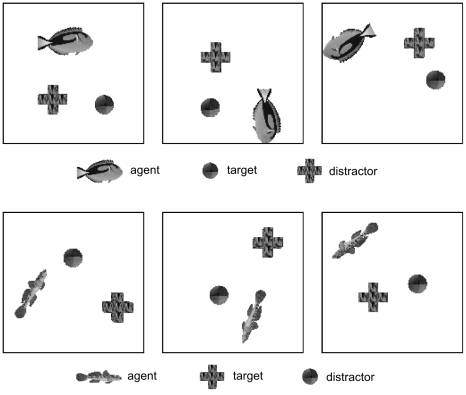
Similar articles
-
Recurrent neural networks that learn multi-step visual routines with reinforcement learning.PLoS Comput Biol. 2024 Apr 29;20(4):e1012030. doi: 10.1371/journal.pcbi.1012030. eCollection 2024 Apr. PLoS Comput Biol. 2024. PMID: 38683837 Free PMC article.
-
Reinforcement learning using a continuous time actor-critic framework with spiking neurons.PLoS Comput Biol. 2013 Apr;9(4):e1003024. doi: 10.1371/journal.pcbi.1003024. Epub 2013 Apr 11. PLoS Comput Biol. 2013. PMID: 23592970 Free PMC article.
-
Modular deep reinforcement learning from reward and punishment for robot navigation.Neural Netw. 2021 Mar;135:115-126. doi: 10.1016/j.neunet.2020.12.001. Epub 2020 Dec 8. Neural Netw. 2021. PMID: 33383526
-
Learning latent structure: carving nature at its joints.Curr Opin Neurobiol. 2010 Apr;20(2):251-6. doi: 10.1016/j.conb.2010.02.008. Epub 2010 Mar 11. Curr Opin Neurobiol. 2010. PMID: 20227271 Free PMC article. Review.
-
Reward-dependent learning in neuronal networks for planning and decision making.Prog Brain Res. 2000;126:217-29. doi: 10.1016/S0079-6123(00)26016-0. Prog Brain Res. 2000. PMID: 11105649 Review.
Cited by
-
Democratic population decisions result in robust policy-gradient learning: a parametric study with GPU simulations.PLoS One. 2011 May 4;6(5):e18539. doi: 10.1371/journal.pone.0018539. PLoS One. 2011. PMID: 21572529 Free PMC article.
-
Slow feature analysis on retinal waves leads to V1 complex cells.PLoS Comput Biol. 2014 May 8;10(5):e1003564. doi: 10.1371/journal.pcbi.1003564. eCollection 2014 May. PLoS Comput Biol. 2014. PMID: 24810948 Free PMC article.
-
An inductive bias for slowly changing features in human reinforcement learning.PLoS Comput Biol. 2024 Nov 25;20(11):e1012568. doi: 10.1371/journal.pcbi.1012568. eCollection 2024 Nov. PLoS Comput Biol. 2024. PMID: 39585903 Free PMC article.
-
View-invariance learning in object recognition by pigeons depends on error-driven associative learning processes.Vision Res. 2012 Jun 1;62:148-61. doi: 10.1016/j.visres.2012.04.004. Epub 2012 Apr 17. Vision Res. 2012. PMID: 22531015 Free PMC article.
-
Neuronal learning of invariant object representation in the ventral visual stream is not dependent on reward.J Neurosci. 2012 May 9;32(19):6611-20. doi: 10.1523/JNEUROSCI.3786-11.2012. J Neurosci. 2012. PMID: 22573683 Free PMC article.
References
-
- Thorndike E. Animal Intelligence. CT: Hafner, Darien; 1911.
-
- Bertsekas DP, Tsitsiklis J. Neuro-Dynamic Programming. Athena Scientific; 1996.
-
- Sutton RS, Barto AG. Reinforcement Learning: An Introduction. MIT Press; 1998.
-
- Schultz W, Dayan P, Montague P. A neural substrate of prediction and reward. Science. 1997;275:1593–9. - PubMed
-
- Reynolds JN, Wickens JR. Dopamine-dependent plasticity of corticostriatal synapses. Neural Netw. 2002;15:507–521. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
