

A framework for feature selection in clustering
- PMID: 20811510
- PMCID: PMC2930825
- DOI: 10.1198/jasa.2010.tm09415
A framework for feature selection in clustering
Abstract
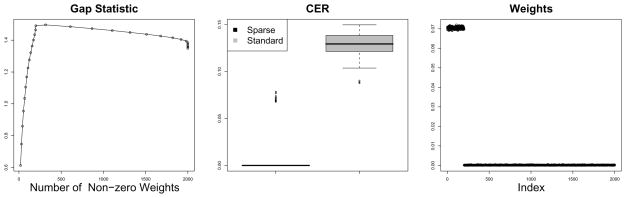
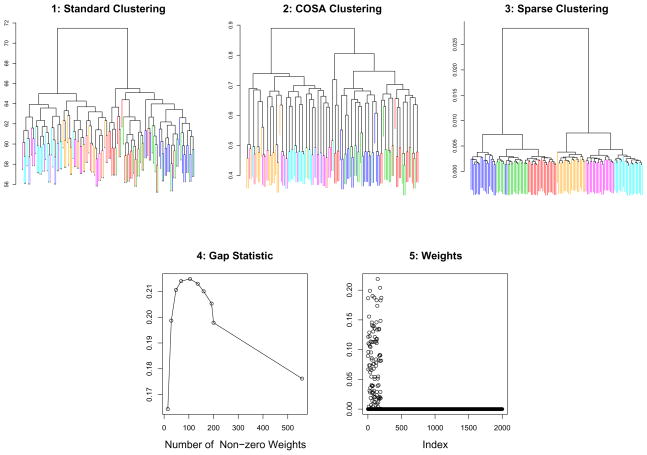
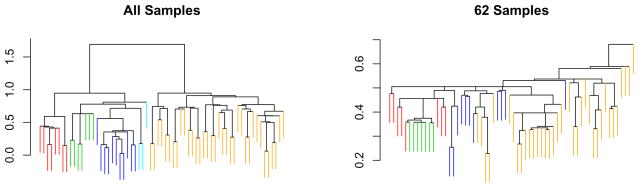
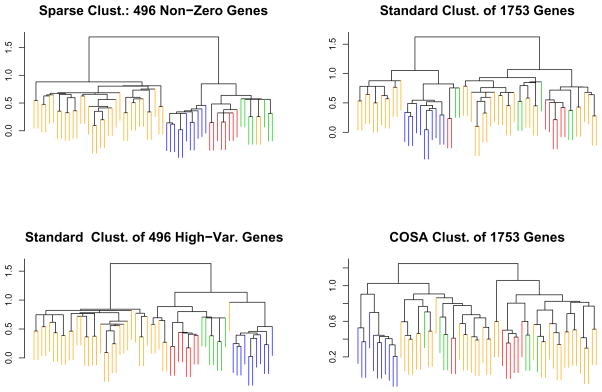
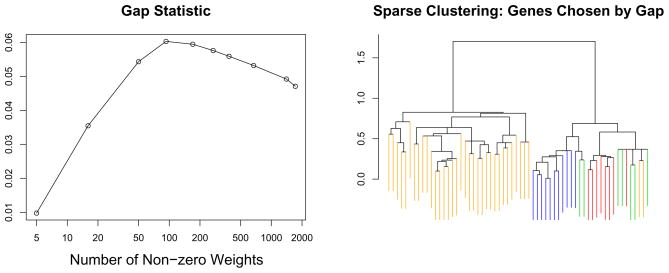
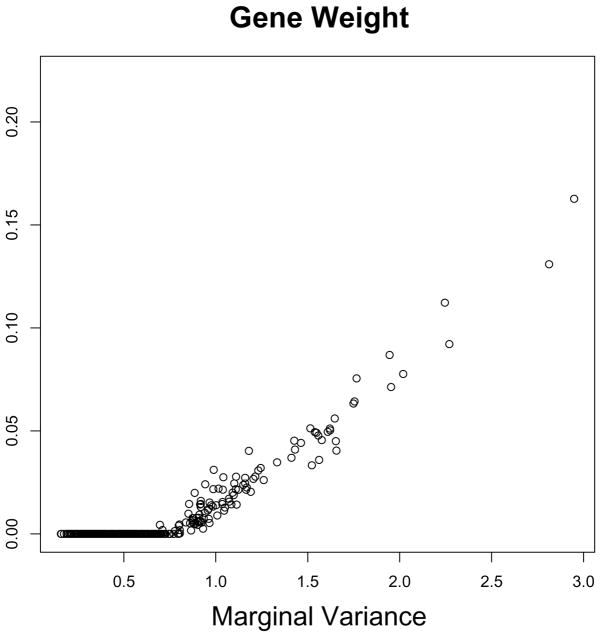
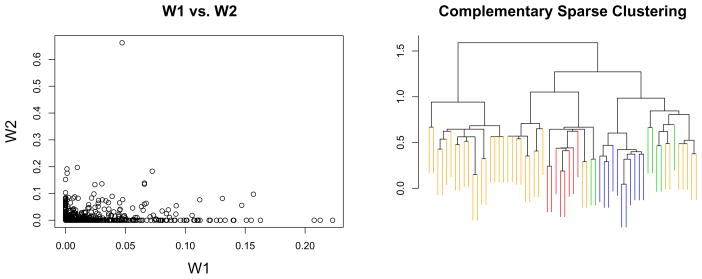
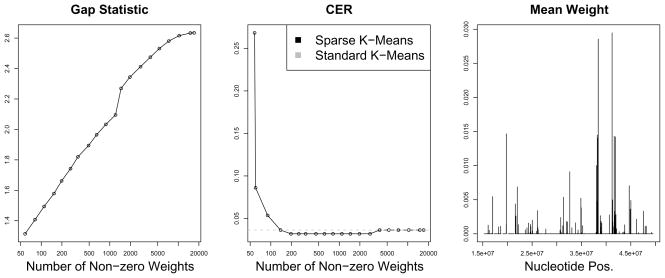
We consider the problem of clustering observations using a potentially large set of features. One might expect that the true underlying clusters present in the data differ only with respect to a small fraction of the features, and will be missed if one clusters the observations using the full set of features. We propose a novel framework for sparse clustering, in which one clusters the observations using an adaptively chosen subset of the features. The method uses a lasso-type penalty to select the features. We use this framework to develop simple methods for sparse K-means and sparse hierarchical clustering. A single criterion governs both the selection of the features and the resulting clusters. These approaches are demonstrated on simulated data and on genomic data sets.
Figures

References
-
- Boyd S, Vandenberghe L. Convex Optimization. Cambridge University Press; 2004.
-
- Chang W-C. On using principal components before separating a mixture of two multivariate normal distributions. Journal of the Royal Statistical Society, Series C (Applied Statistics) 1983;32:267–275.
-
- Chipman H, Tibshirani R. Hybrid hierarchical clustering with applications to microarray data. Biostatistics. 2005;7:286–301. - PubMed
-
- Dempster A, Laird N, Rubin D. Maximum likelihood from incomplete data via the EM algorithm (with discussion) J R Statist Soc B. 1977;39:1–38.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources